CogVLA: Cognition-Aligned Vision-Language-Action Model via Instruction-Driven Routing & Sparsification
作者: Wei Li, Renshan Zhang, Rui Shao, Jie He, Liqiang Nie
分类: cs.CV, cs.RO
发布日期: 2025-08-28 (更新: 2025-10-01)
备注: Accepted to NeurIPS 2025, Project Page: https://jiutian-vl.github.io/CogVLA-page
🔗 代码/项目: GITHUB
💡 一句话要点
CogVLA:通过指令驱动的路由和稀疏化实现认知对齐的视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 指令驱动 路由与稀疏化 机器人控制 多模态学习
📋 核心要点
- 现有VLA模型依赖大量后训练,计算开销大,限制了可扩展性和部署。
- CogVLA利用指令驱动的路由和稀疏化,模仿人类多模态协调,提升效率和性能。
- CogVLA在LIBERO和真实机器人任务上取得SOTA,训练成本降低2.5倍,推理延迟降低2.8倍。
📝 摘要(中文)
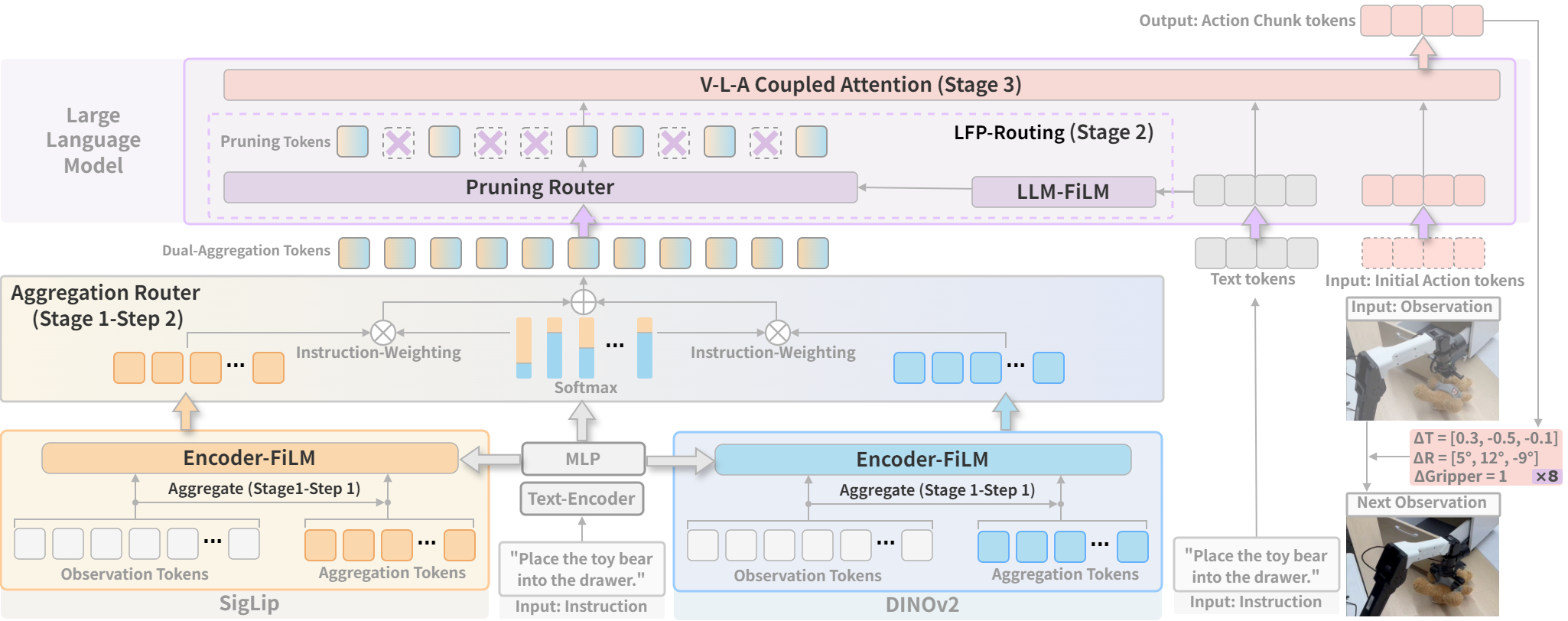
本文提出CogVLA,一个认知对齐的视觉-语言-动作框架,它利用指令驱动的路由和稀疏化来提高效率和性能。CogVLA从人类多模态协调中汲取灵感,并引入了一个三阶段渐进式架构。首先,基于Encoder-FiLM的聚合路由(EFA-Routing)将指令信息注入视觉编码器,以选择性地聚合和压缩双流视觉tokens,形成指令感知的潜在表示。其次,基于这种紧凑的视觉编码,基于LLM-FiLM的剪枝路由(LFP-Routing)通过剪枝指令不相关的视觉tokens,将动作意图引入语言模型,从而实现token级别的稀疏性。第三,为了确保压缩后的感知输入仍然可以支持准确和连贯的动作生成,引入了V-L-A耦合注意力(CAtten),它将因果视觉-语言注意力与双向动作并行解码相结合。在LIBERO基准测试和真实机器人任务上的大量实验表明,CogVLA实现了最先进的性能,成功率分别为97.4%和70.0%,同时与OpenVLA相比,训练成本降低了2.5倍,推理延迟降低了2.8倍。CogVLA已开源。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型依赖于预训练的视觉-语言模型(VLM),需要大量的后训练,导致计算开销过高,限制了模型的可扩展性和部署。这些模型通常无法有效地利用指令信息,导致冗余计算和次优性能。
核心思路:CogVLA的核心思路是模仿人类的多模态协调过程,通过指令驱动的路由和稀疏化,选择性地处理和压缩视觉信息,并将动作意图融入语言模型中,从而提高效率和性能。这种方法旨在减少不必要的计算,并专注于与当前指令相关的视觉信息。
技术框架:CogVLA采用三阶段渐进式架构:1) EFA-Routing:将指令信息注入视觉编码器,选择性地聚合和压缩视觉tokens。2) LFP-Routing:基于压缩后的视觉编码,剪枝指令不相关的视觉tokens,实现token级别的稀疏性。3) V-L-A Coupled Attention (CAtten):结合因果视觉-语言注意力与双向动作并行解码,确保压缩后的感知输入能够支持准确和连贯的动作生成。
关键创新:CogVLA的关键创新在于指令驱动的路由和稀疏化机制,以及V-L-A耦合注意力。EFA-Routing和LFP-Routing通过指令信息指导视觉信息的选择和压缩,减少了冗余计算。CAtten则通过耦合视觉、语言和动作信息,提高了动作生成的准确性和连贯性。与现有方法相比,CogVLA更加注重指令信息的利用,并采用稀疏化的方式提高效率。
关键设计:EFA-Routing和LFP-Routing都使用了FiLM (Feature-wise Linear Modulation) 层,将指令信息融入到视觉和语言模型中。EFA-Routing通过FiLM层调整视觉编码器的输出,LFP-Routing则通过FiLM层控制token的剪枝。CAtten结合了因果注意力和双向注意力,以更好地建模视觉、语言和动作之间的依赖关系。具体的参数设置和损失函数细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
CogVLA在LIBERO基准测试中取得了97.4%的成功率,在真实机器人任务中取得了70.0%的成功率,均达到了SOTA水平。同时,与OpenVLA相比,CogVLA的训练成本降低了2.5倍,推理延迟降低了2.8倍,表明其在效率和性能方面都具有显著优势。
🎯 应用场景
CogVLA具有广泛的应用前景,包括机器人控制、自动驾驶、智能助手等领域。它可以用于训练更高效、更智能的机器人,使其能够更好地理解人类指令并执行复杂的任务。此外,CogVLA还可以应用于虚拟现实和增强现实等领域,提供更自然、更流畅的人机交互体验。
📄 摘要(原文)
Recent Vision-Language-Action (VLA) models built on pre-trained Vision-Language Models (VLMs) require extensive post-training, resulting in high computational overhead that limits scalability and deployment.We propose CogVLA, a Cognition-Aligned Vision-Language-Action framework that leverages instruction-driven routing and sparsification to improve both efficiency and performance. CogVLA draws inspiration from human multimodal coordination and introduces a 3-stage progressive architecture. 1) Encoder-FiLM based Aggregation Routing (EFA-Routing) injects instruction information into the vision encoder to selectively aggregate and compress dual-stream visual tokens, forming a instruction-aware latent representation. 2) Building upon this compact visual encoding, LLM-FiLM based Pruning Routing (LFP-Routing) introduces action intent into the language model by pruning instruction-irrelevant visually grounded tokens, thereby achieving token-level sparsity. 3) To ensure that compressed perception inputs can still support accurate and coherent action generation, we introduce V-L-A Coupled Attention (CAtten), which combines causal vision-language attention with bidirectional action parallel decoding. Extensive experiments on the LIBERO benchmark and real-world robotic tasks demonstrate that CogVLA achieves state-of-the-art performance with success rates of 97.4% and 70.0%, respectively, while reducing training costs by 2.5-fold and decreasing inference latency by 2.8-fold compared to OpenVLA. CogVLA is open-sourced and publicly available at https://github.com/JiuTian-VL/CogVLA.