Dino U-Net: Exploiting High-Fidelity Dense Features from Foundation Models for Medical Image Segmentation
作者: Yifan Gao, Haoyue Li, Feng Yuan, Xiaosong Wang, Xin Gao
分类: cs.CV, eess.IV
发布日期: 2025-08-28
🔗 代码/项目: GITHUB
💡 一句话要点
Dino U-Net:利用DINOv3高保真密集特征提升医学图像分割精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像分割 DINOv3 视觉基础模型 自监督学习 编码器-解码器 保真度感知投影 迁移学习
📋 核心要点
- 现有医学图像分割方法难以有效迁移大规模自然图像数据集上预训练的基础模型的表示能力,尤其是在保持高精度方面。
- Dino U-Net通过冻结的DINOv3骨干网络提取高保真密集特征,并设计保真度感知投影模块(FAPM)来保持特征质量。
- 实验结果表明,Dino U-Net在多个医学图像分割数据集上取得了SOTA性能,且性能随模型规模增大而提升。
📝 摘要(中文)
本文提出Dino U-Net,一种新颖的编码器-解码器架构,旨在利用DINOv3视觉基础模型的高保真密集特征进行医学图像分割。该架构的编码器基于冻结的DINOv3骨干网络,并采用专门的适配器将模型的丰富语义特征与低层空间细节融合。为了在降维过程中保持这些表示的质量,设计了一种新的保真度感知投影模块(FAPM),有效地细化和投影特征以供解码器使用。在七个不同的公共医学图像分割数据集上进行了广泛的实验。结果表明,Dino U-Net实现了最先进的性能,在各种成像模式下始终优于以前的方法。该框架具有高度可扩展性,分割精度随着骨干模型尺寸的增加(高达70亿参数的变体)而持续提高。研究结果表明,利用通用基础模型中卓越的、密集预训练特征,为提高医学图像分割的准确性提供了一种高效且参数高效的方法。
🔬 方法详解
问题定义:医学图像分割任务面临的挑战是如何有效利用在大规模自然图像数据集上预训练的视觉基础模型所学习到的知识,并将其迁移到医学图像领域。现有方法通常难以在保持高精度的同时,充分利用这些预训练模型的强大表示能力。尤其是在处理医学图像的特殊结构和纹理时,直接应用通用视觉模型可能会导致性能下降。
核心思路:Dino U-Net的核心思路是利用DINOv3视觉基础模型提取的高保真密集特征,并设计专门的模块来保持和利用这些特征在医学图像分割中的有效性。通过冻结DINOv3的骨干网络,可以避免在医学图像数据集上进行微调,从而节省计算资源并防止过拟合。同时,通过适配器和保真度感知投影模块,可以有效地融合语义信息和空间细节,从而提高分割精度。
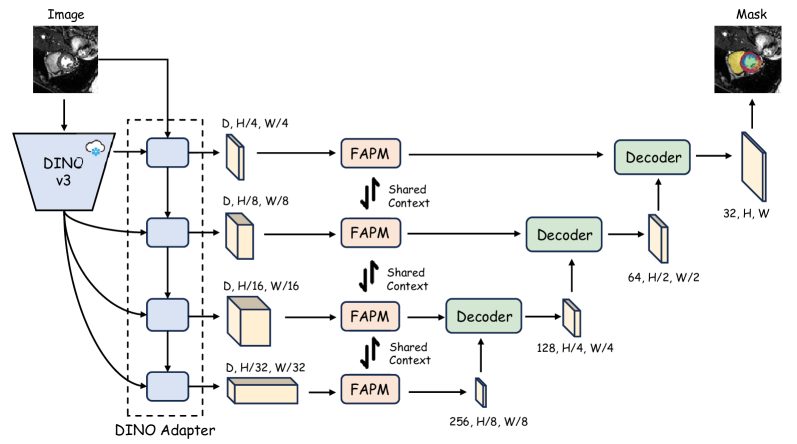
技术框架:Dino U-Net采用编码器-解码器架构。编码器部分基于冻结的DINOv3骨干网络,用于提取图像特征。适配器模块用于融合DINOv3提取的语义特征与低层空间细节。保真度感知投影模块(FAPM)用于细化和投影特征,以供解码器使用。解码器部分负责将投影后的特征映射到分割结果。
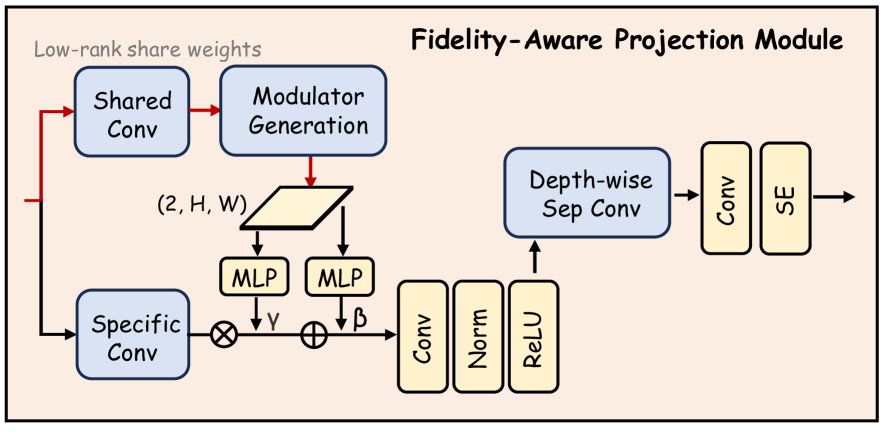
关键创新:Dino U-Net的关键创新在于保真度感知投影模块(FAPM)。FAPM旨在在降维过程中保持特征的质量,避免信息损失。它通过自适应地调整特征的权重,从而更好地保留重要的空间细节和语义信息。这种设计使得Dino U-Net能够更有效地利用DINOv3预训练模型的知识,从而提高分割精度。
关键设计:Dino U-Net的关键设计包括:1) 冻结DINOv3骨干网络,避免微调;2) 适配器模块,用于融合语义和空间信息;3) 保真度感知投影模块(FAPM),用于保持特征质量。具体的参数设置和损失函数等技术细节在论文中进行了详细描述,但摘要中未提及。
🖼️ 关键图片
📊 实验亮点
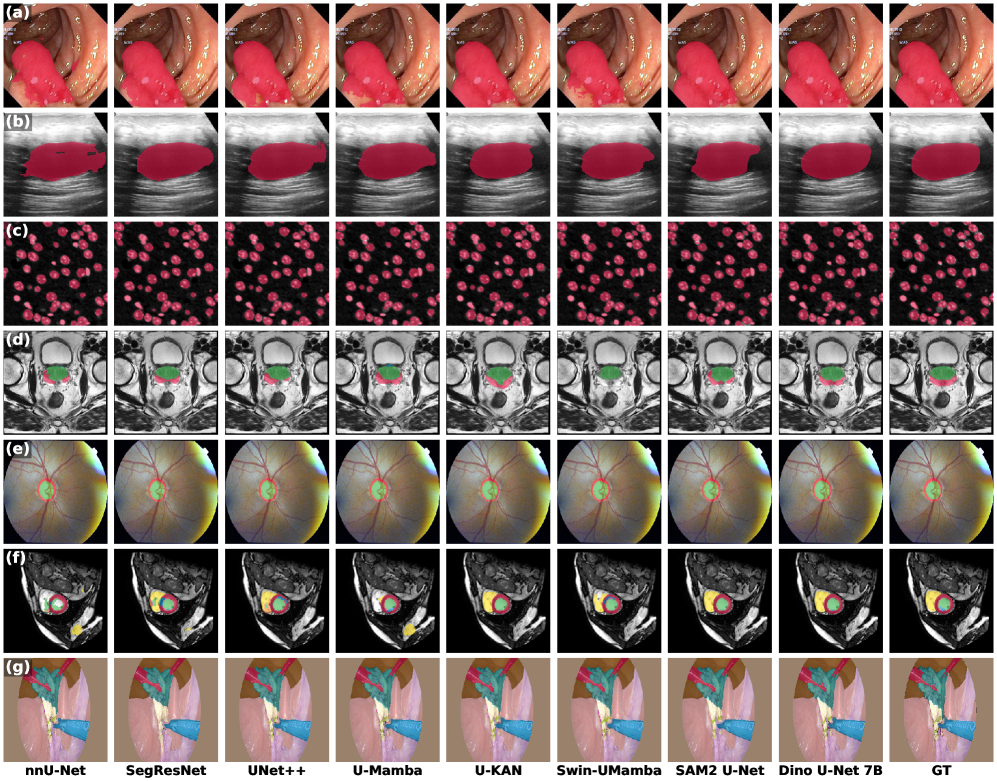
Dino U-Net在七个不同的公共医学图像分割数据集上进行了实验,结果表明其性能优于现有方法,实现了SOTA。实验结果还表明,Dino U-Net具有高度可扩展性,分割精度随着骨干模型尺寸的增加而持续提高,即使使用70亿参数的DINOv3变体也能获得性能提升。这表明Dino U-Net能够有效利用大规模预训练模型的知识。
🎯 应用场景
Dino U-Net在医学图像分割领域具有广泛的应用前景,例如肿瘤检测、器官分割、病灶识别等。该研究成果可以提高医学图像分析的准确性和效率,辅助医生进行诊断和治疗,并有望应用于计算机辅助诊断系统和医学影像分析平台。未来,该方法可以扩展到其他医学影像模态和疾病类型,为精准医疗提供更强大的技术支持。
📄 摘要(原文)
Foundation models pre-trained on large-scale natural image datasets offer a powerful paradigm for medical image segmentation. However, effectively transferring their learned representations for precise clinical applications remains a challenge. In this work, we propose Dino U-Net, a novel encoder-decoder architecture designed to exploit the high-fidelity dense features of the DINOv3 vision foundation model. Our architecture introduces an encoder built upon a frozen DINOv3 backbone, which employs a specialized adapter to fuse the model's rich semantic features with low-level spatial details. To preserve the quality of these representations during dimensionality reduction, we design a new fidelity-aware projection module (FAPM) that effectively refines and projects the features for the decoder. We conducted extensive experiments on seven diverse public medical image segmentation datasets. Our results show that Dino U-Net achieves state-of-the-art performance, consistently outperforming previous methods across various imaging modalities. Our framework proves to be highly scalable, with segmentation accuracy consistently improving as the backbone model size increases up to the 7-billion-parameter variant. The findings demonstrate that leveraging the superior, dense-pretrained features from a general-purpose foundation model provides a highly effective and parameter-efficient approach to advance the accuracy of medical image segmentation. The code is available at https://github.com/yifangao112/DinoUNet.