"Humor, Art, or Misinformation?": A Multimodal Dataset for Intent-Aware Synthetic Image Detection
作者: Anastasios Skoularikis, Stefanos-Iordanis Papadopoulos, Symeon Papadopoulos, Panagiotis C. Petrantonakis
分类: cs.CV, cs.MM
发布日期: 2025-08-28 (更新: 2025-09-09)
💡 一句话要点
提出S-HArM数据集,用于意图感知的合成图像检测,解决现有方法忽略图像生成意图的问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成图像检测 意图感知 多模态学习 数据集构建 Stable Diffusion
📋 核心要点
- 现有合成图像检测方法忽略了图像生成背后的意图,导致模型在实际应用中效果不佳。
- 本文构建了S-HArM数据集,并探索多种提示策略生成合成数据,以训练意图感知的分类模型。
- 实验表明,图像引导和多模态引导的合成数据能提升模型在真实场景下的泛化能力,但整体性能仍有提升空间。
📝 摘要(中文)
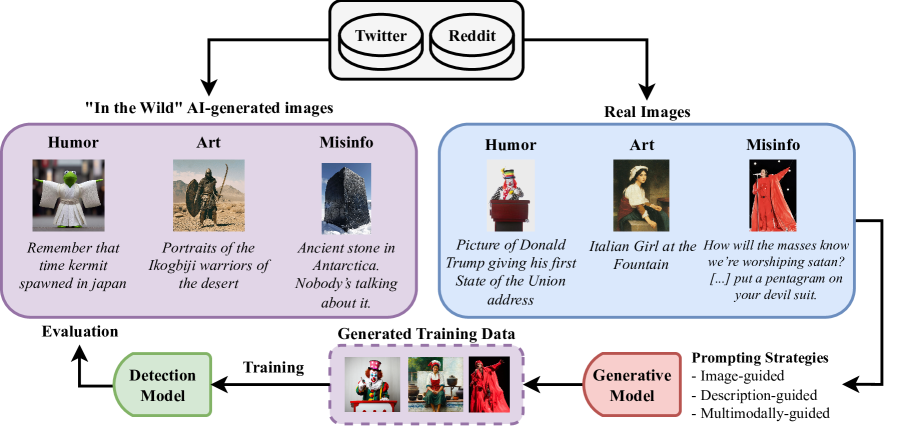
本文提出了S-HArM数据集,一个用于意图感知分类的多模态数据集,包含来自Twitter/X和Reddit的9,576个“野外”图像-文本对,并标注为幽默/讽刺、艺术或虚假信息。此外,本文还探索了三种提示策略(图像引导、描述引导和多模态引导),以使用Stable Diffusion构建大规模合成训练数据集。本文进行了一项广泛的比较研究,包括模态融合、对比学习、重建网络、注意力机制和大型视觉-语言模型。结果表明,在图像引导和多模态引导数据上训练的模型能够更好地泛化到“野外”内容,这是由于保留了视觉上下文。然而,总体性能仍然有限,突出了推断意图的复杂性以及对专用架构的需求。
🔬 方法详解
问题定义:现有合成图像检测方法主要关注图像本身是否为伪造,而忽略了图像生成者的意图。例如,一张AI生成的图像可能是为了幽默、艺术创作,也可能是为了传播虚假信息。现有方法无法区分这些意图,导致在实际应用中,尤其是在社交媒体等场景下,检测效果不佳。
核心思路:本文的核心思路是构建一个包含图像及其对应文本描述的数据集,并标注图像的生成意图(幽默/讽刺、艺术、虚假信息)。然后,利用这个数据集训练一个多模态模型,使其能够同时理解图像和文本信息,从而推断出图像的生成意图。通过引入意图信息,模型可以更准确地判断图像的真实性和潜在危害。
技术框架:整体框架包括数据收集与标注、合成数据生成、模型训练与评估三个主要阶段。首先,从Twitter/X和Reddit等社交媒体平台收集图像-文本对,并人工标注图像的意图。然后,利用Stable Diffusion等生成模型,通过不同的提示策略(图像引导、描述引导、多模态引导)生成大规模的合成数据。最后,使用真实数据和合成数据混合训练多模态模型,并评估其在真实数据上的性能。
关键创新:本文的关键创新在于提出了一个意图感知的合成图像检测框架,并构建了相应的多模态数据集S-HArM。与以往的研究只关注图像本身不同,本文强调了图像生成意图的重要性,并将其纳入到模型的训练过程中。此外,本文还探索了不同的提示策略,以生成更符合真实场景的合成数据。
关键设计:在合成数据生成方面,本文探索了三种提示策略:图像引导(仅使用图像作为提示)、描述引导(仅使用文本描述作为提示)和多模态引导(同时使用图像和文本描述作为提示)。在模型训练方面,本文尝试了多种模型架构,包括模态融合、对比学习、重建网络、注意力机制和大型视觉-语言模型。损失函数方面,可能使用了交叉熵损失函数进行分类任务,并可能结合对比损失或重建损失来提升模型的表示学习能力。具体的网络结构细节和参数设置在论文中应该有更详细的描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用图像引导和多模态引导策略生成的合成数据训练的模型,在真实世界的“野外”数据上表现出更好的泛化能力。这表明保留视觉上下文对于意图感知至关重要。然而,总体性能仍然有限,表明意图推断的复杂性,需要更专业的模型架构。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,帮助识别和过滤虚假信息、仇恨言论等有害内容。此外,该技术还可以用于版权保护,检测未经授权的AI生成艺术作品。未来,该研究有望推动AI生成内容监管和伦理规范的制定。
📄 摘要(原文)
Recent advances in multimodal AI have enabled progress in detecting synthetic and out-of-context content. However, existing efforts largely overlook the intent behind AI-generated images. To fill this gap, we introduce S-HArM, a multimodal dataset for intent-aware classification, comprising 9,576 "in the wild" image-text pairs from Twitter/X and Reddit, labeled as Humor/Satire, Art, or Misinformation. Additionally, we explore three prompting strategies (image-guided, description-guided, and multimodally-guided) to construct a large-scale synthetic training dataset with Stable Diffusion. We conduct an extensive comparative study including modality fusion, contrastive learning, reconstruction networks, attention mechanisms, and large vision-language models. Our results show that models trained on image- and multimodally-guided data generalize better to "in the wild" content, due to preserved visual context. However, overall performance remains limited, highlighting the complexity of inferring intent and the need for specialized architectures.