Graph-Based Uncertainty Modeling and Multimodal Fusion for Salient Object Detection
作者: Yuqi Xiong, Wuzhen Shi, Yang Wen, Ruhan Liu
分类: cs.CV
发布日期: 2025-08-28
备注: ICONIP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于图的不确定性建模与多模态融合的显著性目标检测网络,提升复杂场景下的检测精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 显著性目标检测 多模态融合 图卷积网络 不确定性建模 深度学习
📋 核心要点
- 现有显著性目标检测方法在复杂场景下易丢失细节、边缘模糊,且单模态信息融合不足。
- 提出动态不确定性传播和多模态协同推理网络,利用图卷积传播不确定性,并协同融合多模态信息。
- 实验表明,该方法在常见基准数据集上优于现有方法,尤其在边缘清晰度和复杂背景鲁棒性方面。
📝 摘要(中文)
针对现有显著性目标检测(SOD)方法在复杂场景中容易丢失细节、模糊边缘以及单模态信息融合不足的问题,本文提出了一种动态不确定性传播和多模态协同推理网络(DUP-MCRNet)。首先,设计了一个动态不确定性图卷积模块(DUGC),通过基于空间语义距离构建的稀疏图来传播层间的不确定性,并结合通道自适应交互,有效提高了小结构和边缘区域的检测精度。其次,提出了一种多模态协同融合策略(MCF),它使用可学习的模态门控权重来加权融合RGB、深度和边缘特征的注意力图。它可以根据不同的场景动态调整每个模态的重要性,有效抑制冗余或干扰信息,并加强跨模态之间的语义互补性和一致性,从而提高在遮挡、弱纹理或背景干扰下识别显著区域的能力。最后,通过多尺度BCE和IoU损失、跨尺度一致性约束以及不确定性引导的监督机制,优化像素级和区域级的检测性能。大量实验表明,DUP-MCRNet在大多数常见基准数据集上优于各种SOD方法,尤其是在边缘清晰度和对复杂背景的鲁棒性方面。
🔬 方法详解
问题定义:现有显著性目标检测方法在处理复杂场景时,容易出现细节丢失、边缘模糊以及单模态信息融合不充分的问题。这些问题导致模型在遮挡、弱纹理或背景干扰等情况下,难以准确识别显著性目标。现有方法通常采用简单的特征融合方式,无法有效利用多模态信息之间的互补性,并且缺乏对不确定性的建模,导致模型对噪声和干扰敏感。
核心思路:本文的核心思路是利用图卷积网络对特征的不确定性进行建模和传播,并设计多模态协同融合策略,充分利用RGB、深度和边缘等多模态信息。通过动态调整不同模态的重要性,抑制冗余或干扰信息,加强跨模态之间的语义互补性和一致性,从而提高模型在复杂场景下的显著性目标检测性能。
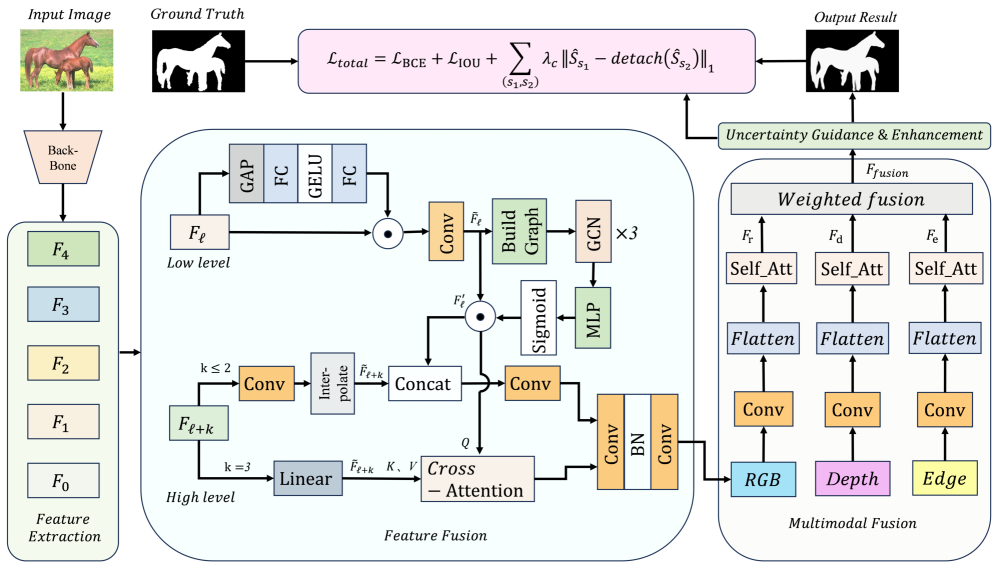
技术框架:DUP-MCRNet的整体架构包含以下几个主要模块:1) 特征提取模块:分别提取RGB、深度和边缘特征。2) 动态不确定性图卷积模块(DUGC):构建基于空间语义距离的稀疏图,通过图卷积传播层间的不确定性,并结合通道自适应交互,提高小结构和边缘区域的检测精度。3) 多模态协同融合策略(MCF):使用可学习的模态门控权重,加权融合RGB、深度和边缘特征的注意力图。4) 优化模块:通过多尺度BCE和IoU损失、跨尺度一致性约束以及不确定性引导的监督机制,优化像素级和区域级的检测性能。
关键创新:本文的关键创新在于:1) 提出了动态不确定性图卷积模块(DUGC),通过图卷积对特征的不确定性进行建模和传播,有效提高了小结构和边缘区域的检测精度。2) 提出了多模态协同融合策略(MCF),能够动态调整不同模态的重要性,抑制冗余或干扰信息,加强跨模态之间的语义互补性和一致性。与现有方法相比,该方法能够更有效地利用多模态信息,并对不确定性进行建模,从而提高模型在复杂场景下的鲁棒性。
关键设计:DUGC模块中,稀疏图的构建基于空间语义距离,选取距离最近的k个节点进行连接。MCF模块中,模态门控权重通过一个小型神经网络学习得到,用于动态调整不同模态的重要性。损失函数包括多尺度BCE和IoU损失,用于优化像素级和区域级的检测性能;跨尺度一致性约束用于保证不同尺度特征的一致性;不确定性引导的监督机制用于引导模型学习特征的不确定性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DUP-MCRNet在多个公开数据集上取得了优异的性能,尤其是在边缘清晰度和对复杂背景的鲁棒性方面。相较于现有方法,该方法在显著性目标检测精度上取得了显著提升,例如在某些数据集上F-measure指标提升了3%-5%。实验结果验证了所提出的动态不确定性建模和多模态融合策略的有效性。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、机器人导航、图像编辑等领域。通过提高复杂场景下的显著性目标检测精度,可以提升相关系统的感知能力和决策能力,例如在自动驾驶中更准确地识别行人、车辆等目标,在智能监控中更有效地检测异常事件。
📄 摘要(原文)
In view of the problems that existing salient object detection (SOD) methods are prone to losing details, blurring edges, and insufficient fusion of single-modal information in complex scenes, this paper proposes a dynamic uncertainty propagation and multimodal collaborative reasoning network (DUP-MCRNet). Firstly, a dynamic uncertainty graph convolution module (DUGC) is designed to propagate uncertainty between layers through a sparse graph constructed based on spatial semantic distance, and combined with channel adaptive interaction, it effectively improves the detection accuracy of small structures and edge regions. Secondly, a multimodal collaborative fusion strategy (MCF) is proposed, which uses learnable modality gating weights to weightedly fuse the attention maps of RGB, depth, and edge features. It can dynamically adjust the importance of each modality according to different scenes, effectively suppress redundant or interfering information, and strengthen the semantic complementarity and consistency between cross-modalities, thereby improving the ability to identify salient regions under occlusion, weak texture or background interference. Finally, the detection performance at the pixel level and region level is optimized through multi-scale BCE and IoU loss, cross-scale consistency constraints, and uncertainty-guided supervision mechanisms. Extensive experiments show that DUP-MCRNet outperforms various SOD methods on most common benchmark datasets, especially in terms of edge clarity and robustness to complex backgrounds. Our code is publicly available at https://github.com/YukiBear426/DUP-MCRNet.