MedFoundationHub: A Lightweight and Secure Toolkit for Deploying Medical Vision Language Foundation Models
作者: Xiao Li, Yanfan Zhu, Ruining Deng, Wei-Qi Wei, Yu Wang, Shilin Zhao, Yaohong Wang, Haichun Yang, Yuankai Huo
分类: cs.CV, cs.HC
发布日期: 2025-08-28
💡 一句话要点
MedFoundationHub:轻量安全医学视觉语言模型部署工具包,解决PHI暴露风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学视觉语言模型 安全部署 图形用户界面 Docker容器化 隐私保护 临床应用 模型评估
📋 核心要点
- 医学VLM面临PHI暴露、数据泄露等安全挑战,限制了其在临床环境中的应用。
- MedFoundationHub提供GUI工具包,简化医学VLM的部署和使用,同时保障隐私安全。
- 专家评估揭示现有VLM在医学领域的局限性,为未来模型改进提供方向。
📝 摘要(中文)
医学视觉语言模型(VLMs)的最新进展为临床应用带来了显著机遇,如自动报告生成、医生辅助和不确定性量化。然而,医学VLMs也带来了严重的安全问题,特别是受保护健康信息(PHI)暴露、数据泄露和网络威胁的风险,这在医院环境中尤为关键。即使在研究或非临床用途中采用,医疗机构也必须谨慎并实施保护措施。为了应对这些挑战,我们提出了MedFoundationHub,一个图形用户界面(GUI)工具包,它:(1)使医生无需编程专业知识即可手动选择和使用不同的模型,(2)支持工程师以即插即用的方式高效部署医学VLMs,无缝集成Hugging Face开源模型,以及(3)通过Docker编排的、操作系统无关的部署来确保隐私保护推理。MedFoundationHub只需要配备单个NVIDIA A6000 GPU的离线本地工作站,使其在学术研究实验室的典型资源范围内既安全又可访问。为了评估当前的能力,我们邀请了经过认证的病理学家来部署和评估五个最先进的VLMs(Google-MedGemma3-4B、Qwen2-VL-7B-Instruct、Qwen2.5-VL-7B-Instruct和LLaVA-1.5-7B/13B)。专家评估涵盖了结肠病例和肾脏病例,产生了1015个临床医生-模型评分事件。这些评估揭示了反复出现的局限性,包括脱靶答案、模糊的推理和不一致的病理学术语。
🔬 方法详解
问题定义:医学视觉语言模型(VLMs)在临床应用中潜力巨大,但同时也面临着严重的安全风险,包括患者隐私信息(PHI)泄露、数据泄露以及潜在的网络攻击。现有方法在部署和使用这些模型时,往往需要专业的编程知识,并且难以保证数据安全,限制了其在医疗机构中的应用。
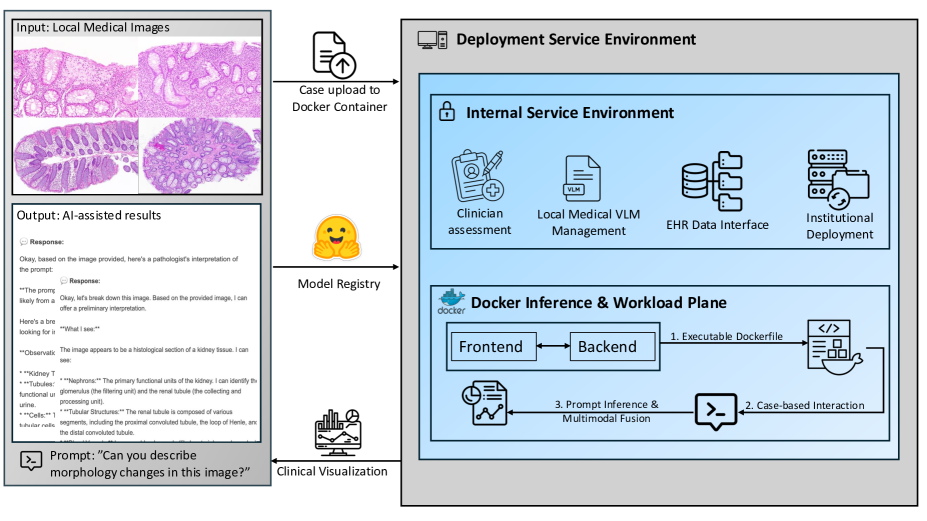
核心思路:MedFoundationHub的核心思路是提供一个易于使用、安全可靠的平台,使医生和工程师能够方便地部署和使用医学VLMs,同时最大限度地减少安全风险。通过图形用户界面(GUI)简化操作,并采用Docker容器化技术隔离环境,保障数据安全。
技术框架:MedFoundationHub采用Docker容器化技术,将不同的医学VLMs封装在独立的容器中,实现环境隔离和资源管理。用户通过GUI界面选择和配置模型,系统自动部署和运行相应的容器。平台支持Hugging Face开源模型,方便用户集成和使用最新的VLM。整个系统可以在配备单个NVIDIA A6000 GPU的本地工作站上运行,无需连接外部网络。
关键创新:MedFoundationHub的关键创新在于其易用性和安全性。通过GUI界面,医生无需编程知识即可使用VLM,降低了使用门槛。Docker容器化技术有效隔离了模型和数据,防止数据泄露和恶意攻击。此外,该平台还支持离线部署,进一步增强了安全性。
关键设计:MedFoundationHub的关键设计包括:(1) 用户友好的GUI界面,提供模型选择、参数配置和结果展示等功能;(2) 基于Docker的容器化部署,实现环境隔离和资源管理;(3) 支持Hugging Face开源模型,方便用户集成和使用最新的VLM;(4) 离线部署模式,无需连接外部网络,增强安全性。
🖼️ 关键图片


📊 实验亮点
研究者邀请了认证病理学家使用MedFoundationHub部署和评估了五个先进的VLMs(Google-MedGemma3-4B、Qwen2-VL-7B-Instruct、Qwen2.5-VL-7B-Instruct和LLaVA-1.5-7B/13B),涵盖结肠和肾脏病例,共计1015个评分事件。评估结果揭示了现有VLM在医学领域的局限性,例如脱靶答案和模糊推理,为后续模型改进提供了宝贵数据。
🎯 应用场景
MedFoundationHub可广泛应用于医疗机构,辅助医生进行诊断、报告生成和决策支持。该工具包降低了医学VLM的使用门槛,并保障了患者隐私,促进了人工智能在医疗领域的安全应用。未来,该平台可扩展到其他医疗AI模型,构建更全面的医疗AI服务生态系统。
📄 摘要(原文)
Recent advances in medical vision-language models (VLMs) open up remarkable opportunities for clinical applications such as automated report generation, copilots for physicians, and uncertainty quantification. However, despite their promise, medical VLMs introduce serious security concerns, most notably risks of Protected Health Information (PHI) exposure, data leakage, and vulnerability to cyberthreats - which are especially critical in hospital environments. Even when adopted for research or non-clinical purposes, healthcare organizations must exercise caution and implement safeguards. To address these challenges, we present MedFoundationHub, a graphical user interface (GUI) toolkit that: (1) enables physicians to manually select and use different models without programming expertise, (2) supports engineers in efficiently deploying medical VLMs in a plug-and-play fashion, with seamless integration of Hugging Face open-source models, and (3) ensures privacy-preserving inference through Docker-orchestrated, operating system agnostic deployment. MedFoundationHub requires only an offline local workstation equipped with a single NVIDIA A6000 GPU, making it both secure and accessible within the typical resources of academic research labs. To evaluate current capabilities, we engaged board-certified pathologists to deploy and assess five state-of-the-art VLMs (Google-MedGemma3-4B, Qwen2-VL-7B-Instruct, Qwen2.5-VL-7B-Instruct, and LLaVA-1.5-7B/13B). Expert evaluation covered colon cases and renal cases, yielding 1015 clinician-model scoring events. These assessments revealed recurring limitations, including off-target answers, vague reasoning, and inconsistent pathology terminology.