Text-Driven 3D Hand Motion Generation from Sign Language Data
作者: Léore Bensabath, Mathis Petrovich, Gül Varol
分类: cs.CV
发布日期: 2025-08-21
备注: Project page: https://imagine.enpc.fr/~leore.bensabath/HandMDM/, 24 pages, 14 figures
💡 一句话要点
提出HandMDM,利用大规模手语数据实现文本驱动的3D手部动作生成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 3D手部动作生成 文本驱动 扩散模型 手语数据 自然语言描述
📋 核心要点
- 现有方法难以生成具有细粒度控制的3D手部动作,尤其是在文本描述的引导下。
- 论文提出HandMDM,利用大规模手语数据和LLM生成文本描述,训练文本条件扩散模型。
- 实验表明,HandMDM在未见过的手语类别和不同手语中表现出良好的泛化能力。
📝 摘要(中文)
本文旨在训练一个生成式的3D手部动作模型,该模型以自然语言描述为条件,描述手部动作的特征,例如手势形状、位置、手指/手/手臂的运动。为此,我们自动构建了大规模的3D手部动作及其相关文本标签的配对数据。具体来说,我们利用大规模手语视频数据集,以及带噪声的伪标注手语类别,通过大型语言模型(LLM)将其翻译成手部动作描述,该LLM利用手语属性字典以及我们补充的运动脚本提示。该数据支持训练一个文本条件手部动作扩散模型HandMDM,该模型在不同领域具有鲁棒性,例如来自同一手语的未见过的手语类别,以及来自另一种手语的手语和非手语手部动作。我们对这些场景进行了广泛的实验研究,并将公开我们的训练模型和数据,以支持这个相对较新领域的未来研究。
🔬 方法详解
问题定义:现有方法在生成3D手部动作时,难以实现基于自然语言描述的细粒度控制。缺乏大规模的、带有精确文本描述的手部动作数据集是主要瓶颈。此外,如何利用自然语言描述来引导手部动作的生成,并保证生成动作的自然性和多样性,也是一个挑战。
核心思路:论文的核心思路是利用大规模的手语视频数据,通过自动化的方式生成带有文本描述的手部动作数据,然后训练一个文本条件的扩散模型。通过这种方式,模型可以学习到文本描述和手部动作之间的对应关系,从而实现文本驱动的手部动作生成。
技术框架:整体框架包含以下几个主要模块:1) 大规模手语视频数据集;2) 基于LLM的文本描述生成模块,该模块利用手语属性字典和运动脚本提示,将带噪声的手语类别标签翻译成详细的手部动作描述;3) 文本条件扩散模型HandMDM,该模型以文本描述为条件,生成3D手部动作序列。
关键创新:最重要的创新点在于利用大规模手语数据和LLM自动生成文本描述,从而构建了一个大规模的、带有文本描述的手部动作数据集。这使得训练文本条件的手部动作生成模型成为可能,并显著提高了模型的泛化能力。
关键设计:HandMDM采用扩散模型的架构,通过逐步去噪的方式生成手部动作。模型的输入包括文本描述和随机噪声,输出是3D手部动作序列。损失函数采用标准的扩散模型损失函数,用于衡量生成动作和真实动作之间的差异。文本描述通过Transformer编码器进行编码,然后作为条件输入到扩散模型中。
🖼️ 关键图片

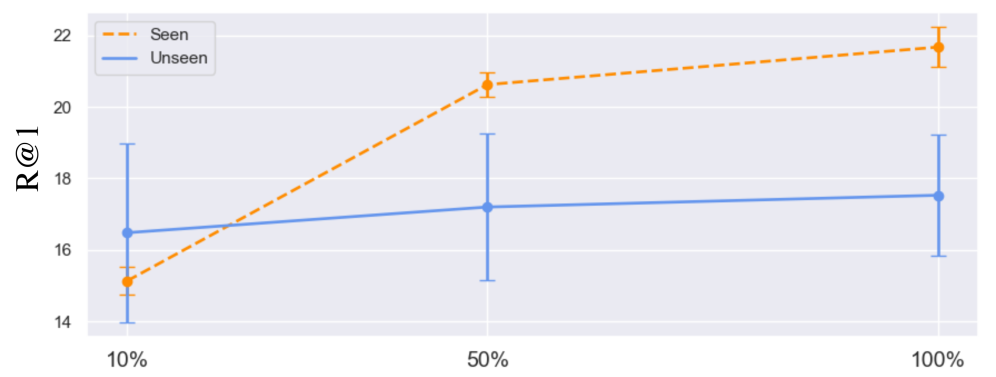
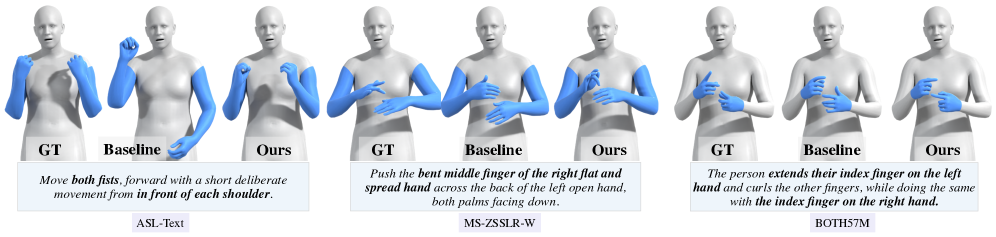
📊 实验亮点
实验结果表明,HandMDM在未见过的手语类别和不同手语中表现出良好的泛化能力。模型能够根据文本描述生成自然流畅的手部动作,并且能够捕捉到文本描述中的细微差异。与现有方法相比,HandMDM在生成质量和多样性方面都有显著提升。
🎯 应用场景
该研究成果可应用于虚拟现实、人机交互、手语翻译等领域。例如,可以根据用户的语音或文本指令,生成自然流畅的手部动作,从而实现更自然的人机交互。此外,该技术还可以用于手语教学和手语翻译,帮助人们更好地理解和学习手语。
📄 摘要(原文)
Our goal is to train a generative model of 3D hand motions, conditioned on natural language descriptions specifying motion characteristics such as handshapes, locations, finger/hand/arm movements. To this end, we automatically build pairs of 3D hand motions and their associated textual labels with unprecedented scale. Specifically, we leverage a large-scale sign language video dataset, along with noisy pseudo-annotated sign categories, which we translate into hand motion descriptions via an LLM that utilizes a dictionary of sign attributes, as well as our complementary motion-script cues. This data enables training a text-conditioned hand motion diffusion model HandMDM, that is robust across domains such as unseen sign categories from the same sign language, but also signs from another sign language and non-sign hand movements. We contribute extensive experimental investigation of these scenarios and will make our trained models and data publicly available to support future research in this relatively new field.