StreamMem: Query-Agnostic KV Cache Memory for Streaming Video Understanding
作者: Yanlai Yang, Zhuokai Zhao, Satya Narayan Shukla, Aashu Singh, Shlok Kumar Mishra, Lizhu Zhang, Mengye Ren
分类: cs.CV, cs.AI
发布日期: 2025-08-21
备注: 15 pages, 3 figures
💡 一句话要点
StreamMem:面向流视频理解的查询无关KV缓存记忆机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流视频理解 KV缓存压缩 多模态大语言模型 长视频处理 查询无关 注意力机制 视频问答
📋 核心要点
- 现有长视频理解方法在存储和处理长视觉上下文的KV缓存时,面临着巨大的内存和计算开销挑战。
- StreamMem通过流式编码视频帧,并利用视觉token和通用查询token的注意力分数压缩KV缓存,实现高效的内存管理。
- 实验结果表明,StreamMem在多个长视频理解和流视频问答基准测试中,达到了最先进的查询无关KV缓存压缩性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)在视觉-语言推理方面取得了显著进展,但其有效处理长视频的能力仍然有限。尽管长上下文MLLM最近有所发展,但存储和关注长视觉上下文的关键-值(KV)缓存会产生大量的内存和计算开销。现有的视觉压缩方法要么需要在压缩之前编码整个视觉上下文,要么需要提前访问问题,这对于长视频理解和多轮对话设置是不切实际的。在这项工作中,我们提出StreamMem,一种用于流视频理解的查询无关KV缓存记忆机制。具体来说,StreamMem以流式方式编码新的视频帧,使用视觉token和通用查询token之间的注意力分数压缩KV缓存,同时保持固定大小的KV内存,以在内存受限的长视频场景中实现高效的问答(QA)。在三个长视频理解和两个流视频问答基准上的评估表明,StreamMem在查询无关的KV缓存压缩方面实现了最先进的性能,并且与查询相关的压缩方法相比具有竞争力。
🔬 方法详解
问题定义:现有方法在处理长视频时,需要存储大量的KV缓存,导致内存和计算开销巨大。此外,一些视觉压缩方法需要提前编码整个视觉上下文或访问问题,这在流视频和多轮对话场景中是不切实际的。因此,需要一种能够在内存受限的情况下,高效处理长视频,且无需预先访问问题的KV缓存压缩方法。
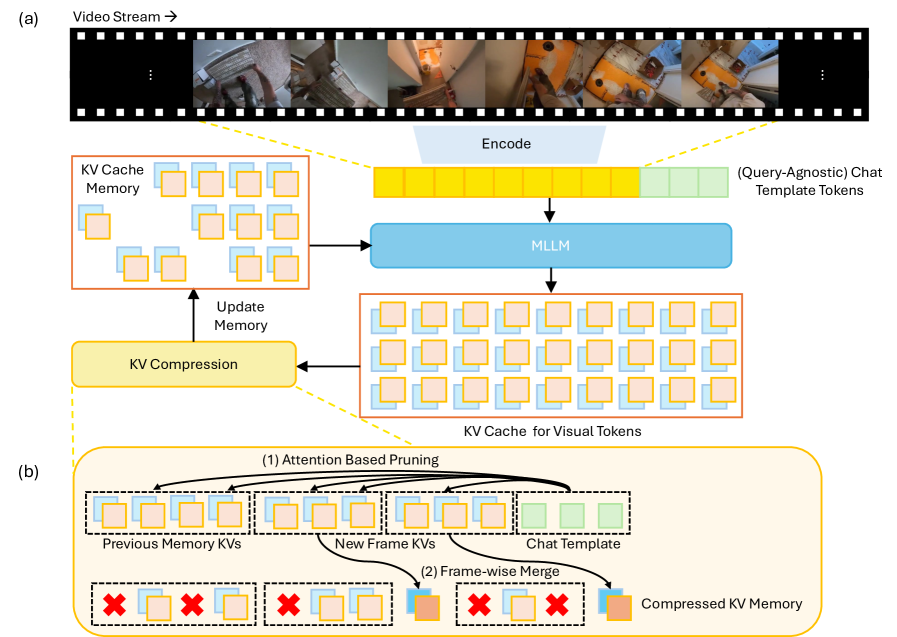
核心思路:StreamMem的核心思路是在流式处理视频帧的同时,动态地压缩KV缓存。它利用视觉token和通用查询token之间的注意力机制,选择性地保留重要的视觉信息,从而在保持性能的同时,显著减少KV缓存的大小。这种方法无需预先访问问题,适用于流视频和多轮对话场景。
技术框架:StreamMem的整体框架包括以下几个主要阶段:1) 视频帧的流式编码:将视频帧逐帧输入模型进行编码,提取视觉特征。2) KV缓存的构建:将编码后的视觉特征作为KV缓存存储。3) 注意力压缩:利用视觉token和通用查询token之间的注意力分数,对KV缓存进行压缩,保留重要的视觉信息。4) 问题回答:利用压缩后的KV缓存,回答用户提出的问题。
关键创新:StreamMem的关键创新在于其查询无关的KV缓存压缩机制。与需要预先访问问题的压缩方法不同,StreamMem利用通用查询token来评估视觉token的重要性,从而实现与查询无关的压缩。这种方法更适用于流视频和多轮对话场景,因为它不需要提前知道用户的问题。
关键设计:StreamMem的关键设计包括:1) 使用通用查询token来计算视觉token的注意力分数。2) 设计了一种注意力压缩算法,根据注意力分数选择性地保留KV缓存中的视觉信息。3) 采用固定大小的KV内存,以确保在内存受限的情况下也能高效运行。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
StreamMem在三个长视频理解和两个流视频问答基准上进行了评估,结果表明其在查询无关的KV缓存压缩方面达到了最先进的性能。与现有的查询相关的压缩方法相比,StreamMem也具有竞争力,并且在某些情况下甚至超过了它们。这些结果证明了StreamMem在长视频理解和流视频问答方面的有效性。
🎯 应用场景
StreamMem具有广泛的应用前景,例如智能监控、视频会议、在线教育等。它可以帮助这些应用在内存受限的设备上高效地处理长视频,并支持实时的问答和交互。此外,StreamMem还可以应用于机器人视觉、自动驾驶等领域,提高这些系统在复杂环境中的感知和理解能力。
📄 摘要(原文)
Multimodal large language models (MLLMs) have made significant progress in visual-language reasoning, but their ability to efficiently handle long videos remains limited. Despite recent advances in long-context MLLMs, storing and attending to the key-value (KV) cache for long visual contexts incurs substantial memory and computational overhead. Existing visual compression methods require either encoding the entire visual context before compression or having access to the questions in advance, which is impractical for long video understanding and multi-turn conversational settings. In this work, we propose StreamMem, a query-agnostic KV cache memory mechanism for streaming video understanding. Specifically, StreamMem encodes new video frames in a streaming manner, compressing the KV cache using attention scores between visual tokens and generic query tokens, while maintaining a fixed-size KV memory to enable efficient question answering (QA) in memory-constrained, long-video scenarios. Evaluation on three long video understanding and two streaming video question answering benchmarks shows that StreamMem achieves state-of-the-art performance in query-agnostic KV cache compression and is competitive with query-aware compression approaches.