MapKD: Unlocking Prior Knowledge with Cross-Modal Distillation for Efficient Online HD Map Construction
作者: Ziyang Yan, Ruikai Li, Zhiyong Cui, Bohan Li, Han Jiang, Yilong Ren, Aoyong Li, Zhenning Li, Sijia Wen, Haiyang Yu
分类: cs.CV
发布日期: 2025-08-21 (更新: 2025-08-22)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MapKD,通过跨模态知识蒸馏实现高效在线高清地图构建
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线高清地图构建 知识蒸馏 跨模态学习 Teacher-Coach-Student nuScenes数据集
📋 核心要点
- 现有在线高清地图构建方法依赖离线地图和多模态传感器,计算开销大,限制了其应用。
- MapKD提出Teacher-Coach-Student框架,利用知识蒸馏将多模态教师模型的知识迁移到轻量级视觉学生模型。
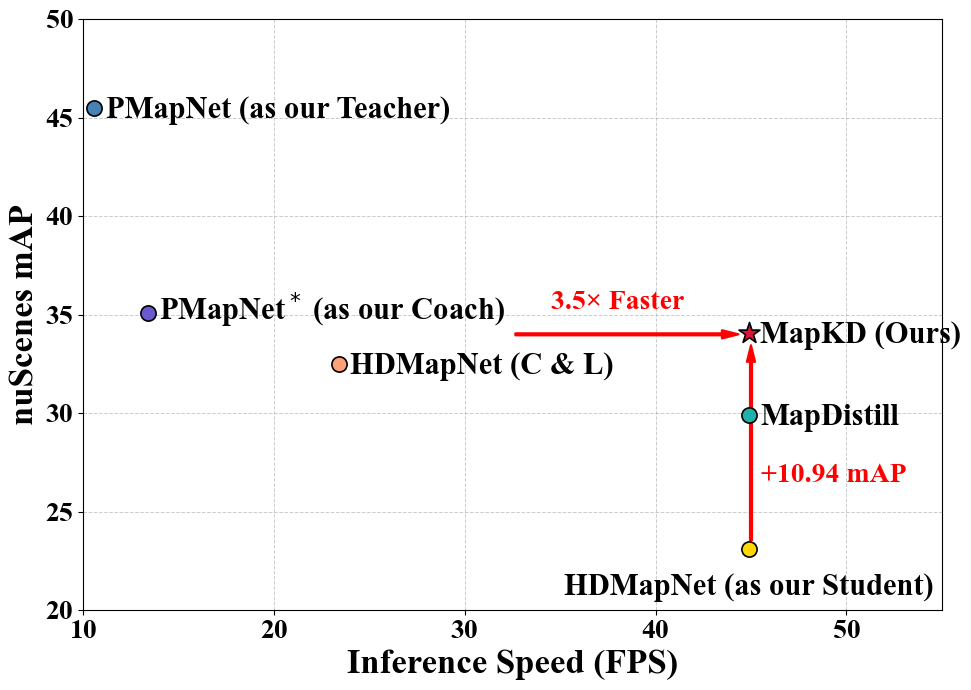
- 实验表明,MapKD显著提升了学生模型的性能(+6.68 mIoU,+10.94 mAP),并加速了推理速度。
📝 摘要(中文)
在线高清地图构建是自动驾驶系统中的一项基本任务,旨在基于实时传感器输入获取车辆周围地图元素的语义信息。最近,一些方法通过结合离线先验知识(如SD地图和HD地图)或融合多模态数据取得了有希望的结果。然而,这些方法依赖于过时的离线地图和多模态传感器套件,导致推理时产生不必要的计算开销。为了解决这些限制,我们采用知识蒸馏策略,将来自具有先验知识的多模态模型的知识转移到高效、低成本且以视觉为中心的学生模型。具体来说,我们提出了MapKD,一种新颖的多层次跨模态知识蒸馏框架,具有创新的Teacher-Coach-Student(TCS)范式。该框架包括:(1)一个具有SD/HD地图先验的相机-激光雷达融合模型,作为教师;(2)一个具有先验知识和模拟激光雷达的以视觉为中心的教练模型,以弥合跨模态知识转移差距;(3)一个轻量级的基于视觉的学生模型。此外,我们引入了两种有针对性的知识蒸馏策略:用于鸟瞰图特征对齐的Token-Guided 2D Patch Distillation(TGPD)和用于语义学习指导的Masked Semantic Response Distillation(MSRD)。在具有挑战性的nuScenes数据集上的大量实验表明,MapKD将学生模型提高了+6.68 mIoU和+10.94 mAP,同时加快了推理速度。
🔬 方法详解
问题定义:论文旨在解决在线高清地图构建中,现有方法依赖离线地图和多模态传感器导致计算开销大的问题。这些方法在推理时效率较低,难以满足实时性要求,限制了其在资源受限平台上的部署。
核心思路:论文的核心思路是利用知识蒸馏,将复杂的多模态教师模型的知识迁移到轻量级的视觉学生模型。通过这种方式,学生模型可以在不依赖昂贵传感器和离线地图的情况下,实现高性能的在线高清地图构建。引入Coach模型是为了弥合相机和激光雷达之间的模态差异,从而更好地进行知识迁移。
技术框架:MapKD采用Teacher-Coach-Student (TCS) 框架。教师模型是相机-激光雷达融合模型,具有SD/HD地图先验知识。教练模型是以视觉为中心的模型,具有先验知识和模拟激光雷达数据,用于桥接跨模态知识转移的差距。学生模型是轻量级的视觉模型。知识从教师传递到教练,再从教练传递到学生。
关键创新:论文的关键创新在于提出的多层次跨模态知识蒸馏框架和两种针对性的知识蒸馏策略:Token-Guided 2D Patch Distillation (TGPD) 和 Masked Semantic Response Distillation (MSRD)。TGPD用于鸟瞰图特征对齐,MSRD用于语义学习指导。TCS框架和两种蒸馏策略共同作用,实现了高效的知识迁移。
关键设计:TGPD通过token注意力机制引导特征块的蒸馏,关注重要区域。MSRD通过掩码操作,聚焦于语义信息的学习,避免噪声干扰。损失函数包括特征蒸馏损失和语义蒸馏损失。教师模型使用相机-激光雷达融合网络,教练模型和学生模型使用基于视觉的网络结构。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
MapKD在nuScenes数据集上取得了显著的性能提升。学生模型在mIoU指标上提升了+6.68,在mAP指标上提升了+10.94,同时加快了推理速度。这些结果表明,MapKD能够有效地将知识从复杂的多模态模型迁移到轻量级的视觉模型,实现高性能和高效率的在线高清地图构建。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能交通等领域。通过降低对传感器和计算资源的需求,使得在线高清地图构建能够在低成本平台和资源受限的环境中部署,加速自动驾驶技术的普及和应用。未来,该方法可以进一步扩展到其他感知任务和场景。
📄 摘要(原文)
Online HD map construction is a fundamental task in autonomous driving systems, aiming to acquire semantic information of map elements around the ego vehicle based on real-time sensor inputs. Recently, several approaches have achieved promising results by incorporating offline priors such as SD maps and HD maps or by fusing multi-modal data. However, these methods depend on stale offline maps and multi-modal sensor suites, resulting in avoidable computational overhead at inference. To address these limitations, we employ a knowledge distillation strategy to transfer knowledge from multimodal models with prior knowledge to an efficient, low-cost, and vision-centric student model. Specifically, we propose MapKD, a novel multi-level cross-modal knowledge distillation framework with an innovative Teacher-Coach-Student (TCS) paradigm. This framework consists of: (1) a camera-LiDAR fusion model with SD/HD map priors serving as the teacher; (2) a vision-centric coach model with prior knowledge and simulated LiDAR to bridge the cross-modal knowledge transfer gap; and (3) a lightweight vision-based student model. Additionally, we introduce two targeted knowledge distillation strategies: Token-Guided 2D Patch Distillation (TGPD) for bird's eye view feature alignment and Masked Semantic Response Distillation (MSRD) for semantic learning guidance. Extensive experiments on the challenging nuScenes dataset demonstrate that MapKD improves the student model by +6.68 mIoU and +10.94 mAP while simultaneously accelerating inference speed. The code is available at:https://github.com/2004yan/MapKD2026.