When and What: Diffusion-Grounded VideoLLM with Entity Aware Segmentation for Long Video Understanding
作者: Pengcheng Fang, Yuxia Chen, Rui Guo
分类: cs.CV
发布日期: 2025-08-21
💡 一句话要点
Grounded VideoDiT:融合扩散模型与实体感知的视频LLM,提升长视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 视频语言模型 扩散模型 时间感知 实体接地 多模态学习 视频问答
📋 核心要点
- 现有VideoLLM在时间感知上较为粗糙,时间戳编码隐式,帧级别特征难以捕捉连续性,语言视觉对齐容易偏离目标实体。
- Grounded VideoDiT通过扩散时间潜在编码器、实体接地表示和混合token方案,显式建模时间信息,增强时间一致性和语言视觉对齐。
- 实验表明,Grounded VideoDiT在多个长视频理解基准测试中取得了SOTA结果,验证了其在时间感知和实体理解方面的有效性。
📝 摘要(中文)
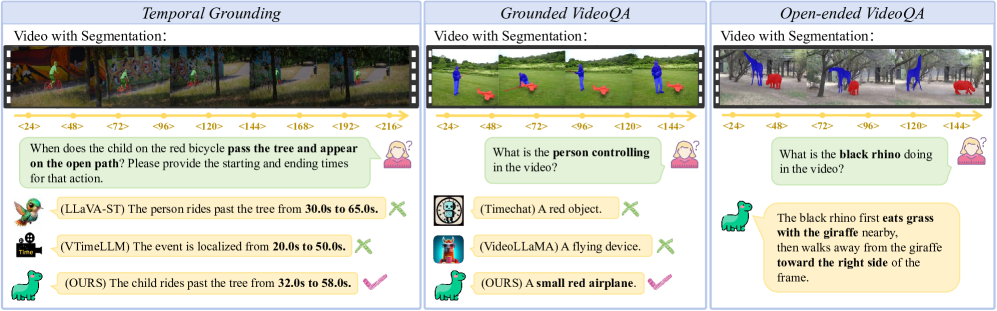
本文提出了一种名为Grounded VideoDiT的视频语言模型(VideoLLM),旨在克服现有模型在时间感知方面的局限性,从而提升长视频理解能力。该模型通过引入三个关键创新实现这一目标:首先,扩散时间潜在编码器(DTL)增强了边界敏感性和时间一致性;其次,对象接地的表示显式地将查询实体与局部视觉证据绑定,从而加强对齐;第三,具有离散时间token的混合token方案提供了显式的时间戳建模,从而实现细粒度的时间推理。实验结果表明,Grounded VideoDiT在Charades STA、NExT GQA和多个VideoQA基准测试中取得了最先进的结果,验证了其强大的接地能力。
🔬 方法详解
问题定义:现有VideoLLM在长视频理解中面临时间感知不足的问题。具体表现为:时间戳信息隐式编码,难以进行精细的时间推理;帧级别特征难以捕捉视频中的时间连续性;语言和视觉特征的对齐容易偏离用户感兴趣的实体。这些问题限制了模型在需要精确时间定位和实体交互理解的任务中的表现。
核心思路:Grounded VideoDiT的核心思路是通过显式地建模时间信息和加强语言视觉对齐来提升长视频理解能力。具体来说,模型利用扩散模型学习时间潜在表示,增强时间边界的敏感性;通过实体接地表示将查询实体与局部视觉证据绑定,从而加强对齐;并使用混合token方案显式地建模时间戳信息,从而实现细粒度的时间推理。
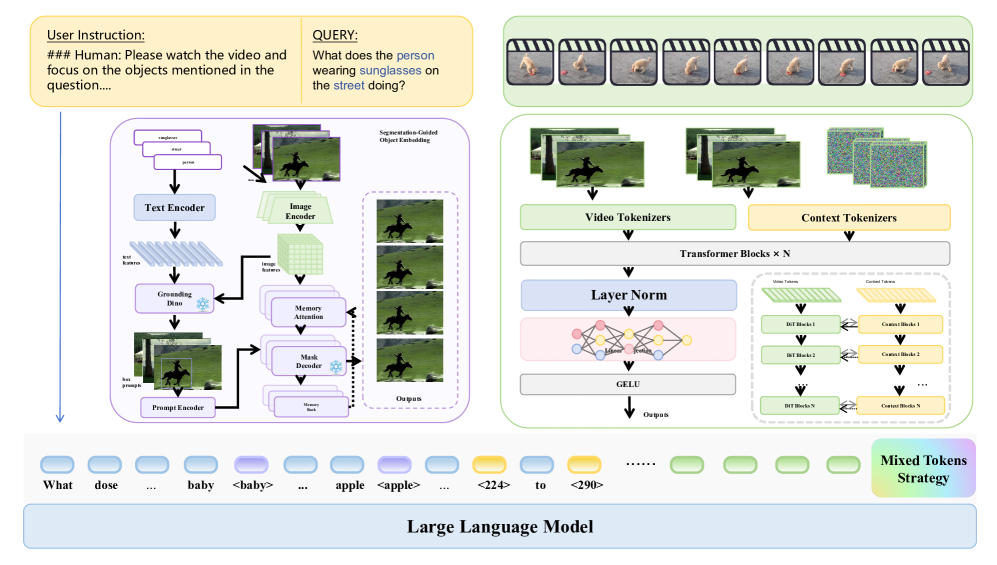
技术框架:Grounded VideoDiT的整体架构包含三个主要模块:1) 扩散时间潜在编码器(DTL):用于提取具有时间一致性的视频特征;2) 对象接地模块:用于将查询实体与局部视觉证据对齐;3) 混合Token方案:用于显式地建模时间戳信息。模型首先使用DTL编码视频,然后利用对象接地模块将查询实体与视觉特征对齐,最后使用混合token方案将时间戳信息融入到语言模型中。
关键创新:Grounded VideoDiT的关键创新在于三个方面:1) 扩散时间潜在编码器(DTL),利用扩散模型学习时间潜在表示,增强了时间边界的敏感性,并保持了时间一致性。2) 对象接地表示,显式地将查询实体与局部视觉证据绑定,从而加强了语言视觉对齐。3) 混合token方案,使用离散的时间token显式地建模时间戳信息,从而实现细粒度的时间推理。与现有方法相比,Grounded VideoDiT更加注重时间信息的建模和语言视觉对齐。
关键设计:扩散时间潜在编码器(DTL)的具体实现细节未知。对象接地模块可能使用了注意力机制或者其他对齐方法,具体实现细节未知。混合token方案的具体实现细节未知,可能涉及到如何将离散的时间token融入到语言模型的输入中,以及如何设计相应的损失函数。
🖼️ 关键图片
📊 实验亮点
Grounded VideoDiT在Charades STA、NExT GQA和多个VideoQA基准测试中取得了state-of-the-art的结果。具体性能数据和提升幅度未知,但结果表明该模型在时间感知和实体理解方面具有显著优势,能够有效提升长视频理解能力。
🎯 应用场景
Grounded VideoDiT在视频监控、智能安防、视频内容分析、人机交互等领域具有广泛的应用前景。例如,可以用于自动识别视频中的事件发生时间、理解视频中人物的交互行为、以及根据用户的提问在视频中定位相关内容。该研究的成果有助于提升机器对视频内容的理解能力,为构建更智能的视频应用提供技术支持。
📄 摘要(原文)
Understanding videos requires more than answering open ended questions, it demands the ability to pinpoint when events occur and how entities interact across time. While recent Video LLMs have achieved remarkable progress in holistic reasoning, they remain coarse in temporal perception: timestamps are encoded only implicitly, frame level features are weak in capturing continuity, and language vision alignment often drifts from the entities of interest. In this paper, we present Grounded VideoDiT, a Video LLM designed to overcome these limitations by introducing three key innovations. First, a Diffusion Temporal Latent (DTL) encoder enhances boundary sensitivity and maintains temporal consistency. Second, object grounded representations explicitly bind query entities to localized visual evidence, strengthening alignment. Third, a mixed token scheme with discrete temporal tokens provides explicit timestamp modeling, enabling fine grained temporal reasoning. Together, these designs equip Grounded VideoDiT with robust grounding capabilities, as validated by state of the art results on Charades STA, NExT GQA, and multiple VideoQA benchmarks.