Task-Generalized Adaptive Cross-Domain Learning for Multimodal Image Fusion
作者: Mengyu Wang, Zhenyu Liu, Kun Li, Yu Wang, Yuwei Wang, Yanyan Wei, Fei Wang
分类: cs.CV
发布日期: 2025-08-21
备注: Accepted by IEEE Transactions on Multimedia
🔗 代码/项目: GITHUB
💡 一句话要点
AdaSFFuse:面向多模态图像融合的自适应跨域学习框架,提升泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态图像融合 跨域学习 自适应小波变换 Mamba块 频率解耦
📋 核心要点
- 现有MMIF方法在模态对齐、高频细节保持和任务泛化性方面存在不足,限制了其在复杂场景中的应用。
- AdaSFFuse提出自适应跨域协同融合学习,通过AdaWAT进行频率解耦,并利用空域-频域Mamba块实现高效融合。
- 实验表明,AdaSFFuse在多个MMIF任务上表现出优越的融合性能,同时保持了较低的计算成本和紧凑的网络结构。
📝 摘要(中文)
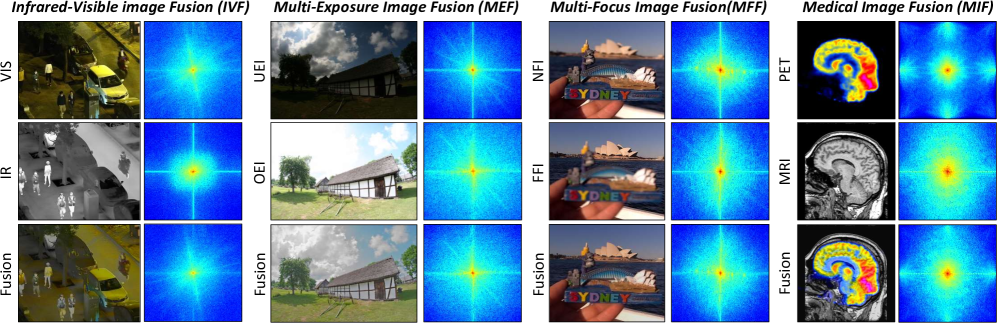
多模态图像融合(MMIF)旨在整合来自不同成像模式的互补信息,以克服单个传感器的局限性,从而增强图像质量并促进遥感、医学诊断和机器人等下游应用。尽管取得了显著进展,但当前的MMIF方法仍然面临着模态不对齐、高频细节丢失和任务特定限制等挑战。为了解决这些问题,我们提出了一种新颖的框架AdaSFFuse,通过自适应跨域协同融合学习实现任务泛化的MMIF。AdaSFFuse引入了两项关键创新:用于频率解耦的自适应近似小波变换(AdaWAT)和用于高效多模态融合的空域-频域Mamba块。AdaWAT自适应地分离来自不同场景的多模态图像的高频和低频分量,从而能够对每种模态的不同频率特征进行细粒度的提取和对齐。空域-频域Mamba块促进了空域和频域中的跨域融合,从而增强了这一过程。这些块通过可学习的映射动态调整,以确保跨不同模态的鲁棒融合。通过结合这些组件,AdaSFFuse改进了多模态特征的对齐和集成,减少了频率损失,并保留了关键细节。在红外-可见光图像融合(IVF)、多焦点图像融合(MFF)、多曝光图像融合(MEF)和医学图像融合(MIF)这四个MMIF任务上的大量实验表明,AdaSFFuse具有卓越的融合性能,同时确保了低计算成本和紧凑的网络,在性能和效率之间提供了强大的平衡。代码将在https://github.com/Zhen-yu-Liu/AdaSFFuse上公开。
🔬 方法详解
问题定义:论文旨在解决多模态图像融合中存在的模态不对齐、高频细节丢失以及任务泛化性差的问题。现有方法通常难以在不同模态和不同任务之间取得良好的平衡,导致融合结果质量下降,且模型泛化能力受限。
核心思路:论文的核心思路是利用自适应跨域协同融合学习,通过自适应小波变换将图像分解为不同频率分量,并在空域和频域上进行融合。通过引入Mamba块,增强模型对不同模态特征的动态调整能力,从而提高融合效果和泛化能力。
技术框架:AdaSFFuse框架主要包含以下几个模块:1) 自适应近似小波变换(AdaWAT):用于将多模态图像分解为高频和低频分量。2) 空域-频域Mamba块:在空域和频域上进行特征融合,增强模型对不同模态特征的动态调整能力。3) 融合层:将融合后的特征进行重构,得到最终的融合图像。整体流程是先通过AdaWAT进行频率解耦,然后利用Mamba块进行跨域融合,最后通过融合层得到融合结果。
关键创新:论文的关键创新在于:1) 提出了自适应近似小波变换(AdaWAT),能够自适应地分离不同模态图像的频率分量,实现更精细的特征提取和对齐。2) 引入了空域-频域Mamba块,能够在空域和频域上进行特征融合,增强模型对不同模态特征的动态调整能力。与现有方法相比,AdaSFFuse能够更好地保留高频细节,并提高模型的泛化能力。
关键设计:AdaWAT采用可学习的滤波器进行小波变换,通过训练数据自适应地调整滤波器的参数。Mamba块采用选择性状态空间模型,能够动态地调整模型对不同模态特征的关注度。损失函数包括像素级损失、结构相似性损失和梯度损失,以保证融合结果在像素、结构和梯度上与原始图像保持一致。
🖼️ 关键图片


📊 实验亮点
实验结果表明,AdaSFFuse在红外-可见光图像融合、多焦点图像融合、多曝光图像融合和医学图像融合等四个任务上均取得了优异的性能。例如,在红外-可见光图像融合任务中,AdaSFFuse在多个指标上超越了现有方法,结构相似性(SSIM)指标平均提升了2%以上,同时保持了较低的计算成本和紧凑的网络结构。
🎯 应用场景
该研究成果可广泛应用于遥感图像融合、医学图像融合、多焦点图像融合和多曝光图像融合等领域。在遥感领域,可以提升地物识别和环境监测的精度;在医学领域,可以辅助医生进行更准确的疾病诊断;在机器人领域,可以提高机器人对复杂环境的感知能力。该研究具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Multimodal Image Fusion (MMIF) aims to integrate complementary information from different imaging modalities to overcome the limitations of individual sensors. It enhances image quality and facilitates downstream applications such as remote sensing, medical diagnostics, and robotics. Despite significant advancements, current MMIF methods still face challenges such as modality misalignment, high-frequency detail destruction, and task-specific limitations. To address these challenges, we propose AdaSFFuse, a novel framework for task-generalized MMIF through adaptive cross-domain co-fusion learning. AdaSFFuse introduces two key innovations: the Adaptive Approximate Wavelet Transform (AdaWAT) for frequency decoupling, and the Spatial-Frequency Mamba Blocks for efficient multimodal fusion. AdaWAT adaptively separates the high- and low-frequency components of multimodal images from different scenes, enabling fine-grained extraction and alignment of distinct frequency characteristics for each modality. The Spatial-Frequency Mamba Blocks facilitate cross-domain fusion in both spatial and frequency domains, enhancing this process. These blocks dynamically adjust through learnable mappings to ensure robust fusion across diverse modalities. By combining these components, AdaSFFuse improves the alignment and integration of multimodal features, reduces frequency loss, and preserves critical details. Extensive experiments on four MMIF tasks -- Infrared-Visible Image Fusion (IVF), Multi-Focus Image Fusion (MFF), Multi-Exposure Image Fusion (MEF), and Medical Image Fusion (MIF) -- demonstrate AdaSFFuse's superior fusion performance, ensuring both low computational cost and a compact network, offering a strong balance between performance and efficiency. The code will be publicly available at https://github.com/Zhen-yu-Liu/AdaSFFuse.