Enhancing Novel View Synthesis from extremely sparse views with SfM-free 3D Gaussian Splatting Framework
作者: Zongqi He, Hanmin Li, Kin-Chung Chan, Yushen Zuo, Hao Xie, Zhe Xiao, Jun Xiao, Kin-Man Lam
分类: cs.CV
发布日期: 2025-08-21
备注: 13 pages, 4 figures
💡 一句话要点
提出一种无需SfM的3D高斯溅射框架,用于从极稀疏视图中增强新视角合成效果
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 新视角合成 3D高斯溅射 稀疏视图 运动结构恢复 相机姿态估计 密集立体匹配 几何正则化
📋 核心要点
- 现有3DGS方法依赖于SfM进行初始化,但在极稀疏视图下,SfM无法准确重建场景几何结构,导致渲染质量下降。
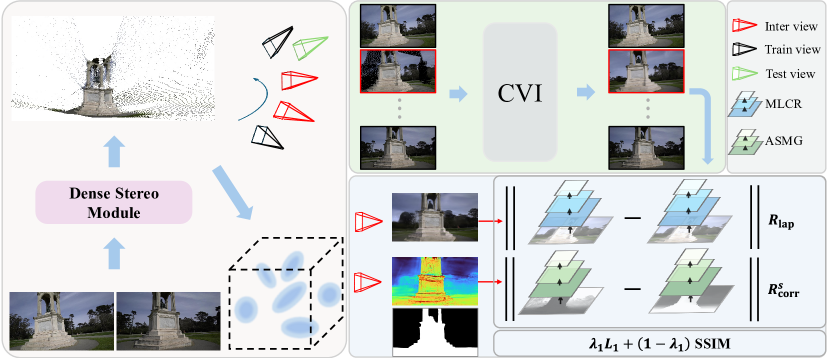
- 提出一种无需SfM的3DGS框架,通过密集立体模块初始化相机姿态和点云,并利用视图插值模块生成额外的监督信号。
- 实验结果表明,该方法在极稀疏视图条件下显著优于现有方法,PSNR提升高达2.75dB,并能生成高质量的渲染图像。
📝 摘要(中文)
3D高斯溅射(3DGS)在新视角合成中表现出卓越的实时性能,但其有效性严重依赖于具有精确已知相机姿态的密集多视图输入,这在现实场景中很少可用。当输入视图变得极其稀疏时,3DGS依赖于运动结构恢复(SfM)方法进行初始化,但该方法无法准确重建场景的3D几何结构,导致渲染质量下降。本文提出了一种新的基于3DGS的无SfM方法,该方法可以从极稀疏视图输入中联合估计相机姿态并重建3D场景。具体来说,我们提出了一种密集立体模块,以逐步估计相机姿态信息并重建全局密集点云以进行初始化,而不是使用SfM。为了解决极稀疏视图设置中固有的信息稀缺问题,我们提出了一种连贯的视图插值模块,该模块基于训练视图对插值相机姿态,并生成视点一致的内容作为额外的训练监督信号。此外,我们引入了多尺度拉普拉斯一致性正则化和自适应空间感知多尺度几何正则化,以提高几何结构和渲染内容的质量。实验表明,我们的方法明显优于其他最先进的基于3DGS的方法,在极稀疏视图条件下(仅使用2个训练视图)实现了显着的2.75dB PSNR提升。我们的方法合成的图像表现出最小的失真,同时保留了丰富的高频细节,从而产生了优于现有技术的视觉质量。
🔬 方法详解
问题定义:论文旨在解决从极稀疏视图中进行高质量新视角合成的问题。现有基于3DGS的方法依赖于SfM进行初始化,但在极稀疏视图下,SfM无法准确估计相机姿态和重建场景的3D几何结构,导致渲染质量显著下降。因此,如何在极稀疏视图下实现鲁棒且高质量的新视角合成是本论文要解决的核心问题。
核心思路:论文的核心思路是摆脱对SfM的依赖,直接从极稀疏视图中联合估计相机姿态和重建3D场景。通过引入密集立体模块进行初始化,并利用视图插值模块生成额外的监督信号,从而克服信息稀疏带来的挑战。此外,还引入了几何正则化方法来提升重建质量。
技术框架:该方法主要包含以下几个模块:1) 密集立体模块:用于从极稀疏视图中逐步估计相机姿态并重建全局密集点云,作为3DGS的初始化。2) 连贯视图插值模块:基于训练视图对插值相机姿态,并生成视点一致的内容作为额外的监督信号。3) 3DGS优化:利用初始化后的相机姿态和点云,以及额外的监督信号,优化3DGS参数,生成高质量的新视角图像。4) 多尺度几何正则化:引入多尺度拉普拉斯一致性正则化和自适应空间感知多尺度几何正则化,以提高几何结构和渲染内容的质量。
关键创新:该方法最重要的创新点在于提出了一个无需SfM的3DGS框架,能够直接从极稀疏视图中进行新视角合成。与现有方法相比,该方法不再依赖于SfM的初始化结果,从而避免了SfM在极稀疏视图下失效的问题。此外,视图插值模块和几何正则化方法也为提升重建质量做出了重要贡献。
关键设计:密集立体模块的具体实现细节(例如使用的立体匹配算法、深度图融合策略等)未知。视图插值模块如何保证视点一致性以及具体的插值策略未知。多尺度拉普拉斯一致性正则化和自适应空间感知多尺度几何正则化的具体公式和参数设置未知。损失函数的设计也未知,例如如何平衡不同模块的损失权重。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在极稀疏视图条件下显著优于其他基于3DGS的方法。例如,在使用仅2个训练视图的情况下,该方法在PSNR指标上实现了高达2.75dB的提升。此外,该方法合成的图像具有更少的失真,并保留了更丰富的高频细节,从而获得了更好的视觉质量。这些结果充分证明了该方法在极稀疏视图新视角合成方面的优越性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实、增强现实等领域。在这些领域中,往往难以获取密集的图像数据,而该方法能够在极稀疏视图下实现高质量的新视角合成,从而降低了数据采集成本,提高了系统的鲁棒性和适应性。未来,该方法有望进一步推广到更大规模、更复杂的场景中。
📄 摘要(原文)
3D Gaussian Splatting (3DGS) has demonstrated remarkable real-time performance in novel view synthesis, yet its effectiveness relies heavily on dense multi-view inputs with precisely known camera poses, which are rarely available in real-world scenarios. When input views become extremely sparse, the Structure-from-Motion (SfM) method that 3DGS depends on for initialization fails to accurately reconstruct the 3D geometric structures of scenes, resulting in degraded rendering quality. In this paper, we propose a novel SfM-free 3DGS-based method that jointly estimates camera poses and reconstructs 3D scenes from extremely sparse-view inputs. Specifically, instead of SfM, we propose a dense stereo module to progressively estimates camera pose information and reconstructs a global dense point cloud for initialization. To address the inherent problem of information scarcity in extremely sparse-view settings, we propose a coherent view interpolation module that interpolates camera poses based on training view pairs and generates viewpoint-consistent content as additional supervision signals for training. Furthermore, we introduce multi-scale Laplacian consistent regularization and adaptive spatial-aware multi-scale geometry regularization to enhance the quality of geometrical structures and rendered content. Experiments show that our method significantly outperforms other state-of-the-art 3DGS-based approaches, achieving a remarkable 2.75dB improvement in PSNR under extremely sparse-view conditions (using only 2 training views). The images synthesized by our method exhibit minimal distortion while preserving rich high-frequency details, resulting in superior visual quality compared to existing techniques.