From Linearity to Non-Linearity: How Masked Autoencoders Capture Spatial Correlations
作者: Anthony Bisulco, Rahul Ramesh, Randall Balestriero, Pratik Chaudhari
分类: cs.CV
发布日期: 2025-08-21
💡 一句话要点
研究MAE如何捕获空间相关性,揭示超参数与下游任务性能的关联。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 掩码自编码器 空间相关性 自监督学习 视觉表征学习 超参数优化
📋 核心要点
- 现有MAE方法在应用于新数据集时,需要大量超参数调整,缺乏对超参数选择的理论指导。
- 论文通过分析线性与非线性MAE,揭示了掩码比例和patch大小等超参数如何影响MAE学习空间相关性。
- 研究表明,MAE表示能够适应数据集中的空间相关性,并为实践中选择MAE超参数提供了一些见解。
📝 摘要(中文)
掩码自编码器(MAE)已成为视觉基础模型强大的预训练技术。尽管有效,但应用于新数据集时,需要大量的超参数调整(掩码比例、patch大小、编码器/解码器层)。虽然之前的理论工作从注意力模式和分层潜在变量模型的角度分析了MAE,但MAE超参数与下游任务性能之间的联系相对未被探索。本文研究了MAE如何学习输入图像中的空间相关性。我们分析推导了线性MAE学习的特征,并表明掩码比例和patch大小可用于选择捕获短程和长程空间相关性的特征。我们将此分析扩展到非线性MAE,以表明MAE表示适应数据集中的空间相关性,超出二阶统计量。最后,我们讨论了关于如何在实践中选择MAE超参数的一些见解。
🔬 方法详解
问题定义:现有的掩码自编码器(MAE)虽然在视觉表征学习中表现出色,但其超参数(如掩码比例、patch大小)的选择缺乏理论指导,导致在应用于新的数据集时需要大量的超参数调优。现有研究主要集中在分析MAE的注意力模式或将其视为分层潜在变量模型,而忽略了超参数与下游任务性能之间的直接联系。因此,如何理解MAE学习到的空间相关性,以及如何根据数据集的特性选择合适的超参数,是本文要解决的关键问题。
核心思路:本文的核心思路是通过分析线性MAE学习到的特征,揭示掩码比例和patch大小如何影响MAE捕获短程和长程空间相关性的能力。然后,将此分析扩展到非线性MAE,以理解MAE如何适应数据集中的空间相关性,并最终为超参数选择提供指导。这种从线性到非线性的分析方法,有助于理解复杂模型的工作机制。
技术框架:本文的技术框架主要包括以下几个部分:1) 分析线性MAE学习到的特征,推导出特征与掩码比例、patch大小之间的关系;2) 将分析结果扩展到非线性MAE,研究其如何适应数据集的空间相关性;3) 基于理论分析,提出超参数选择的实践建议。整个框架旨在建立超参数、空间相关性和下游任务性能之间的联系。
关键创新:本文最重要的技术创新点在于,它从理论上揭示了MAE的超参数(掩码比例和patch大小)与模型学习到的空间相关性之间的关系。具体来说,论文证明了通过调整这些超参数,可以选择性地让MAE关注短程或长程的空间相关性。这种对MAE内部机制的深入理解,为超参数选择提供了理论依据,避免了盲目的调参过程。
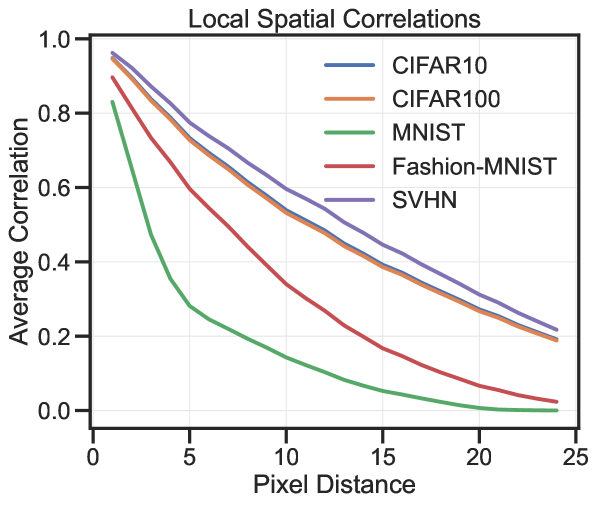
关键设计:在线性MAE的分析中,论文推导了特征与超参数之间的数学关系。在非线性MAE的分析中,论文通过实验验证了MAE能够适应数据集的空间相关性。此外,论文还讨论了在实践中如何根据数据集的特性选择合适的掩码比例和patch大小,例如,对于包含大量长程依赖关系的数据集,应该选择更大的patch大小。
🖼️ 关键图片


📊 实验亮点
论文通过理论分析和实验验证,揭示了MAE的超参数(掩码比例和patch大小)与模型学习到的空间相关性之间的关系。研究表明,通过调整这些超参数,可以选择性地让MAE关注短程或长程的空间相关性。此外,论文还为实践中选择MAE超参数提供了一些有价值的见解,例如,对于包含大量长程依赖关系的数据集,应该选择更大的patch大小。
🎯 应用场景
该研究成果可应用于各种计算机视觉任务,例如图像分类、目标检测和语义分割。通过理解MAE如何学习空间相关性,可以更好地设计和优化视觉基础模型,提高模型在各种下游任务上的性能。此外,该研究还可以帮助研究人员更好地理解自监督学习的机制,并为其他自监督学习方法的设计提供借鉴。
📄 摘要(原文)
Masked Autoencoders (MAEs) have emerged as a powerful pretraining technique for vision foundation models. Despite their effectiveness, they require extensive hyperparameter tuning (masking ratio, patch size, encoder/decoder layers) when applied to novel datasets. While prior theoretical works have analyzed MAEs in terms of their attention patterns and hierarchical latent variable models, the connection between MAE hyperparameters and performance on downstream tasks is relatively unexplored. This work investigates how MAEs learn spatial correlations in the input image. We analytically derive the features learned by a linear MAE and show that masking ratio and patch size can be used to select for features that capture short- and long-range spatial correlations. We extend this analysis to non-linear MAEs to show that MAE representations adapt to spatial correlations in the dataset, beyond second-order statistics. Finally, we discuss some insights on how to select MAE hyper-parameters in practice.