Adversarial Agent Behavior Learning in Autonomous Driving Using Deep Reinforcement Learning
作者: Arjun Srinivasan, Anubhav Paras, Aniket Bera
分类: cs.CV
发布日期: 2025-08-21
💡 一句话要点
提出基于深度强化学习的对抗性Agent行为学习方法,用于提升自动驾驶安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 深度强化学习 对抗性学习 行为建模 安全验证
📋 核心要点
- 现有强化学习方法在自动驾驶等安全关键场景中,对周围Agent的建模不足,可能导致安全隐患。
- 该论文提出一种学习方法,通过深度强化学习训练对抗性Agent,使其能够诱导基于规则的Agent产生失效行为。
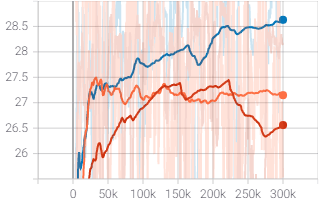
- 实验结果表明,对抗性Agent能够有效降低基于规则的Agent的累积奖励,验证了其发现潜在风险的能力。
📝 摘要(中文)
本文提出了一种基于学习的方法,用于推导规则型Agent的对抗性行为,以在自动驾驶场景中引发失效情况。现有的强化学习方法通常训练Agent在具有基于规则的周围Agent的环境中学习期望的最优行为。在自动驾驶等安全关键应用中,对基于规则的Agent进行适当建模至关重要。目前,有几种行为建模策略和IDM模型被用于对周围的Agent进行建模。本文通过对抗性Agent与所有基于规则的Agent进行对抗,并展示了累积奖励的降低,以此来评估对抗性Agent的有效性。
🔬 方法详解
问题定义:现有的自动驾驶强化学习方法通常假设周围车辆遵循预定义的规则(例如IDM模型)。然而,这些规则可能无法完全捕捉真实世界中驾驶员的复杂行为,导致训练出的自动驾驶系统在面对极端或对抗性场景时表现不佳。因此,如何有效地建模周围车辆的潜在危险行为,并提升自动驾驶系统的鲁棒性,是一个关键问题。
核心思路:本文的核心思路是训练一个对抗性Agent,该Agent的目标是最大化自动驾驶系统的失败概率或最小化其累积奖励。通过让对抗性Agent与自动驾驶系统进行博弈,可以有效地发现自动驾驶系统中的潜在弱点,并促使其学习更安全的驾驶策略。这种方法类似于生成对抗网络(GAN)的思想,但应用于强化学习领域。
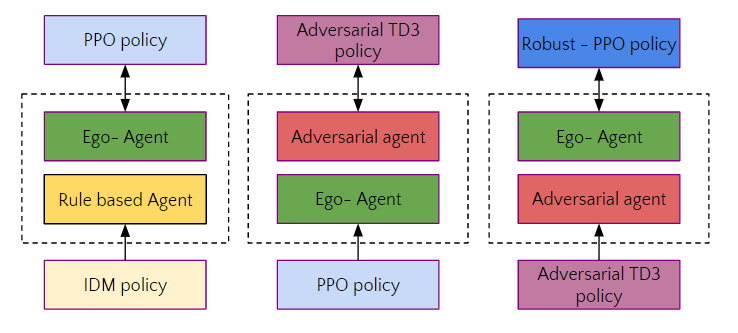
技术框架:整体框架包含两个Agent:自动驾驶Agent(被评估的Agent)和对抗性Agent。自动驾驶Agent的目标是安全高效地完成驾驶任务,而对抗性Agent的目标是干扰自动驾驶Agent,使其发生碰撞或偏离期望轨迹。对抗性Agent通过深度强化学习进行训练,其输入是环境状态(例如车辆位置、速度等),输出是对周围车辆的控制指令。训练过程中,两个Agent不断交互,对抗性Agent逐渐学习到如何有效地诱导自动驾驶Agent产生不良行为。
关键创新:该论文的关键创新在于将对抗性学习的思想引入到自动驾驶Agent的训练中,通过学习对抗性Agent的行为来发现和解决自动驾驶系统中的潜在问题。与传统的基于规则的交通模型相比,该方法能够更有效地捕捉真实世界中驾驶员的复杂和不可预测的行为,从而提升自动驾驶系统的鲁棒性和安全性。
关键设计:对抗性Agent使用深度强化学习算法(具体算法未知,原文未提及)进行训练。奖励函数的设计至关重要,需要能够有效地引导对抗性Agent学习到能够诱导自动驾驶Agent产生不良行为的策略。具体的奖励函数设计细节未知,但可能包括碰撞惩罚、偏离期望轨迹的惩罚等。网络结构也未知,但推测会采用深度神经网络来拟合复杂的策略函数。
🖼️ 关键图片
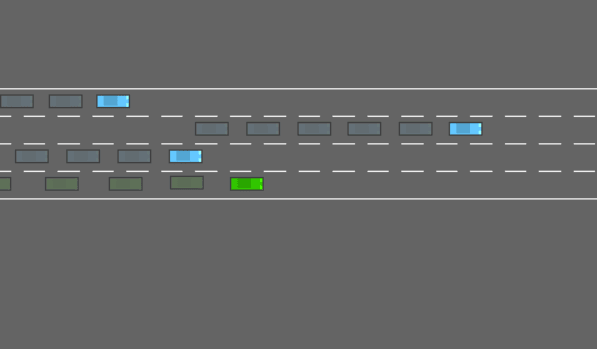
📊 实验亮点
论文通过实验证明,对抗性Agent能够有效地降低基于规则的Agent的累积奖励,表明其能够成功地诱导Agent进入危险状态。具体的性能数据和对比基线未知,但结果表明该方法在发现自动驾驶系统潜在风险方面具有潜力。未来的工作可以进一步量化对抗性Agent对自动驾驶系统性能的影响,并与其他安全验证方法进行比较。
🎯 应用场景
该研究成果可应用于自动驾驶系统的安全测试与验证,通过对抗性Agent发现潜在的安全漏洞。此外,该方法还可以用于提升自动驾驶系统的鲁棒性,使其在面对复杂和不可预测的交通环境时能够更加安全可靠地运行。未来,该技术有望应用于自动驾驶仿真平台,为自动驾驶算法的开发和测试提供更有效的工具。
📄 摘要(原文)
Existing approaches in reinforcement learning train an agent to learn desired optimal behavior in an environment with rule based surrounding agents. In safety critical applications such as autonomous driving it is crucial that the rule based agents are modelled properly. Several behavior modelling strategies and IDM models are used currently to model the surrounding agents. We present a learning based method to derive the adversarial behavior for the rule based agents to cause failure scenarios. We evaluate our adversarial agent against all the rule based agents and show the decrease in cumulative reward.