Advancing 3D Scene Understanding with MV-ScanQA Multi-View Reasoning Evaluation and TripAlign Pre-training Dataset
作者: Wentao Mo, Qingchao Chen, Yuxin Peng, Siyuan Huang, Yang Liu
分类: cs.CV, cs.MM
发布日期: 2025-08-14
备注: Accepeted to ACM MM 25
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出MV-ScanQA和TripAlign,促进多视角3D场景理解和推理
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 多视角推理 视觉-语言学习 数据集构建 预训练 多模态对齐
📋 核心要点
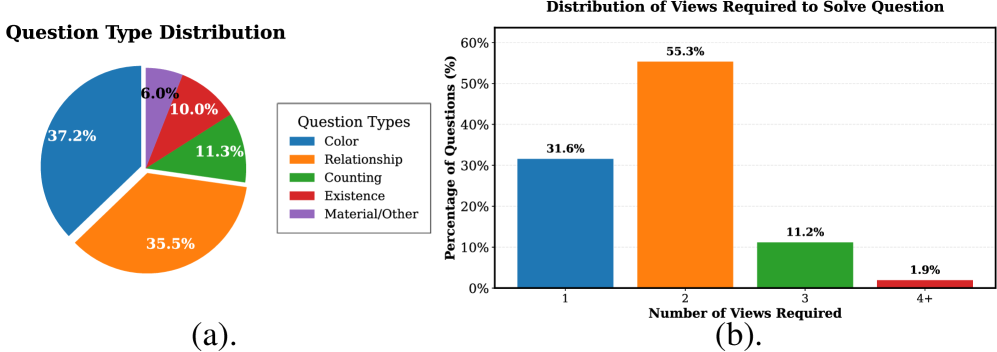
- 现有3D视觉-语言数据集缺乏对多视角、远距离物体间关系推理的有效支持,限制了模型对复杂场景的理解能力。
- 论文提出MV-ScanQA数据集,侧重多视角组合推理,并构建TripAlign数据集进行2D-3D-语言预训练,增强模型的多模态对齐能力。
- 提出的LEGO模型利用TripAlign进行预训练,在MV-ScanQA及其他3D任务上取得了SOTA性能,验证了方法的有效性。
📝 摘要(中文)
现有的3D视觉-语言(3D VL)数据集存在局限性,它们很少需要对单视点中近距离物体之外进行推理,并且注释通常将指令链接到单个物体,缺少多个物体之间更丰富的上下文对齐。这极大地限制了能够对远处物体进行深度多视角3D场景理解的模型的开发。为了解决这些挑战,我们引入了MV-ScanQA,这是一个新的3D问答数据集,其中68%的问题明确要求整合来自多个视角的信息(而现有数据集中不到7%),从而严格测试多视角组合推理。为了方便训练模型以应对这种苛刻的场景,我们提出了TripAlign数据集,这是一个大规模且低成本的2D-3D-语言预训练语料库,包含100万个<2D视图,3D物体集合,文本>三元组,这些三元组明确地将上下文相关的物体组与文本对齐,提供了比以前的单物体注释更丰富的、基于视图的多物体多模态对齐信号。我们进一步开发了LEGO,这是一种用于MV-ScanQA中多视角推理挑战的基线方法,通过TripAlign将来自预训练的2D LVLM的知识转移到3D领域。经验表明,在TripAlign上预训练的LEGO不仅在提出的MV-ScanQA上实现了最先进的性能,而且在现有的3D密集字幕和问答基准上也实现了最先进的性能。数据集和代码可在https://matthewdm0816.github.io/tripalign-mvscanqa获得。
🔬 方法详解
问题定义:现有3D视觉-语言模型在理解复杂3D场景时面临挑战,主要原因是现有数据集的标注方式侧重于单视角、近距离的物体,缺乏对多视角信息融合和物体间上下文关系的建模。这导致模型难以进行深层次的推理和理解。
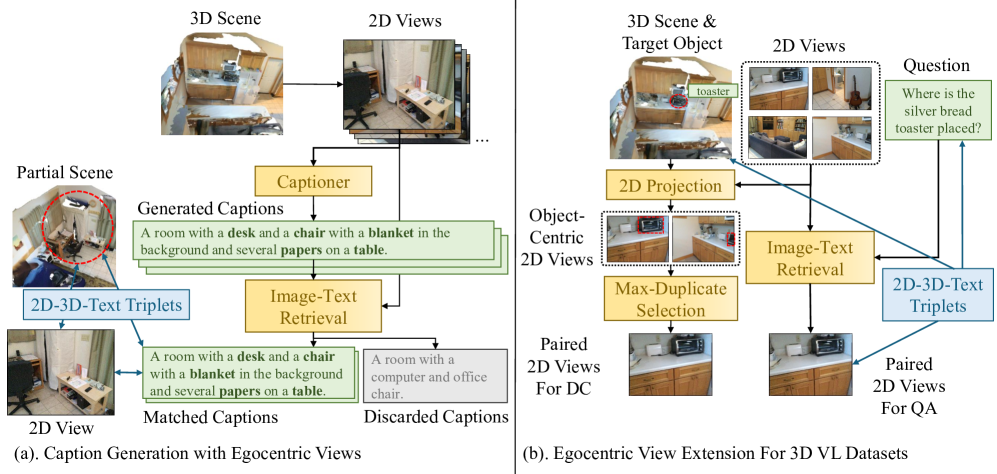
核心思路:论文的核心思路是通过构建新的数据集和预训练方法,显式地引导模型学习多视角信息融合和物体间关系推理。MV-ScanQA数据集的设计侧重于需要整合多个视角信息的问答,而TripAlign数据集则提供了大规模的2D-3D-语言对齐数据,用于预训练模型。
技术框架:整体框架包含两个主要部分:数据集构建和模型训练。首先,构建MV-ScanQA数据集,其中大部分问题需要整合多个视角的信息才能回答。其次,构建TripAlign数据集,包含2D图像、3D物体集合和文本描述的三元组,用于预训练模型。最后,提出LEGO模型,利用TripAlign进行预训练,并将知识迁移到MV-ScanQA任务上。
关键创新:论文的关键创新在于提出了MV-ScanQA和TripAlign两个数据集,以及利用TripAlign进行预训练的LEGO模型。MV-ScanQA数据集的创新之处在于其问题设计侧重于多视角推理,而TripAlign数据集的创新之处在于其大规模的2D-3D-语言对齐数据,可以有效地提升模型的多模态理解能力。LEGO模型则通过预训练的方式,将知识从2D领域迁移到3D领域。
关键设计:TripAlign数据集的关键设计在于其三元组的构建方式,即<2D view, set of 3D objects, text>。这种设计使得模型可以学习到2D图像、3D物体和文本之间的对应关系,从而提升模型的多模态理解能力。LEGO模型的关键设计在于其利用预训练的2D LVLM,并将知识迁移到3D领域。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在TripAlign上预训练的LEGO模型在MV-ScanQA数据集上取得了SOTA性能,并且在现有的3D密集字幕和问答基准上也取得了显著的提升。具体的数据提升幅度在论文中进行了详细的展示(未知)。这些结果验证了论文提出的数据集和预训练方法的有效性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能家居等领域。通过提升模型对3D场景的理解和推理能力,可以使机器人更好地感知周围环境,从而实现更智能的交互和决策。未来,该研究可以进一步扩展到更复杂的场景和任务中,例如3D场景编辑、虚拟现实等。
📄 摘要(原文)
The advancement of 3D vision-language (3D VL) learning is hindered by several limitations in existing 3D VL datasets: they rarely necessitate reasoning beyond a close range of objects in single viewpoint, and annotations often link instructions to single objects, missing richer contextual alignments between multiple objects. This significantly curtails the development of models capable of deep, multi-view 3D scene understanding over distant objects. To address these challenges, we introduce MV-ScanQA, a novel 3D question answering dataset where 68% of questions explicitly require integrating information from multiple views (compared to less than 7% in existing datasets), thereby rigorously testing multi-view compositional reasoning. To facilitate the training of models for such demanding scenarios, we present TripAlign dataset, a large-scale and low-cost 2D-3D-language pre-training corpus containing 1M <2D view, set of 3D objects, text> triplets that explicitly aligns groups of contextually related objects with text, providing richer, view-grounded multi-object multimodal alignment signals than previous single-object annotations. We further develop LEGO, a baseline method for the multi-view reasoning challenge in MV-ScanQA, transferring knowledge from pre-trained 2D LVLMs to 3D domain with TripAlign. Empirically, LEGO pre-trained on TripAlign achieves state-of-the-art performance not only on the proposed MV-ScanQA, but also on existing benchmarks for 3D dense captioning and question answering. Datasets and code are available at https://matthewdm0816.github.io/tripalign-mvscanqa.