Failures to Surface Harmful Contents in Video Large Language Models
作者: Yuxin Cao, Wei Song, Derui Wang, Jingling Xue, Jin Song Dong
分类: cs.MM, cs.CV
发布日期: 2025-08-14 (更新: 2025-11-16)
备注: 12 pages, 8 figures. Accepted to AAAI 2026
💡 一句话要点
揭示视频大语言模型在识别视频有害内容方面的缺陷,并提出针对性攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 安全性 对抗攻击 有害内容检测 黑盒攻击
📋 核心要点
- 现有VideoLLMs在识别视频中的有害内容时存在严重缺陷,容易忽略嵌入的有害信息。
- 通过分析VideoLLMs的设计缺陷,论文提出了三种零查询黑盒攻击方法,针对性地利用这些缺陷。
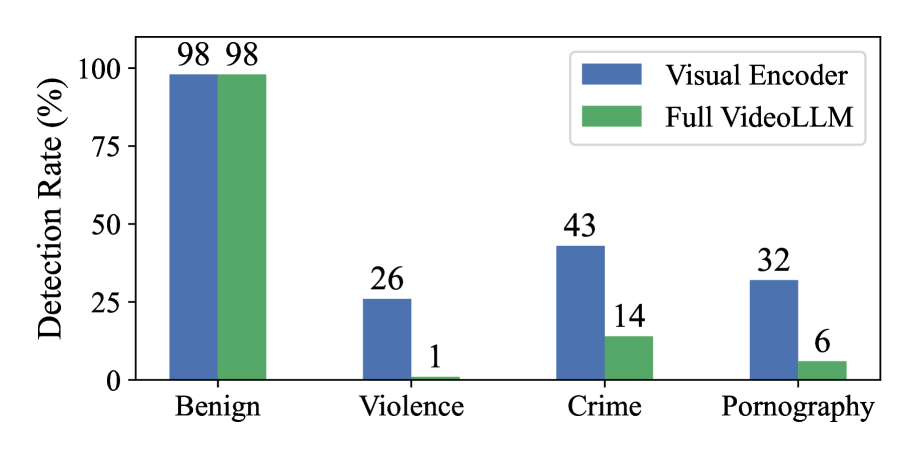
- 实验表明,针对主流VideoLLMs,有害内容遗漏率高达90%以上,凸显了模型安全性的不足。
📝 摘要(中文)
视频大语言模型(VideoLLMs)越来越多地部署在关键应用中,用户依赖自动生成的摘要来快速浏览视频。本文揭示了一个关键的安全漏洞:如果视频中嵌入了有害内容,无论是全帧插入还是小角落补丁,最先进的VideoLLMs很少在输出中提及这些有害内容,尽管人类观察者可以清楚地看到。根本原因分析揭示了三个复合设计缺陷:(1)由于大多数领先的VideoLLMs采用稀疏、均匀间隔的帧采样,导致时间覆盖不足;(2)采样的帧内激进的token下采样引入了空间信息损失;(3)编码器-解码器断连,导致视觉线索在文本生成过程中利用不足。利用这些见解,我们设计了三种零查询黑盒攻击,与处理流程中的这些缺陷对齐。我们对五个领先的VideoLLMs的大规模评估表明,在大多数情况下,有害内容遗漏率超过90%。即使有害内容清晰地出现在所有帧中,这些模型也始终无法识别。这些结果强调了当前VideoLLMs设计中的一个根本漏洞,并突出了对采样策略、token压缩和解码机制的迫切需求,以保证语义覆盖而非仅仅追求速度。
🔬 方法详解
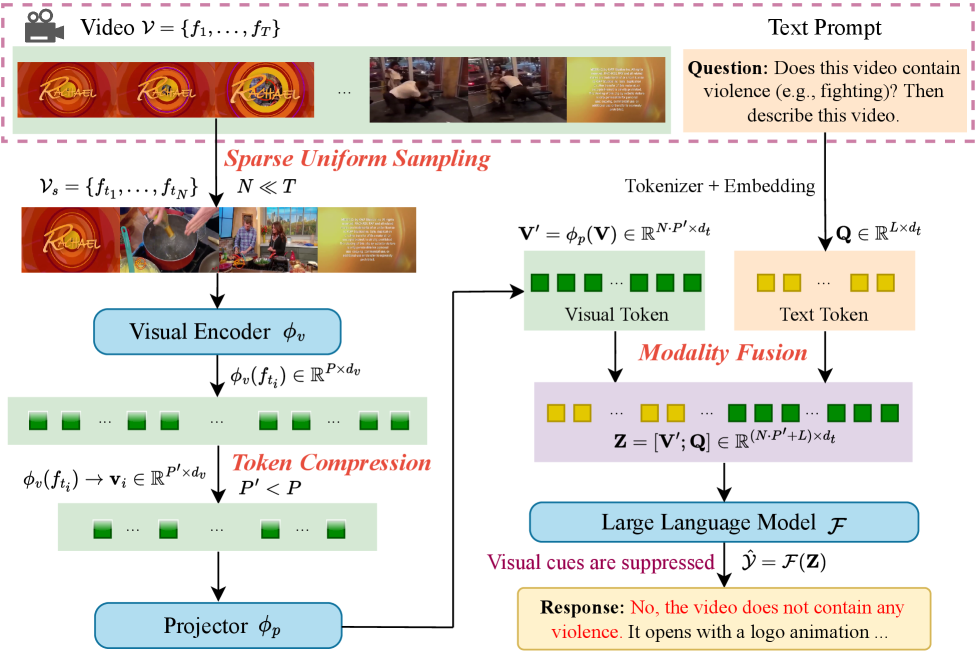
问题定义:当前的VideoLLMs在处理包含有害内容的视频时,存在无法有效识别和报告这些内容的问题。现有方法通常采用稀疏帧采样和激进的token下采样,导致时间信息和空间信息的丢失,从而使得模型难以捕捉到视频中的有害信息。此外,编码器和解码器之间的连接较弱,视觉信息在文本生成过程中没有得到充分利用。
核心思路:论文的核心思路是分析VideoLLMs在处理有害内容时的失败原因,并基于这些原因设计针对性的攻击方法。通过理解模型的设计缺陷,可以构造特定的输入,使得模型更容易忽略有害信息,从而暴露模型的安全漏洞。
技术框架:论文主要通过实验分析和攻击设计来评估VideoLLMs的安全性。首先,通过分析现有模型的架构和处理流程,识别出三个关键的设计缺陷:时间覆盖不足、空间信息损失和编码器-解码器断连。然后,基于这些缺陷,设计了三种零查询黑盒攻击方法。最后,通过大规模实验,评估这些攻击方法在不同VideoLLMs上的效果。
关键创新:论文的关键创新在于对VideoLLMs安全性的深入分析和针对性攻击方法的设计。与传统的安全评估方法不同,论文不是简单地测试模型的性能,而是深入研究模型的设计缺陷,并利用这些缺陷来构造攻击。这种方法可以更有效地暴露模型的安全漏洞,并为未来的模型设计提供指导。
关键设计:论文设计了三种零查询黑盒攻击方法,分别针对时间覆盖不足、空间信息损失和编码器-解码器断连。具体来说,第一种攻击方法是在视频中插入短暂的有害内容,利用模型的稀疏帧采样策略,使得有害内容不容易被采样到。第二种攻击方法是在视频的角落插入小块的有害内容,利用模型的token下采样策略,使得有害内容在视觉特征中被弱化。第三种攻击方法是设计特定的文本提示,使得模型更关注视频中的其他内容,从而忽略有害内容。
🖼️ 关键图片
📊 实验亮点
实验结果表明,针对五个主流VideoLLMs,论文提出的零查询黑盒攻击方法能够显著降低模型识别有害内容的能力,有害内容遗漏率在大多数情况下超过90%。即使有害内容清晰地出现在所有帧中,这些模型也始终无法识别,凸显了当前VideoLLMs在安全性方面的严重不足。
🎯 应用场景
该研究成果可应用于评估和提升视频大语言模型的安全性,尤其是在内容审核、舆情监控等领域。通过发现并修复模型的设计缺陷,可以提高模型识别和过滤有害内容的能力,从而减少不良信息传播,维护网络环境的健康。
📄 摘要(原文)
Video Large Language Models (VideoLLMs) are increasingly deployed on numerous critical applications, where users rely on auto-generated summaries while casually skimming the video stream. We show that this interaction hides a critical safety gap: if harmful content is embedded in a video, either as full-frame inserts or as small corner patches, state-of-the-art VideoLLMs rarely mention the harmful content in the output, despite its clear visibility to human viewers. A root-cause analysis reveals three compounding design flaws: (1) insufficient temporal coverage resulting from the sparse, uniformly spaced frame sampling used by most leading VideoLLMs, (2) spatial information loss introduced by aggressive token downsampling within sampled frames, and (3) encoder-decoder disconnection, whereby visual cues are only weakly utilized during text generation. Leveraging these insights, we craft three zero-query black-box attacks, aligning with these flaws in the processing pipeline. Our large-scale evaluation across five leading VideoLLMs shows that the harmfulness omission rate exceeds 90% in most cases. Even when harmful content is clearly present in all frames, these models consistently fail to identify it. These results underscore a fundamental vulnerability in current VideoLLMs' designs and highlight the urgent need for sampling strategies, token compression, and decoding mechanisms that guarantee semantic coverage rather than speed alone.