From Diagnosis to Improvement: Probing Spatio-Physical Reasoning in Vision Language Models
作者: Tiancheng Han, Yunfei Gao, Yong Li, Wuzhou Yu, Qiaosheng Zhang, Wenqi Shao
分类: cs.CV
发布日期: 2025-08-14
备注: 9 pages, 6 figures
💡 一句话要点
诊断并改进视觉语言模型中的时空物理推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 时空物理推理 监督微调 强化学习 深度推理 物理世界理解 机器人导航
📋 核心要点
- 现有视觉语言模型在时空物理推理方面表现不足,主要原因是类人先验偏差和缺乏深度推理。
- 论文提出结合监督微调和基于规则的强化学习方法,以提升视觉语言模型在时空物理推理方面的能力。
- 实验结果表明,该方法显著提高了模型的时空物理推理能力,并在特定任务上超越了领先的专有模型。
📝 摘要(中文)
时空物理推理是理解真实物理世界的基础能力,也是构建鲁棒世界模型的关键一步。尽管最近的视觉语言模型(VLMs)在多模态数学和纯空间理解等专业领域取得了显著进展,但它们在时空物理推理方面的能力在很大程度上仍未被探索。本文对主流VLMs进行了全面的诊断分析,揭示了当前模型在该关键任务上的表现不足。进一步的详细分析表明,这种表现不佳主要归因于类人先验造成的偏差和缺乏深度推理。为了应对这些挑战,我们将监督微调和基于规则的强化学习应用于Qwen2.5-VL-7B,从而显著提高了时空物理推理能力,并超越了领先的专有模型。然而,尽管取得了成功,该模型对新物理场景的泛化能力仍然有限——突显了对时空物理推理新方法的迫切需求。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLMs)在时空物理推理方面能力不足的问题。现有VLMs在理解真实物理世界,特别是涉及空间关系和物理规律的场景时,表现不佳。这种不足源于模型学习过程中引入的类人先验偏差,以及缺乏进行深度推理的能力。这些问题限制了VLMs在需要理解和预测物理世界行为的应用中的有效性。
核心思路:论文的核心思路是通过结合监督微调和基于规则的强化学习,来增强VLMs的时空物理推理能力。监督微调用于让模型学习更准确的物理知识,而基于规则的强化学习则鼓励模型进行更深入的推理,从而克服类人先验偏差,提升模型对物理规律的理解和应用能力。
技术框架:论文的技术框架主要包含两个阶段:首先,使用监督微调来训练Qwen2.5-VL-7B模型,使其能够更好地理解和预测物理场景。然后,使用基于规则的强化学习对模型进行进一步优化,以鼓励模型进行更深入的推理。强化学习的目标是最大化模型在时空物理推理任务上的表现,同时避免类人先验偏差的影响。
关键创新:论文的关键创新在于结合了监督微调和基于规则的强化学习,以解决VLMs在时空物理推理方面的不足。与传统的监督学习方法相比,基于规则的强化学习能够更好地引导模型进行深度推理,并克服类人先验偏差的影响。这种结合使得模型能够更准确地理解和预测物理世界的行为。
关键设计:在监督微调阶段,使用了包含时空物理推理任务的数据集对Qwen2.5-VL-7B模型进行训练。在基于规则的强化学习阶段,设计了一系列规则来评估模型在时空物理推理任务上的表现,并根据这些规则来调整模型的参数。具体的损失函数和网络结构细节在论文中进行了详细描述,以确保模型能够有效地学习和应用物理知识。
🖼️ 关键图片

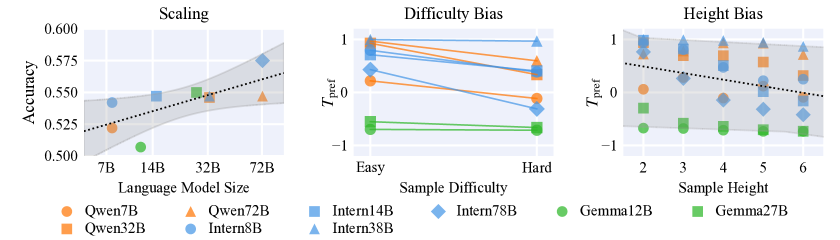
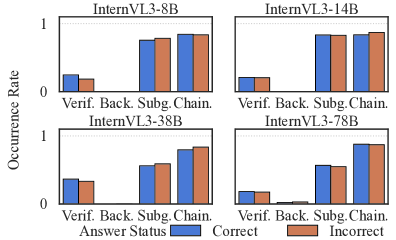
📊 实验亮点
论文通过实验证明,结合监督微调和基于规则的强化学习的方法,能够显著提高Qwen2.5-VL-7B模型在时空物理推理方面的能力。实验结果表明,该方法在特定任务上超越了领先的专有模型,验证了该方法的有效性。然而,模型对新物理场景的泛化能力仍然有限,表明该领域仍有进一步研究的空间。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能家居等领域。通过提升视觉语言模型对时空物理的理解能力,可以使机器人更好地理解周围环境,做出更合理的决策,从而提高其在复杂环境中的适应性和可靠性。此外,该研究也有助于开发更智能的虚拟现实和增强现实应用。
📄 摘要(原文)
Spatio-physical reasoning, a foundation capability for understanding the real physics world, is a critical step towards building robust world models. While recent vision language models (VLMs) have shown remarkable progress in specialized domains like multimodal mathematics and pure spatial understanding, their capability for spatio-physical reasoning remains largely unexplored. This paper provides a comprehensive diagnostic analysis of mainstream VLMs, revealing that current models perform inadequately on this crucial task. Further detailed analysis shows that this underperformance is largely attributable to biases caused by human-like prior and a lack of deep reasoning. To address these challenges, we apply supervised fine-tuning followed by rule-based reinforcement learning to Qwen2.5-VL-7B, resulting in significant improvements in spatio-physical reasoning capabilities and surpassing leading proprietary models. Nevertheless, despite this success, the model's generalization to new physics scenarios remains limited -- underscoring the pressing need for new approaches in spatio-physical reasoning.