Towards Agentic AI for Multimodal-Guided Video Object Segmentation
作者: Tuyen Tran, Thao Minh Le, Truyen Tran
分类: cs.CV
发布日期: 2025-08-14
💡 一句话要点
提出多模态Agent,用于解决多模态引导的视频目标分割任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频目标分割 多模态学习 大型语言模型 Agentic AI 动态工作流
📋 核心要点
- 现有基于指代的视频目标分割方法依赖固定流程,缺乏适应任务动态性的灵活性。
- 本文提出多模态Agent,利用LLM生成动态工作流,与多模态工具交互,自适应地分割目标。
- 实验表明,该方法在RVOS和Ref-AVS任务上优于现有方法,证明了其有效性。
📝 摘要(中文)
本文针对基于指代的视频目标分割(RVOS)这一多模态问题,提出了一种新颖的Agentic系统——多模态Agent,旨在以更灵活和自适应的方式解决该问题。传统方法通常训练专门的模型,计算复杂度高且需要大量手动标注。本文利用大型语言模型(LLM)的推理能力,为每个输入生成动态工作流程,迭代地与一组专门的工具交互,这些工具针对不同模态的底层任务而设计,从而识别多模态线索描述的目标对象。在RVOS和Ref-AVS两个多模态条件下的VOS任务上,该Agentic方法表现出明显优于现有方法的性能。
🔬 方法详解
问题定义:论文旨在解决多模态引导的视频目标分割(RVOS)问题。现有方法主要依赖于训练特定的模型,这不仅需要大量的计算资源和人工标注,而且缺乏灵活性,难以适应视频内容和用户指令的多样性。固定流程的pipeline无法根据不同的输入进行调整,导致分割效果不佳。
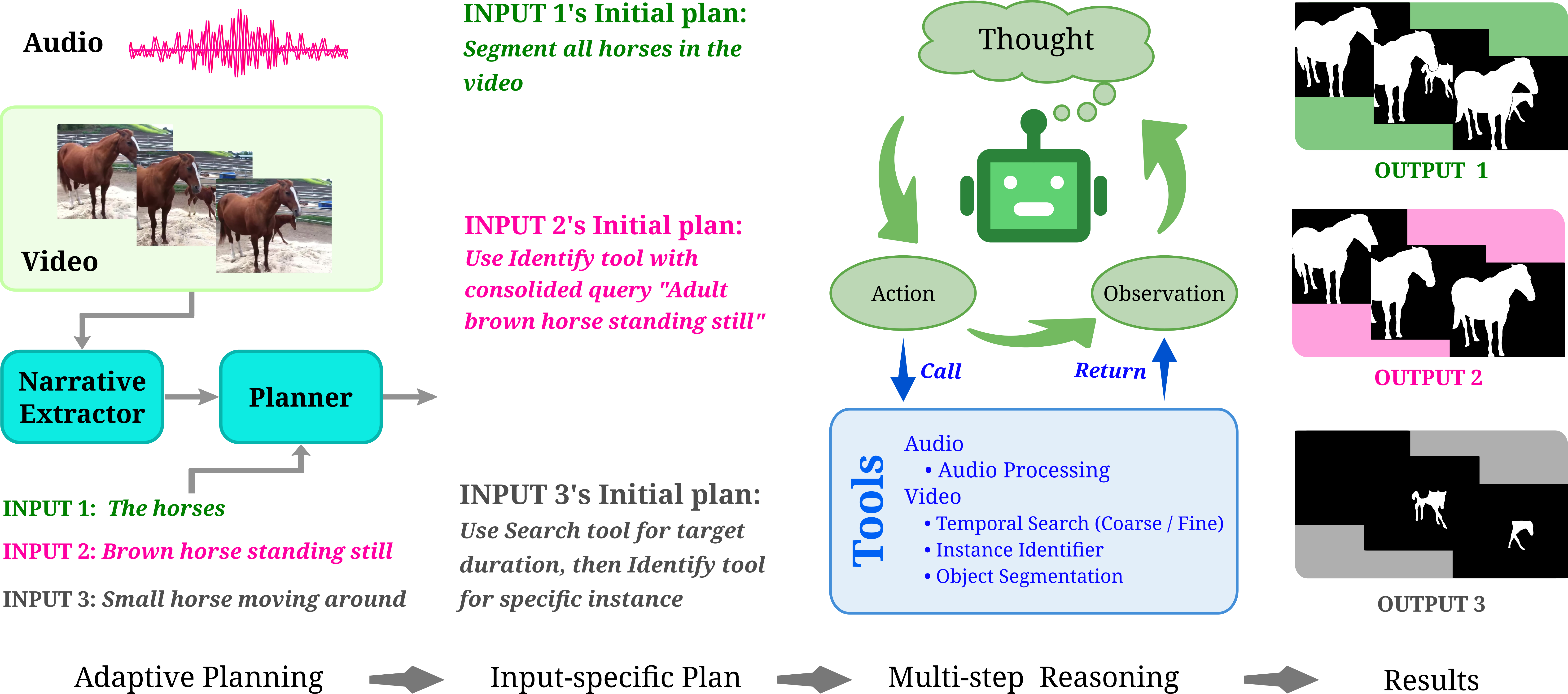
核心思路:论文的核心思路是利用大型语言模型(LLM)作为智能体(Agent),赋予其推理和决策能力,使其能够根据输入的视频内容和用户指令,动态地规划和执行分割任务。通过将复杂的分割任务分解为一系列简单的子任务,并调用不同的专业工具来完成这些子任务,从而实现更灵活和自适应的分割。
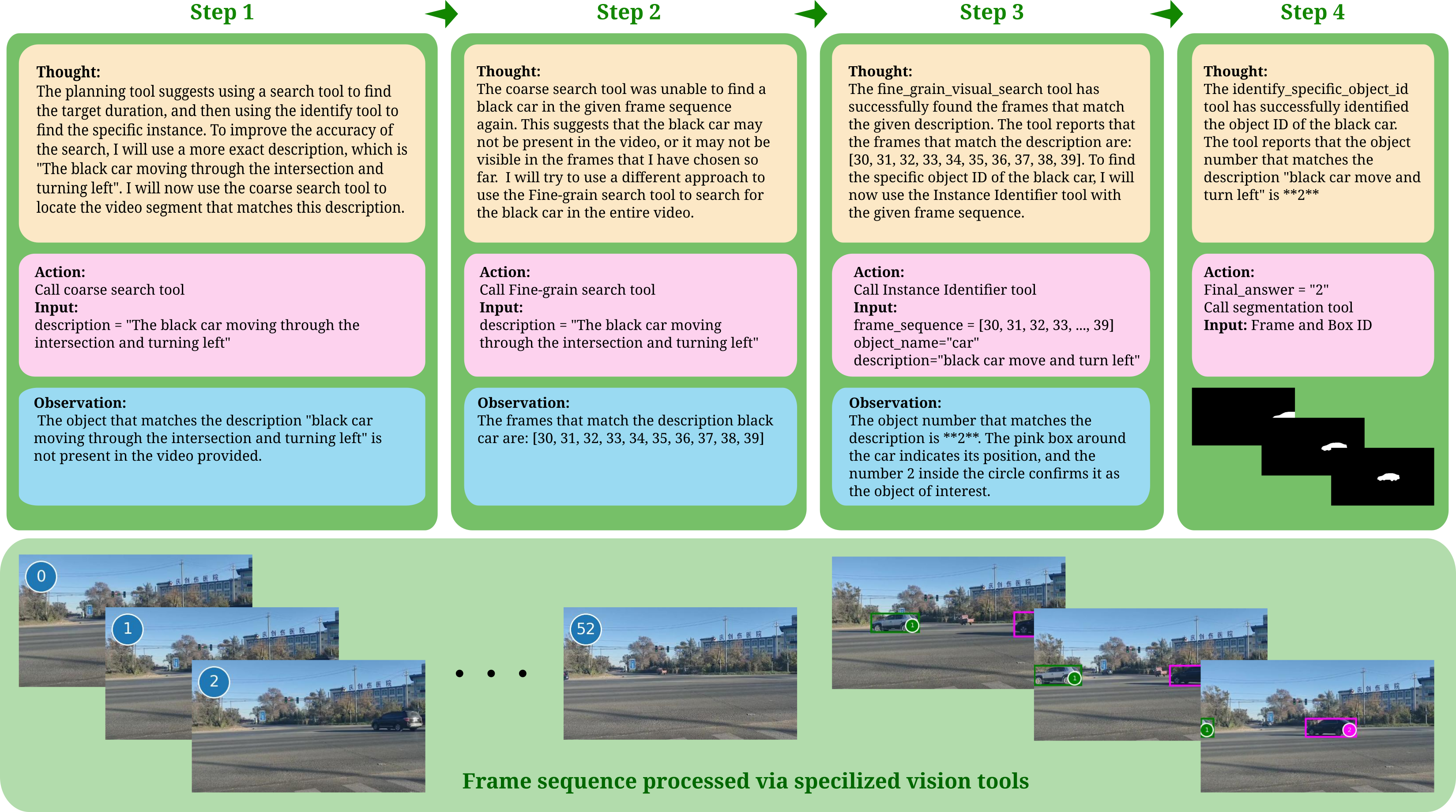
技术框架:整体框架包含以下几个主要模块:1) LLM Agent:作为核心控制器,负责接收输入(视频和指令),分析任务需求,并生成动态的工作流程。2) 多模态工具集:包含一系列专门用于处理不同模态数据的工具,例如,用于目标检测、图像分割、语音识别等。3) 交互循环:LLM Agent根据当前状态和任务需求,选择合适的工具执行,并根据工具的输出结果调整后续的执行策略,形成一个迭代的交互循环,直到完成分割任务。
关键创新:最关键的创新在于将LLM引入到视频目标分割任务中,并将其作为一个智能体来使用。与传统的固定pipeline方法不同,该方法能够根据输入动态地调整分割策略,从而更好地适应视频内容和用户指令的多样性。这种Agentic的设计使得分割过程更加灵活和可解释。
关键设计:论文中关键的设计包括:1) LLM的选择和prompt设计:选择合适的LLM,并设计有效的prompt,以引导LLM生成合理的分割策略。2) 多模态工具集的构建:选择合适的工具,并对其进行优化,以提高其性能和效率。3) 交互循环的设计:设计合理的交互循环,以确保LLM能够有效地利用工具,并最终完成分割任务。具体的参数设置、损失函数、网络结构等技术细节在论文中可能有所涉及,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
该方法在RVOS和Ref-AVS两个多模态条件下的VOS任务上,表现出明显优于现有方法的性能。具体性能数据和提升幅度在摘要中未给出,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于智能视频编辑、自动驾驶、机器人视觉等领域。例如,在智能视频编辑中,可以根据用户的自然语言描述,快速准确地分割出视频中的目标对象,方便用户进行后续的编辑操作。在自动驾驶中,可以用于识别和分割道路上的车辆、行人等目标,提高自动驾驶系统的安全性。
📄 摘要(原文)
Referring-based Video Object Segmentation is a multimodal problem that requires producing fine-grained segmentation results guided by external cues. Traditional approaches to this task typically involve training specialized models, which come with high computational complexity and manual annotation effort. Recent advances in vision-language foundation models open a promising direction toward training-free approaches. Several studies have explored leveraging these general-purpose models for fine-grained segmentation, achieving performance comparable to that of fully supervised, task-specific models. However, existing methods rely on fixed pipelines that lack the flexibility needed to adapt to the dynamic nature of the task. To address this limitation, we propose Multi-Modal Agent, a novel agentic system designed to solve this task in a more flexible and adaptive manner. Specifically, our method leverages the reasoning capabilities of large language models (LLMs) to generate dynamic workflows tailored to each input. This adaptive procedure iteratively interacts with a set of specialized tools designed for low-level tasks across different modalities to identify the target object described by the multimodal cues. Our agentic approach demonstrates clear improvements over prior methods on two multimodal-conditioned VOS tasks: RVOS and Ref-AVS.