EgoMusic-driven Human Dance Motion Estimation with Skeleton Mamba
作者: Quang Nguyen, Nhat Le, Baoru Huang, Minh Nhat Vu, Chengcheng Tang, Van Nguyen, Ngan Le, Thieu Vo, Anh Nguyen
分类: cs.CV
发布日期: 2025-08-14
备注: Accepted at The 2025 IEEE/CVF International Conference on Computer Vision (ICCV 2025)
💡 一句话要点
提出基于Skeleton Mamba的EgoMusic运动网络,用于从第一视角视频和音乐驱动的人体舞蹈动作估计。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体动作估计 舞蹈动作生成 第一视角视频 音乐驱动 Mamba 骨骼建模 多模态融合
📋 核心要点
- 现有方法在利用第一视角视频和音乐联合估计人体舞蹈动作方面存在不足,面临遮挡和多模态对齐的挑战。
- 提出EgoMusic运动网络,核心为Skeleton Mamba,显式建模人体骨骼结构,实现视觉和音乐驱动的舞蹈动作生成。
- 构建大规模数据集EgoAIST++,实验结果表明该方法优于现有技术,并具有良好的真实数据泛化能力。
📝 摘要(中文)
本文旨在开发一种新方法,利用第一视角视频和音乐共同预测人体舞蹈动作。第一视角视频通常会遮挡身体的大部分,使得准确的全身姿态估计具有挑战性。此外,融合音乐需要生成的头部和身体运动与视觉和音乐输入良好对齐。为此,我们首先引入了一个新的大规模数据集EgoAIST++,它结合了第一视角视频和音乐,包含超过36小时的舞蹈动作。借鉴扩散模型和Mamba在序列建模方面的成功,我们开发了一个EgoMusic运动网络,其核心是Skeleton Mamba,它显式地捕捉了人体的骨骼结构。理论分析和大量实验表明,我们的方法明显优于最先进的方法,并且能够有效地泛化到真实世界的数据。
🔬 方法详解
问题定义:论文旨在解决从第一视角视频和音乐中估计人体舞蹈动作的问题。现有方法要么只使用第一视角视频或音乐作为输入,要么在处理两者结合时,难以克服第一视角视频的遮挡问题,以及保证生成动作与视觉和音乐输入的同步性和一致性。
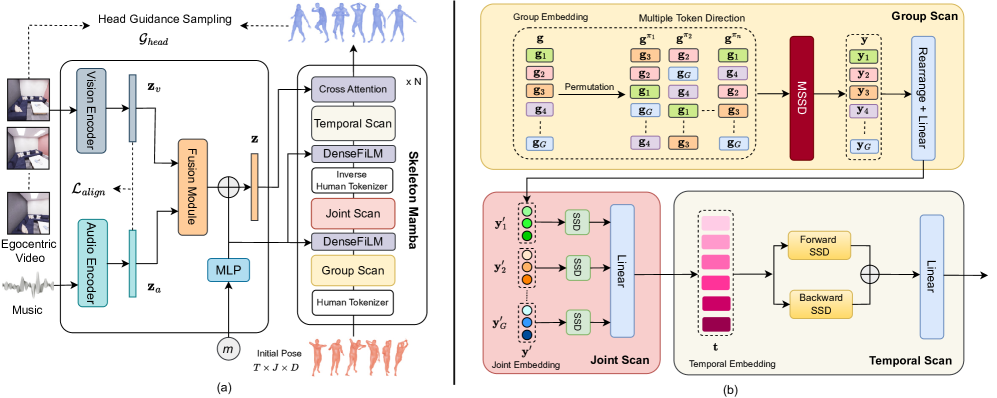
核心思路:论文的核心思路是利用Mamba架构强大的序列建模能力,并结合人体骨骼结构的先验知识,设计一个能够同时处理视觉和听觉信息的网络。通过显式地建模骨骼结构,可以更好地约束生成的人体动作,提高动作的自然性和准确性。
技术框架:整体框架包含数据输入模块、特征提取模块和运动生成模块。数据输入模块负责处理第一视角视频和音乐数据,提取相应的视觉和听觉特征。特征提取模块使用预训练模型(具体模型未知)提取高层语义特征。运动生成模块是核心,由Skeleton Mamba组成,负责根据提取的特征生成人体骨骼运动序列。
关键创新:关键创新在于Skeleton Mamba的设计,它将Mamba架构与人体骨骼结构相结合。传统的Mamba主要处理一维序列数据,而人体骨骼具有天然的图结构。Skeleton Mamba通过某种方式(具体实现未知)将骨骼的连接关系融入到Mamba的计算过程中,从而更好地建模人体运动的依赖关系。
关键设计:论文的关键设计包括:1) EgoAIST++数据集的构建,为模型训练提供了充足的数据;2) Skeleton Mamba的具体实现方式,如何将骨骼结构融入到Mamba中(具体细节未知);3) 损失函数的设计,可能包括运动学约束、音乐同步性约束等(具体细节未知)。
🖼️ 关键图片

📊 实验亮点
论文提出的EgoMusic运动网络在人体舞蹈动作估计任务上取得了显著的性能提升。通过与现有最先进的方法进行对比,该方法在多个指标上均取得了更好的结果,并且在真实世界的数据集上表现出良好的泛化能力。具体的性能数据和提升幅度在论文中进行了详细的展示(具体数值未知)。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏、动画制作等领域。例如,可以根据用户的视角和音乐,生成个性化的舞蹈动作,增强用户的沉浸式体验。此外,该技术还可以用于舞蹈教学,帮助学习者更好地理解和掌握舞蹈动作。未来,该技术有望应用于康复训练,通过音乐和视觉刺激,辅助患者进行运动功能恢复。
📄 摘要(原文)
Estimating human dance motion is a challenging task with various industrial applications. Recently, many efforts have focused on predicting human dance motion using either egocentric video or music as input. However, the task of jointly estimating human motion from both egocentric video and music remains largely unexplored. In this paper, we aim to develop a new method that predicts human dance motion from both egocentric video and music. In practice, the egocentric view often obscures much of the body, making accurate full-pose estimation challenging. Additionally, incorporating music requires the generated head and body movements to align well with both visual and musical inputs. We first introduce EgoAIST++, a new large-scale dataset that combines both egocentric views and music with more than 36 hours of dancing motion. Drawing on the success of diffusion models and Mamba on modeling sequences, we develop an EgoMusic Motion Network with a core Skeleton Mamba that explicitly captures the skeleton structure of the human body. We illustrate that our approach is theoretically supportive. Intensive experiments show that our method clearly outperforms state-of-the-art approaches and generalizes effectively to real-world data.