Trajectory-aware Shifted State Space Models for Online Video Super-Resolution
作者: Qiang Zhu, Xiandong Meng, Yuxian Jiang, Fan Zhang, David Bull, Shuyuan Zhu, Bing Zeng
分类: cs.CV
发布日期: 2025-08-14
💡 一句话要点
提出基于轨迹感知的移位状态空间模型的在线视频超分辨率方法,提升时空信息聚合效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频超分辨率 在线VSR 状态空间模型 Mamba 轨迹建模 时空信息聚合 深度学习
📋 核心要点
- 现有在线VSR方法主要依赖单帧进行时间对齐,限制了视频长时序建模能力。
- TS-Mamba通过轨迹建模选择相似tokens,并利用移位SSM块进行高效时空信息聚合。
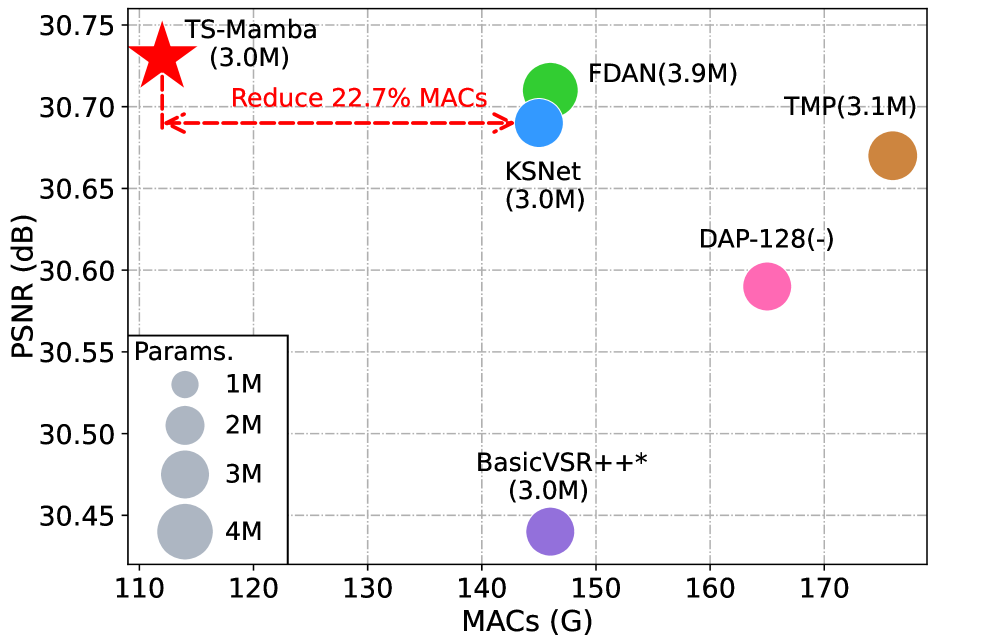
- 实验结果表明,TS-Mamba在性能上优于现有方法,且计算复杂度显著降低。
📝 摘要(中文)
本文提出了一种新颖的基于轨迹感知的移位状态空间模型(TS-Mamba)的在线视频超分辨率(VSR)方法。该方法利用长时轨迹建模和低复杂度的Mamba结构,实现高效的时空信息聚合。TS-Mamba首先在视频中构建轨迹,从先前帧中选择最相似的tokens。然后,采用轨迹感知的移位Mamba聚合(TSMA)模块,该模块由移位SSM块组成,用于聚合所选tokens。移位SSM块基于Hilbert扫描和相应的移位操作设计,以补偿扫描损失并加强Mamba的空间连续性。此外,还提出了一种轨迹感知的损失函数来监督轨迹生成,确保模型训练时token选择的准确性。在三个广泛使用的VSR测试数据集上的大量实验表明,与六个在线VSR基准模型相比,TS-Mamba在大多数情况下实现了最先进的性能,并且计算复杂度降低了超过22.7%(以MACs衡量)。TS-Mamba的源代码将在https://github.com上提供。
🔬 方法详解
问题定义:在线视频超分辨率旨在利用先前帧恢复当前高分辨率视频帧。现有方法主要依赖单帧进行时间对齐,无法有效利用长时序信息,限制了性能提升。此外,计算复杂度也是在线VSR的一个重要挑战。
核心思路:本文的核心思路是利用视频中的轨迹信息,选择与当前帧最相关的历史帧tokens,并使用改进的状态空间模型(SSM)进行高效的时空信息聚合。通过轨迹建模,可以有效利用长时序信息,提升超分辨率效果。同时,优化的SSM结构能够在保证性能的同时降低计算复杂度。
技术框架:TS-Mamba的整体框架包含以下几个主要步骤:1) 轨迹构建:在视频中构建轨迹,用于选择相似的tokens。2) Token选择:基于轨迹信息,从先前帧中选择与当前帧最相似的tokens。3) 轨迹感知的移位Mamba聚合(TSMA):使用TSMA模块聚合所选tokens,该模块由移位SSM块组成。4) 超分辨率重建:利用聚合后的特征重建高分辨率视频帧。
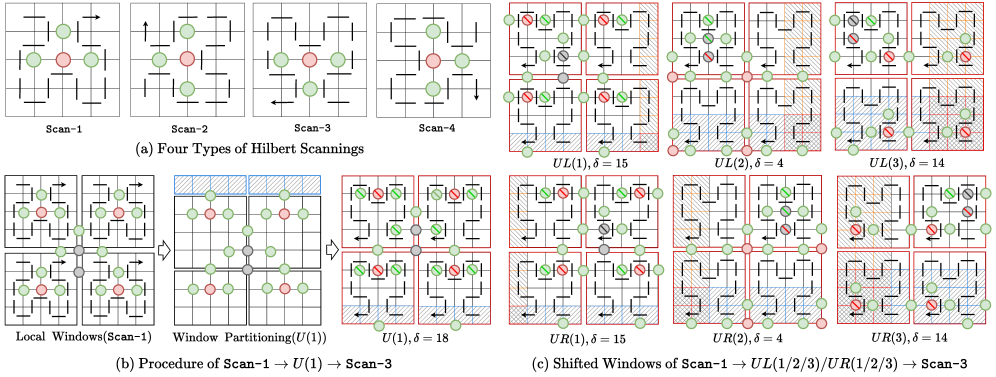
关键创新:本文的关键创新在于:1) 提出了轨迹感知的移位Mamba聚合(TSMA)模块,该模块能够有效聚合长时序信息,提升超分辨率性能。2) 设计了移位SSM块,通过Hilbert扫描和移位操作,补偿扫描损失,加强Mamba的空间连续性。3) 提出了轨迹感知的损失函数,用于监督轨迹生成,确保token选择的准确性。
关键设计:移位SSM块基于Hilbert扫描设计,通过移位操作补偿扫描损失,保证空间连续性。轨迹感知损失函数用于监督轨迹生成,确保token选择的准确性。具体的网络结构和参数设置在论文中有详细描述,包括Mamba块的配置和损失函数的权重等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TS-Mamba在三个广泛使用的VSR测试数据集上取得了state-of-the-art的性能。与六个在线VSR基准模型相比,TS-Mamba在大多数情况下都优于现有方法,并且计算复杂度降低了超过22.7%(以MACs衡量)。这表明TS-Mamba在性能和效率上都具有显著优势。
🎯 应用场景
该研究成果可应用于各种视频处理场景,如视频监控、视频会议、在线视频增强等。通过提升视频分辨率,可以改善用户观看体验,提高视频分析的准确性。该方法在计算效率上的优势,使其更适用于资源受限的设备或实时应用。
📄 摘要(原文)
Online video super-resolution (VSR) is an important technique for many real-world video processing applications, which aims to restore the current high-resolution video frame based on temporally previous frames. Most of the existing online VSR methods solely employ one neighboring previous frame to achieve temporal alignment, which limits long-range temporal modeling of videos. Recently, state space models (SSMs) have been proposed with linear computational complexity and a global receptive field, which significantly improve computational efficiency and performance. In this context, this paper presents a novel online VSR method based on Trajectory-aware Shifted SSMs (TS-Mamba), leveraging both long-term trajectory modeling and low-complexity Mamba to achieve efficient spatio-temporal information aggregation. Specifically, TS-Mamba first constructs the trajectories within a video to select the most similar tokens from the previous frames. Then, a Trajectory-aware Shifted Mamba Aggregation (TSMA) module consisting of proposed shifted SSMs blocks is employed to aggregate the selected tokens. The shifted SSMs blocks are designed based on Hilbert scannings and corresponding shift operations to compensate for scanning losses and strengthen the spatial continuity of Mamba. Additionally, we propose a trajectory-aware loss function to supervise the trajectory generation, ensuring the accuracy of token selection when training our model. Extensive experiments on three widely used VSR test datasets demonstrate that compared with six online VSR benchmark models, our TS-Mamba achieves state-of-the-art performance in most cases and over 22.7\% complexity reduction (in MACs). The source code for TS-Mamba will be available at https://github.com.