STRIDE-QA: Visual Question Answering Dataset for Spatiotemporal Reasoning in Urban Driving Scenes
作者: Keishi Ishihara, Kento Sasaki, Tsubasa Takahashi, Daiki Shiono, Yu Yamaguchi
分类: cs.CV
发布日期: 2025-08-14 (更新: 2026-01-19)
备注: Accepted to AAAI 2026 (Oral). project page: https://turingmotors.github.io/stride-qa/
💡 一句话要点
提出STRIDE-QA以解决城市驾驶场景中的时空推理问题
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉问答 时空推理 自动驾驶 多传感器数据 模型微调 动态场景理解 数据集构建
📋 核心要点
- 现有的视觉语言模型在动态交通场景中的时空推理能力不足,主要依赖静态图像-文本对进行训练,导致推理精度低。
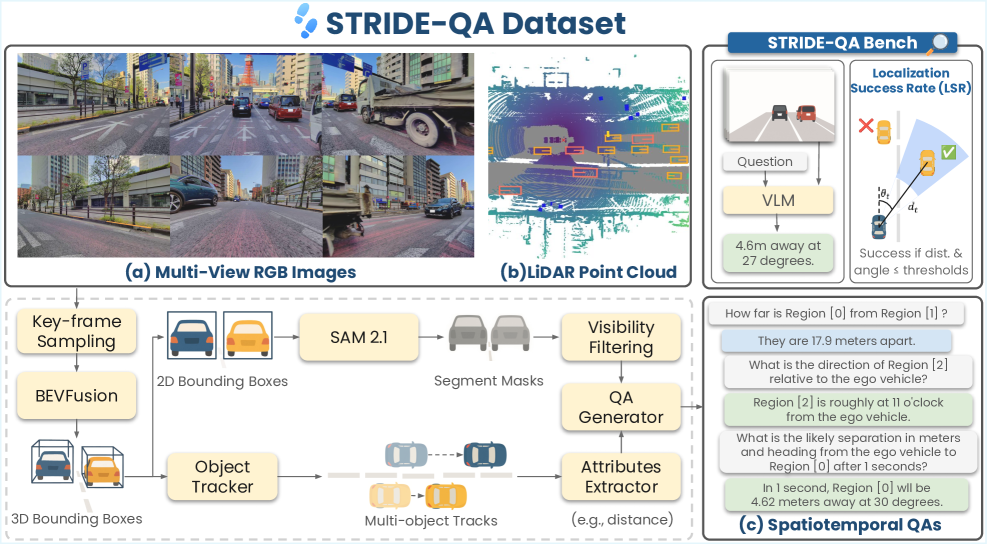
- 本文提出STRIDE-QA数据集,基于多传感器驾驶数据,支持从自我中心视角进行物理基础推理,包含丰富的时空信息。
- 实验结果表明,微调后的VLMs在STRIDE-QA上表现显著提升,空间定位成功率达到55%,未来运动预测一致性为28%。
📝 摘要(中文)
视觉语言模型(VLMs)已被应用于自动驾驶,以支持复杂现实场景中的决策。然而,它们在静态网络图像-文本对上的训练限制了对动态交通场景的精确时空推理。为此,本文提出了STRIDE-QA,这是一个大型视觉问答(VQA)数据集,旨在从自我中心的视角进行物理基础推理。该数据集基于100小时的多传感器驾驶数据构建,涵盖了多样且具有挑战性的条件,提供了270K帧的1600万QA对。通过密集的自动生成注释(包括3D边界框、分割掩码和多目标轨迹)进行基础支撑,STRIDE-QA支持对象中心和自我中心的推理,包含三种新颖的QA任务,要求空间定位和时间预测。基准测试显示,现有VLMs在预测一致性上表现不佳,而在STRIDE-QA上微调的VLMs则显著提升,空间定位成功率达到55%,未来运动预测一致性为28%。
🔬 方法详解
问题定义:本文旨在解决现有视觉语言模型在动态交通场景中时空推理能力不足的问题。现有方法主要依赖静态图像-文本对进行训练,无法有效处理复杂的实时驾驶场景。
核心思路:通过构建STRIDE-QA数据集,提供丰富的时空信息和多样化的问答任务,支持自我中心和对象中心的推理,从而提升模型在动态场景中的推理能力。
技术框架:整体架构包括数据采集、注释生成、问答任务设计和模型训练四个主要模块。数据采集基于100小时的多传感器驾驶数据,注释生成则使用自动化工具生成3D边界框和分割掩码。
关键创新:STRIDE-QA是首个针对城市驾驶场景的时空推理VQA数据集,包含丰富的动态信息和多样的问答任务,显著提升了模型的推理能力。
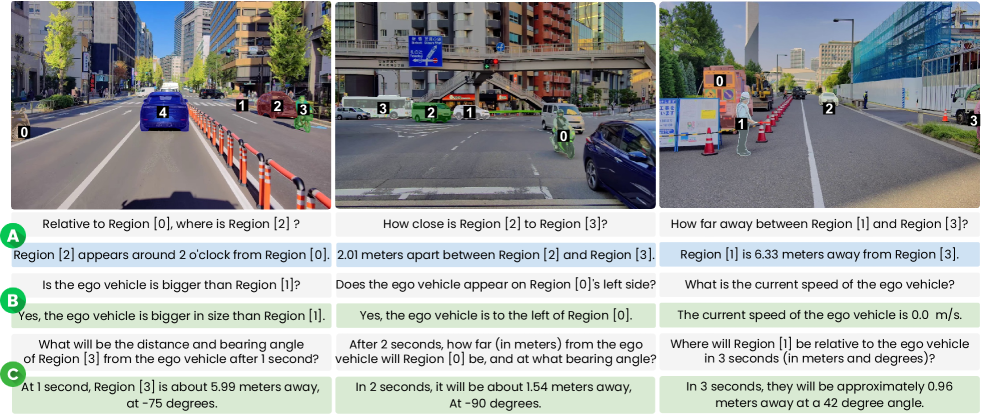
关键设计:数据集中包含1600万QA对,采用密集注释方式,设计了三种新颖的问答任务,要求模型进行空间定位和时间预测。
🖼️ 关键图片

📊 实验亮点
实验结果显示,现有的视觉语言模型在STRIDE-QA数据集上的表现显著低于微调后的模型,后者在空间定位任务上成功率达到55%,而在未来运动预测一致性上则达到28%。这一提升表明STRIDE-QA在推动时空推理能力方面的重要性。
🎯 应用场景
STRIDE-QA数据集的构建为自动驾驶系统提供了重要的基础,能够支持更可靠的视觉语言模型开发,提升自动驾驶的安全性和决策能力。未来,该数据集可广泛应用于智能交通、无人驾驶汽车和机器人导航等领域,推动相关技术的进步。
📄 摘要(原文)
Vision-Language Models (VLMs) have been applied to autonomous driving to support decision-making in complex real-world scenarios. However, their training on static, web-sourced image-text pairs fundamentally limits the precise spatiotemporal reasoning required to understand and predict dynamic traffic scenes. We address this critical gap with STRIDE-QA, a large-scale visual question answering (VQA) dataset for physically grounded reasoning from an ego-centric perspective. Constructed from 100 hours of multi-sensor driving data in Tokyo, capturing diverse and challenging conditions, STRIDE-QA is the largest VQA dataset for spatiotemporal reasoning in urban driving, offering 16M QA pairs over 270K frames. Grounded by dense, automatically generated annotations including 3D bounding boxes, segmentation masks, and multi-object tracks, the dataset uniquely supports both object-centric and ego-centric reasoning through three novel QA tasks that require spatial localization and temporal prediction. Our benchmarks demonstrate that existing VLMs struggle significantly, with near-zero scores on prediction consistency. In contrast, VLMs fine-tuned on STRIDE-QA exhibit dramatic performance gains, achieving 55% success in spatial localization and 28% consistency in future motion prediction, compared to near-zero scores from general-purpose VLMs. Therefore, STRIDE-QA establishes a comprehensive foundation for developing more reliable VLMs for safety-critical autonomous systems.