Integrating Reinforcement Learning with Visual Generative Models: Foundations and Advances
作者: Yuanzhi Liang, Yijie Fang, Ke Hao, Rui Li, Ziqi Ni, Ruijie Su, Chi Zhang
分类: cs.CV
发布日期: 2025-08-14 (更新: 2026-01-19)
备注: Ongoing work. We maintain a companion website with an up-to-date version of this survey at: https://visgenrlsurvey.liangyzh18.workers.dev/
💡 一句话要点
综述:强化学习赋能视觉生成模型,提升可控性与真实感
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 生成模型 视觉内容生成 图像生成 视频生成 3D/4D生成 奖励函数 策略优化
📋 核心要点
- 现有生成模型依赖替代损失函数,难以保证生成内容在感知质量、语义准确性和物理真实感上与人类期望对齐。
- 论文核心思想是利用强化学习框架,直接优化不可微、偏好驱动和具有时间结构的生成目标,从而提升生成内容质量。
- 综述回顾了强化学习在图像、视频和3D/4D内容生成中的应用,并探讨了其作为微调机制和结构组件的作用。
📝 摘要(中文)
生成模型在合成视觉内容(包括图像、视频和3D/4D结构)方面取得了显著进展。然而,它们通常使用诸如似然或重构损失等替代目标进行训练,这些目标常常与感知质量、语义准确性或物理真实感不一致。强化学习(RL)提供了一个优化不可微、偏好驱动和时间结构化目标的原则性框架。最近的进展表明,RL在增强生成任务的可控性、一致性和人类对齐方面非常有效。本综述系统地概述了基于RL的视觉内容生成方法。我们回顾了RL从经典控制到其作为通用优化工具的演变,并考察了其在图像、视频和3D/4D生成中的集成。在这些领域中,RL不仅作为一种微调机制,而且作为一种结构组件,用于使生成与复杂的高级目标对齐。最后,我们总结了RL与生成建模交叉领域的开放挑战和未来研究方向。
🔬 方法详解
问题定义:现有视觉生成模型通常使用似然或重构损失等替代目标进行训练,这些目标与人类感知的真实性、语义准确性以及物理合理性存在偏差。因此,如何训练出能够生成高质量、符合人类期望的视觉内容是一个关键问题。现有方法难以直接优化这些复杂的、不可微的目标。
核心思路:论文的核心思路是将视觉生成过程视为一个强化学习任务,通过定义合适的奖励函数来引导生成模型朝着期望的目标优化。强化学习能够处理不可微的奖励信号,并能够优化具有时间依赖性的生成过程,从而更好地控制生成结果。
技术框架:该综述涵盖了强化学习在图像生成、视频生成和3D/4D结构生成中的应用。在图像生成中,RL可以用于优化GAN的判别器,或者直接作为生成器的训练目标。在视频生成中,RL可以用于保证视频帧之间的一致性。在3D/4D生成中,RL可以用于优化物理模拟的真实性。整体框架通常包括一个生成模型(作为RL中的策略网络)和一个奖励函数(可以是人工设计的,也可以是学习得到的)。
关键创新:该综述的关键创新在于系统性地总结了强化学习在视觉生成领域的应用,并指出了RL在解决传统生成模型难以优化的问题上的优势。它强调了RL不仅可以作为一种微调机制,还可以作为一种结构组件,用于将生成过程与复杂的高级目标对齐。
关键设计:关键设计包括奖励函数的选择,例如使用GAN的判别器输出作为奖励,或者使用预训练的视觉模型提取特征并计算相似度作为奖励。此外,策略网络的结构设计也很重要,需要根据具体的生成任务进行调整。对于时间序列生成任务,可以使用循环神经网络(RNN)或Transformer等模型来建模时间依赖性。
🖼️ 关键图片
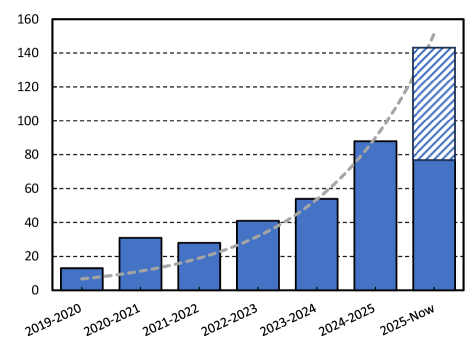
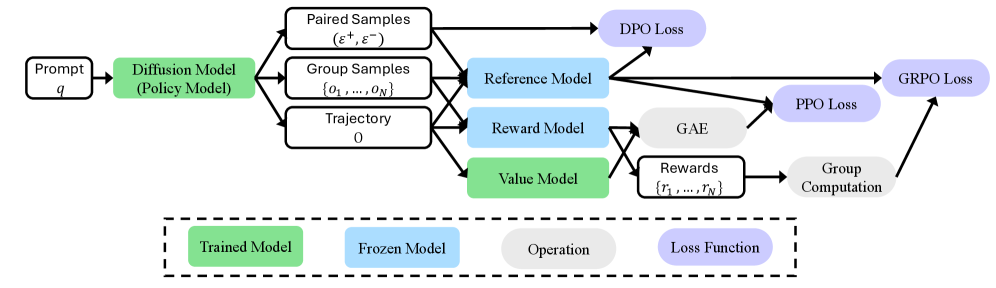
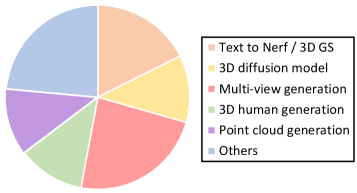
📊 实验亮点
该综述总结了近年来强化学习在视觉生成领域的最新进展,涵盖了图像、视频和3D/4D结构生成等多个方面。它强调了强化学习在提升生成内容的可控性、一致性和人类对齐方面的有效性,并指出了未来研究方向,例如探索更有效的奖励函数设计。
🎯 应用场景
该研究具有广泛的应用前景,包括图像编辑、视频游戏开发、虚拟现实、机器人仿真等领域。通过强化学习优化生成模型,可以生成更逼真、更可控的视觉内容,从而提升用户体验和创造力。未来的发展方向包括探索更有效的奖励函数设计、结合人类反馈进行训练以及将强化学习与其他生成模型相结合。
📄 摘要(原文)
Generative models have made significant progress in synthesizing visual content, including images, videos, and 3D/4D structures. However, they are typically trained with surrogate objectives such as likelihood or reconstruction loss, which often misalign with perceptual quality, semantic accuracy, or physical realism. Reinforcement learning (RL) offers a principled framework for optimizing non-differentiable, preference-driven, and temporally structured objectives. Recent advances demonstrate its effectiveness in enhancing controllability, consistency, and human alignment across generative tasks. This survey provides a systematic overview of RL-based methods for visual content generation. We review the evolution of RL from classical control to its role as a general-purpose optimization tool, and examine its integration into image, video, and 3D/4D generation. Across these domains, RL serves not only as a fine-tuning mechanism but also as a structural component for aligning generation with complex, high-level goals. We conclude with open challenges and future research directions at the intersection of RL and generative modeling.