Test-Time Reinforcement Learning for GUI Grounding via Region Consistency
作者: Yong Du, Yuchen Yan, Fei Tang, Zhengxi Lu, Chang Zong, Weiming Lu, Shengpei Jiang, Yongliang Shen
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-08-07 (更新: 2025-11-13)
备注: [Accepted by AAAI2026] Project Page: https://zju-real.github.io/gui-rcpo Code: https://github.com/zju-real/gui-rcpo
💡 一句话要点
提出基于区域一致性的测试时强化学习方法,用于提升GUI元素定位精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: GUI定位 区域一致性 测试时强化学习 无监督学习 策略优化
📋 核心要点
- 现有GUI定位方法依赖大量标注数据,成本高昂,限制了模型泛化能力。
- 论文提出基于区域一致性的方法,利用模型多次预测的空间重叠模式作为置信度信号。
- 实验表明,该方法在ScreenSpot基准测试中显著提升了GUI定位的准确率,且数据效率高。
📝 摘要(中文)
图形用户界面(GUI)定位是自主GUI代理的基础任务,旨在将自然语言指令映射到精确的屏幕坐标。现有方法虽然通过大量的监督训练或带标签奖励的强化学习取得了显著的性能,但仍受限于像素级标注的成本和可用性。我们观察到,当模型为同一GUI元素生成多个预测时,空间重叠模式揭示了隐式的置信度信号,可以指导更准确的定位。基于此,我们提出GUI-RC(区域一致性),一种测试时缩放方法,它从多个采样的预测构建空间投票网格,以识别模型显示最高一致性的共识区域。在没有任何训练的情况下,GUI-RC在ScreenSpot基准测试中将准确率提高了2-3%。我们进一步引入GUI-RCPO(区域一致性策略优化),将这些一致性模式转化为测试时强化学习的奖励。通过计算每个预测与集体共识的对齐程度,GUI-RCPO使模型能够在推理期间迭代地细化其在未标记数据上的输出。大量的实验证明了我们方法的通用性:仅使用1,272个未标记数据,GUI-RCPO在ScreenSpot基准测试中将各种架构的准确率提高了3-6%。我们的方法揭示了测试时缩放和测试时强化学习在GUI定位中未开发的潜力,为更具数据效率的GUI代理提供了一条有希望的途径。
🔬 方法详解
问题定义:GUI定位旨在将自然语言指令映射到屏幕上的特定坐标。现有方法依赖于大量的像素级标注数据进行监督学习或强化学习,但获取这些标注数据成本高昂,限制了模型的泛化能力和实际应用。
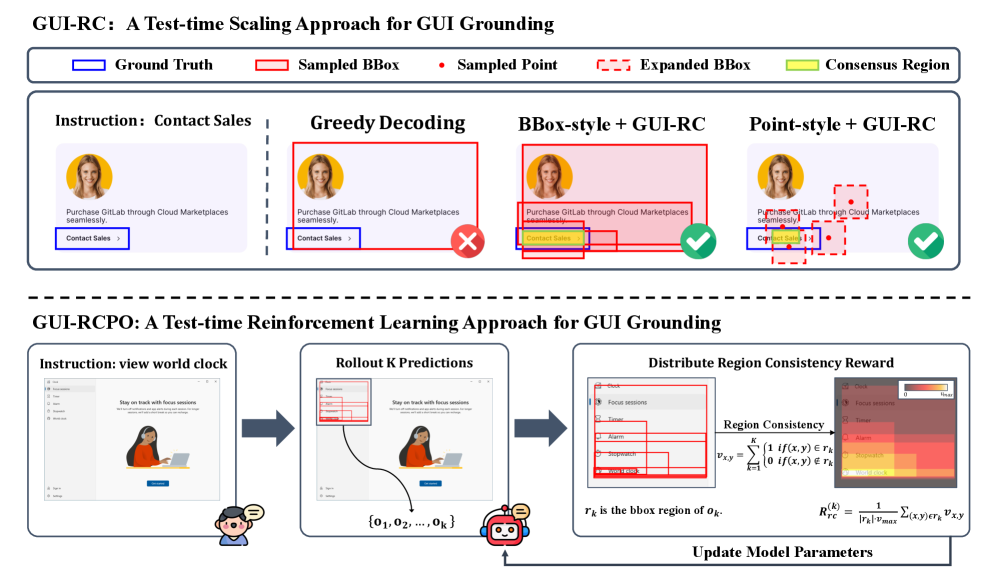
核心思路:论文的核心思路是利用模型在测试时对同一GUI元素进行多次预测所产生的空间重叠模式。这些重叠区域代表了模型预测的共识,可以作为一种隐式的置信度信号,指导模型更准确地定位目标元素。通过最大化预测结果的区域一致性,可以提升定位精度。
技术框架:论文提出了两种方法:GUI-RC和GUI-RCPO。GUI-RC是一种测试时缩放方法,它首先对每个输入生成多个预测,然后构建空间投票网格,统计每个位置的预测数量,从而识别出共识区域。GUI-RCPO则将区域一致性转化为强化学习的奖励信号,通过策略优化,使模型能够迭代地改进其预测结果。整体流程包括:1) 多次采样预测;2) 构建空间投票网格;3) 基于网格计算一致性得分;4) (GUI-RCPO) 使用一致性得分作为奖励进行策略优化。
关键创新:该论文的关键创新在于利用测试时模型预测的内在一致性来提升定位精度,而无需额外的标注数据。与传统的监督学习或强化学习方法不同,该方法充分挖掘了模型自身的信息,实现了数据高效的GUI定位。GUI-RCPO进一步将这种一致性信息融入到强化学习框架中,实现了迭代式的优化。
关键设计:GUI-RC的关键设计在于空间投票网格的构建和共识区域的识别。GUI-RCPO的关键设计在于如何将区域一致性转化为有效的奖励信号,并设计合适的策略优化算法。具体而言,奖励函数的设计需要能够反映预测结果与共识区域的对齐程度。策略优化算法可以选择常见的策略梯度方法,如REINFORCE或Actor-Critic。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GUI-RC在ScreenSpot基准测试中无需任何训练即可将准确率提高2-3%。更重要的是,GUI-RCPO仅使用1,272个未标记数据,就能在ScreenSpot基准测试中将各种架构的准确率提高3-6%。这些结果突显了该方法在数据效率方面的优势,并证明了测试时缩放和测试时强化学习在GUI定位中的巨大潜力。
🎯 应用场景
该研究成果可应用于开发更智能、更高效的自动化GUI代理,例如自动化测试工具、辅助技术和机器人流程自动化(RPA)系统。通过减少对标注数据的依赖,该方法可以降低开发成本,并提高GUI代理在不同应用场景下的适应性。未来,该技术有望推动人机交互的进一步发展。
📄 摘要(原文)
Graphical User Interface (GUI) grounding, the task of mapping natural language instructions to precise screen coordinates, is fundamental to autonomous GUI agents. While existing methods achieve strong performance through extensive supervised training or reinforcement learning with labeled rewards, they remain constrained by the cost and availability of pixel-level annotations. We observe that when models generate multiple predictions for the same GUI element, the spatial overlap patterns reveal implicit confidence signals that can guide more accurate localization. Leveraging this insight, we propose GUI-RC (Region Consistency), a test-time scaling method that constructs spatial voting grids from multiple sampled predictions to identify consensus regions where models show highest agreement. Without any training, GUI-RC improves accuracy by 2-3% across various architectures on ScreenSpot benchmarks. We further introduce GUI-RCPO (Region Consistency Policy Optimization), transforming these consistency patterns into rewards for test-time reinforcement learning. By computing how well each prediction aligns with the collective consensus, GUI-RCPO enables models to iteratively refine their outputs on unlabeled data during inference. Extensive experiments demonstrate the generality of our approach: using only 1,272 unlabeled data, GUI-RCPO achieves 3-6% accuracy improvements across various architectures on ScreenSpot benchmarks. Our approach reveals the untapped potential of test-time scaling and test-time reinforcement learning for GUI grounding, offering a promising path toward more data-efficient GUI agents.