Uni-cot: Towards Unified Chain-of-Thought Reasoning Across Text and Vision
作者: Luozheng Qin, Jia Gong, Yuqing Sun, Tianjiao Li, Mengping Yang, Xiaomeng Yang, Chao Qu, Zhiyu Tan, Hao Li
分类: cs.CV, cs.CL
发布日期: 2025-08-07 (更新: 2025-09-17)
备注: Project Page: https://sais-fuxi.github.io/projects/uni-cot/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Uni-CoT,用于统一文本和视觉的链式思考推理,实现多模态任务的SOTA性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 链式思考 多模态推理 视觉语言 图像生成 图像编辑
📋 核心要点
- 现有视觉-语言推理方法难以有效建模视觉状态转换,导致推理过程中的视觉轨迹不连贯,影响最终结果。
- Uni-CoT利用统一模型进行图像理解和生成,通过宏观CoT进行任务规划,微观CoT执行子任务,实现连贯的多模态推理。
- 实验表明,Uni-CoT在图像生成和编辑任务上取得了SOTA性能,并且具有良好的泛化能力,仅需少量GPU资源即可完成训练。
📝 摘要(中文)
链式思考(CoT)推理已被广泛应用于增强大型语言模型(LLMs),通过将复杂任务分解为更简单、顺序的子任务。然而,将CoT扩展到视觉-语言推理任务仍然具有挑战性,因为它通常需要解释视觉状态的转换以支持推理。现有的方法通常难以应对这一挑战,因为它们在建模视觉状态转换的能力有限,或者由于碎片化的架构导致视觉轨迹不连贯。为了克服这些限制,我们提出了Uni-CoT,一个统一的链式思考框架,它可以在单个统一模型中实现连贯且有根据的多模态推理。关键思想是利用一个既能理解图像又能生成图像的模型来推理视觉内容并建模不断演变的视觉状态。然而,鉴于高昂的计算成本和训练负担,使统一模型能够实现这一点并非易事。为了解决这个问题,Uni-CoT引入了一种新颖的两级推理范式:用于高级任务规划的宏观CoT和用于子任务执行的微观CoT。这种设计显著降低了计算开销。此外,我们引入了一种结构化的训练范式,将宏观CoT的交错图像-文本监督与微观CoT的多任务目标相结合。总之,这些创新使Uni-CoT能够执行可扩展且连贯的多模态推理。此外,由于我们的设计,所有实验都可以仅使用8个A100 GPU(每个GPU具有80GB VRAM)高效完成。在推理驱动的图像生成基准(WISE)和编辑基准(RISE和KRIS)上的实验结果表明,Uni-CoT表现出SOTA性能和强大的泛化能力,将Uni-CoT确立为多模态推理的有希望的解决方案。
🔬 方法详解
问题定义:现有视觉-语言推理方法在处理需要理解和推理视觉状态变化的任务时表现不佳。这些方法通常采用分离的架构,导致视觉信息处理的碎片化,难以捕捉到连贯的视觉轨迹。此外,建模视觉状态转换的能力有限,使得模型难以进行有效的推理。现有方法的痛点在于无法在统一的框架下进行连贯且有根据的多模态推理。
核心思路:Uni-CoT的核心思路是利用一个统一的模型,该模型既能理解图像,又能生成图像,从而实现对视觉内容的推理和对不断演变的视觉状态的建模。通过将图像理解和生成能力集成到同一个模型中,Uni-CoT能够更好地捕捉视觉状态之间的依赖关系,并生成连贯的视觉轨迹。此外,Uni-CoT引入了一种两级推理范式,将复杂的推理任务分解为高级任务规划和子任务执行两个阶段,从而降低了计算开销。
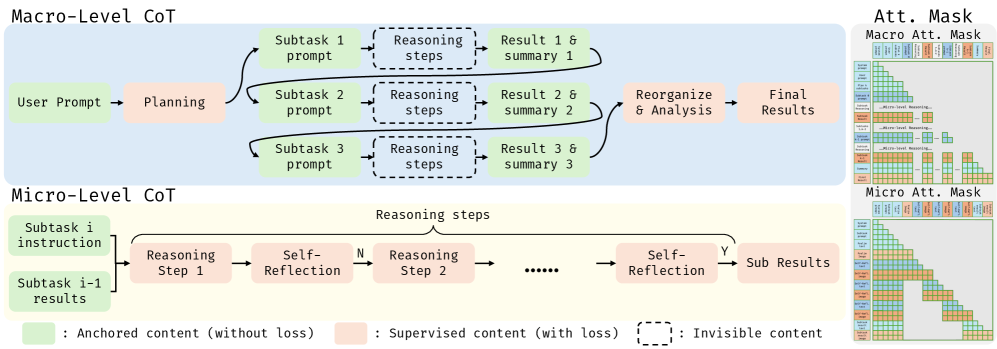
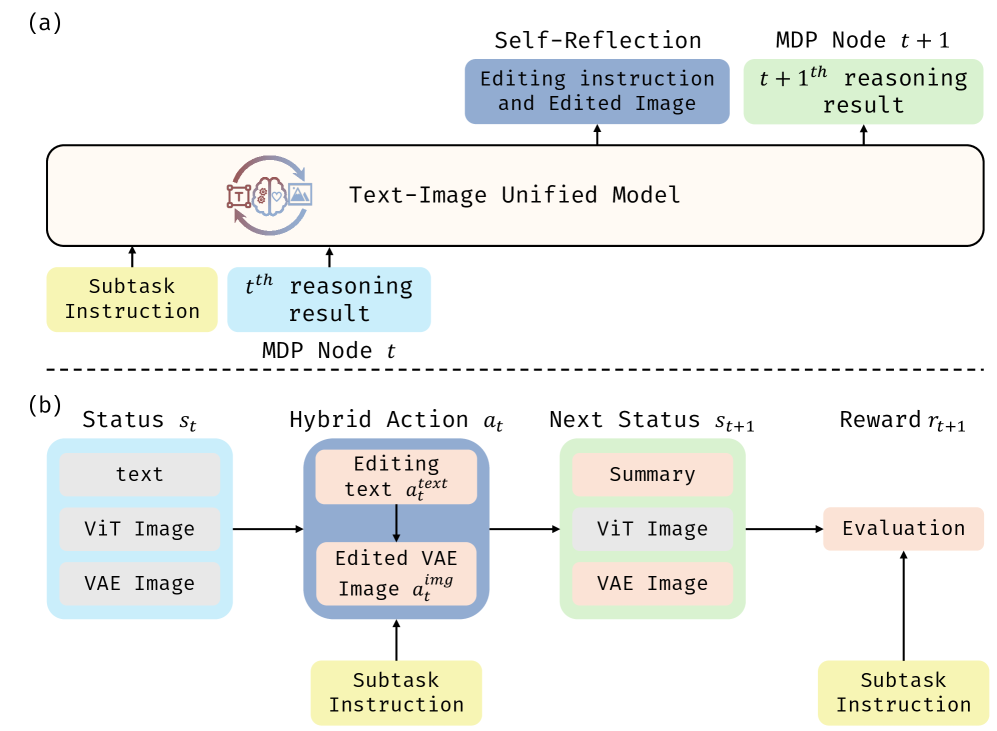
技术框架:Uni-CoT的整体架构包含两个主要模块:宏观CoT和微观CoT。宏观CoT负责高级任务规划,将复杂任务分解为一系列子任务。微观CoT负责子任务的执行,利用统一模型进行图像理解和生成,从而实现对视觉内容的推理和对视觉状态的建模。这两个模块协同工作,共同完成多模态推理任务。训练过程采用了一种结构化的训练范式,将宏观CoT的交错图像-文本监督与微观CoT的多任务目标相结合。
关键创新:Uni-CoT最重要的技术创新点在于其统一的链式思考框架,该框架能够在单个模型中实现连贯且有根据的多模态推理。与现有方法相比,Uni-CoT能够更好地捕捉视觉状态之间的依赖关系,并生成连贯的视觉轨迹。此外,Uni-CoT的两级推理范式能够有效降低计算开销,使其能够处理更复杂的推理任务。
关键设计:Uni-CoT的关键设计包括:1) 统一的图像理解和生成模型,该模型能够同时处理图像和文本信息;2) 两级推理范式,将复杂任务分解为高级任务规划和子任务执行两个阶段;3) 结构化的训练范式,将宏观CoT的交错图像-文本监督与微观CoT的多任务目标相结合。具体的损失函数和网络结构等技术细节在论文中有详细描述,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
Uni-CoT在推理驱动的图像生成基准(WISE)和编辑基准(RISE和KRIS)上取得了SOTA性能,证明了其强大的多模态推理能力和泛化能力。值得注意的是,所有实验仅使用8个A100 GPU(每个GPU具有80GB VRAM)高效完成,表明Uni-CoT具有良好的可扩展性。
🎯 应用场景
Uni-CoT在视觉-语言推理领域具有广泛的应用前景,例如智能图像编辑、视觉故事生成、机器人导航等。该研究的实际价值在于提升了多模态推理的性能和效率,为开发更智能的视觉-语言系统奠定了基础。未来,Uni-CoT有望应用于更复杂的场景,例如自动驾驶、医疗诊断等。
📄 摘要(原文)
Chain-of-Thought (CoT) reasoning has been widely adopted to enhance Large Language Models (LLMs) by decomposing complex tasks into simpler, sequential subtasks. However, extending CoT to vision-language reasoning tasks remains challenging, as it often requires interpreting transitions of visual states to support reasoning. Existing methods often struggle with this due to limited capacity of modeling visual state transitions or incoherent visual trajectories caused by fragmented architectures. To overcome these limitations, we propose Uni-CoT, a Unified Chain-of-Thought framework that enables coherent and grounded multimodal reasoning within a single unified model. The key idea is to leverage a model capable of both image understanding and generation to reason over visual content and model evolving visual states. However, empowering a unified model to achieve that is non-trivial, given the high computational cost and the burden of training. To address this, Uni-CoT introduces a novel two-level reasoning paradigm: A Macro-Level CoT for high-level task planning and A Micro-Level CoT for subtask execution. This design significantly reduces the computational overhead. Furthermore, we introduce a structured training paradigm that combines interleaved image-text supervision for macro-level CoT with multi-task objectives for micro-level CoT. Together, these innovations allow Uni-CoT to perform scalable and coherent multi-modal reasoning. Furthermore, thanks to our design, all experiments can be efficiently completed using only 8 A100 GPUs with 80GB VRAM each. Experimental results on reasoning-driven image generation benchmark (WISE) and editing benchmarks (RISE and KRIS) indicates that Uni-CoT demonstrates SOTA performance and strong generalization, establishing Uni-CoT as a promising solution for multi-modal reasoning. Project Page and Code: https://sais-fuxi.github.io/projects/uni-cot/