Follow-Your-Instruction: A Comprehensive MLLM Agent for World Data Synthesis
作者: Kunyu Feng, Yue Ma, Xinhua Zhang, Boshi Liu, Yikuang Yuluo, Yinhan Zhang, Runtao Liu, Hongyu Liu, Zhiyuan Qin, Shanhui Mo, Qifeng Chen, Zeyu Wang
分类: cs.CV
发布日期: 2025-08-07
💡 一句话要点
提出Follow-Your-Instruction,一个基于MLLM的综合性Agent,用于世界数据自动合成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 数据合成 场景生成 视觉-语言模型 AIGC 3D数据 4D数据
📋 核心要点
- 现有方法依赖手动场景构建,导致数据收集成本高、耗时,且难以扩展和保证准确性。
- 提出Follow-Your-Instruction,利用MLLM驱动的框架自动合成高质量的2D、3D和4D数据。
- 实验结果表明,该方法生成的合成数据显著提升了现有基线模型的性能,验证了其有效性。
📝 摘要(中文)
随着AI生成内容(AIGC)需求的增长,对高质量、多样化和可扩展数据的需求变得至关重要。然而,收集大规模真实世界数据仍然成本高昂且耗时,阻碍了下游应用的发展。虽然一些工作尝试通过渲染过程收集特定任务的数据,但大多数方法仍然依赖于手动场景构建,限制了它们的可扩展性和准确性。为了应对这些挑战,我们提出了Follow-Your-Instruction,一个多模态大型语言模型(MLLM)驱动的框架,用于自动合成高质量的2D、3D和4D数据。我们的Follow-Your-Instruction首先通过MLLM-Collector使用多模态输入收集资产及其相关描述。然后,它构建3D布局,并利用视觉-语言模型(VLM)通过MLLM-Generator和MLLM-Optimizer进行多视角场景的语义细化。最后,它使用MLLM-Planner生成时间上连贯的未来帧。我们通过在2D、3D和4D生成任务上的综合实验评估了生成数据的质量。结果表明,我们的合成数据显著提高了现有基线模型的性能,证明了Follow-Your-Instruction作为生成智能的可扩展且有效的数据引擎的潜力。
🔬 方法详解
问题定义:论文旨在解决大规模、高质量、多样化世界数据的自动合成问题。现有方法主要依赖于手动场景构建或渲染,存在成本高昂、耗时、可扩展性差以及精度不足等痛点。这些问题严重制约了AIGC和下游应用的发展。
核心思路:论文的核心思路是利用多模态大型语言模型(MLLM)作为核心驱动力,构建一个自动化的数据生成流程。通过MLLM理解指令,收集资源,构建场景,优化细节,并生成时间连贯的视频数据。这种方法旨在摆脱对人工干预的依赖,实现数据生成的可扩展性和高效性。
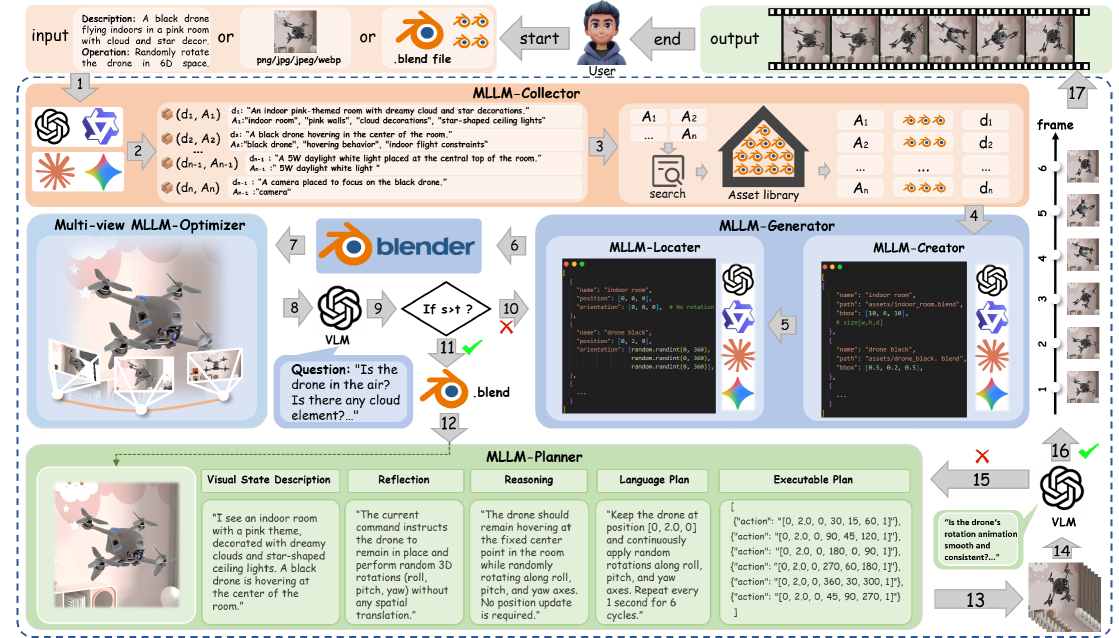
技术框架:Follow-Your-Instruction框架包含四个主要模块:MLLM-Collector、MLLM-Generator、MLLM-Optimizer和MLLM-Planner。MLLM-Collector负责收集资产及其描述;MLLM-Generator构建3D场景布局;MLLM-Optimizer利用视觉-语言模型进行多视角语义细化;MLLM-Planner生成时间连贯的未来帧。整个流程通过MLLM的协调,实现从指令到多维度数据的自动生成。
关键创新:该方法最重要的创新在于将MLLM作为数据生成流程的核心驱动力。与以往依赖人工或简单规则的方法不同,Follow-Your-Instruction能够理解复杂的指令,并利用MLLM的推理能力进行场景构建、语义细化和时间序列生成。这种基于MLLM的自动化数据生成方法具有更高的灵活性、可扩展性和智能化程度。
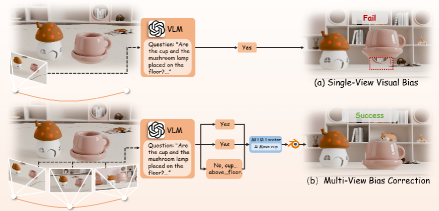
关键设计:具体的技术细节包括:(1) 使用多模态输入(文本、图像等)指导MLLM-Collector进行资源收集;(2) 利用视觉-语言模型(VLM)进行多视角语义一致性优化,确保生成场景的真实感;(3) 设计MLLM-Planner以保证生成视频帧之间的时间连贯性,避免出现突兀的变化。具体的参数设置、损失函数和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
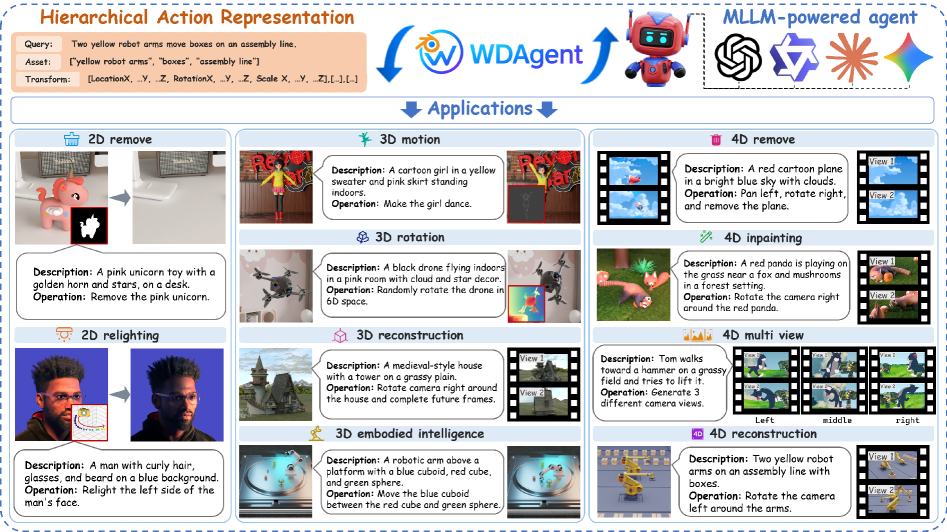
📊 实验亮点
实验结果表明,使用Follow-Your-Instruction生成的合成数据能够显著提升现有基线模型在2D、3D和4D生成任务上的性能。具体提升幅度和对比基线在摘要中未明确指出,属于未知信息。该结果验证了该方法作为可扩展数据引擎的潜力。
🎯 应用场景
该研究成果可广泛应用于游戏开发、电影制作、机器人训练、自动驾驶模拟等领域。通过自动生成高质量、多样化的训练数据,可以显著降低数据获取成本,加速相关AI模型的开发和部署,并推动AIGC技术的发展。
📄 摘要(原文)
With the growing demands of AI-generated content (AIGC), the need for high-quality, diverse, and scalable data has become increasingly crucial. However, collecting large-scale real-world data remains costly and time-consuming, hindering the development of downstream applications. While some works attempt to collect task-specific data via a rendering process, most approaches still rely on manual scene construction, limiting their scalability and accuracy. To address these challenges, we propose Follow-Your-Instruction, a Multimodal Large Language Model (MLLM)-driven framework for automatically synthesizing high-quality 2D, 3D, and 4D data. Our \textbf{Follow-Your-Instruction} first collects assets and their associated descriptions through multimodal inputs using the MLLM-Collector. Then it constructs 3D layouts, and leverages Vision-Language Models (VLMs) for semantic refinement through multi-view scenes with the MLLM-Generator and MLLM-Optimizer, respectively. Finally, it uses MLLM-Planner to generate temporally coherent future frames. We evaluate the quality of the generated data through comprehensive experiments on the 2D, 3D, and 4D generative tasks. The results show that our synthetic data significantly boosts the performance of existing baseline models, demonstrating Follow-Your-Instruction's potential as a scalable and effective data engine for generative intelligence.