MagicHOI: Leveraging 3D Priors for Accurate Hand-object Reconstruction from Short Monocular Video Clips
作者: Shibo Wang, Haonan He, Maria Parelli, Christoph Gebhardt, Zicong Fan, Jie Song
分类: cs.CV
发布日期: 2025-08-07
💡 一句话要点
MagicHOI:利用3D先验从单目短视频中精确重建手-物交互
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 手-物交互 三维重建 单目视频 新视角合成 扩散模型 物体先验 人机交互
📋 核心要点
- 现有手-物重建方法在物体部分遮挡或视角有限的情况下表现不佳,难以得到合理的三维重建结果。
- MagicHOI利用大规模新视角合成扩散模型作为先验知识,对未见物体区域进行正则化,提升重建效果。
- 实验表明,MagicHOI显著优于现有方法,证明了新视角合成扩散先验在手-物重建中的有效性。
📝 摘要(中文)
大多数基于RGB的手-物重建方法依赖于物体模板,而无模板方法通常假设物体完全可见。然而,在实际场景中,固定相机视角和静态抓握会导致物体部分不可见,从而导致不合理的重建结果。为了解决这个问题,我们提出了MagicHOI,一种从单目交互短视频中重建手和物体的方法,即使在有限的视角变化下也能有效工作。我们的核心思想是,尽管配对的3D手-物数据稀缺,但大规模的新视角合成扩散模型提供了丰富的物体监督。这种监督作为先验,用于在手部交互期间正则化未见物体的区域。基于此,我们将新视角合成模型集成到我们的手-物重建框架中。我们还通过结合可见接触约束来对齐手和物体。实验结果表明,MagicHOI显著优于现有的最先进的手-物重建方法。我们还证明了新视角合成扩散先验有效地正则化了未见物体区域,从而增强了3D手-物重建。
🔬 方法详解
问题定义:现有基于RGB的手-物交互重建方法,要么依赖于预定义的物体模板,限制了泛化能力;要么假设物体完全可见,这在实际场景中通常不成立,因为固定视角和手部遮挡会导致物体部分不可见,从而影响重建质量。因此,如何在物体部分遮挡和视角有限的情况下,实现准确的手-物交互重建是一个关键问题。
核心思路:论文的核心思路是利用大规模新视角合成扩散模型提供的物体先验知识,来正则化重建过程中未见物体的区域。即使物体部分被遮挡,扩散模型也能提供关于物体形状和外观的合理估计,从而帮助重建算法生成更准确和完整的3D模型。这种方法避免了对物体模板的依赖,并减轻了对物体完全可见的假设。
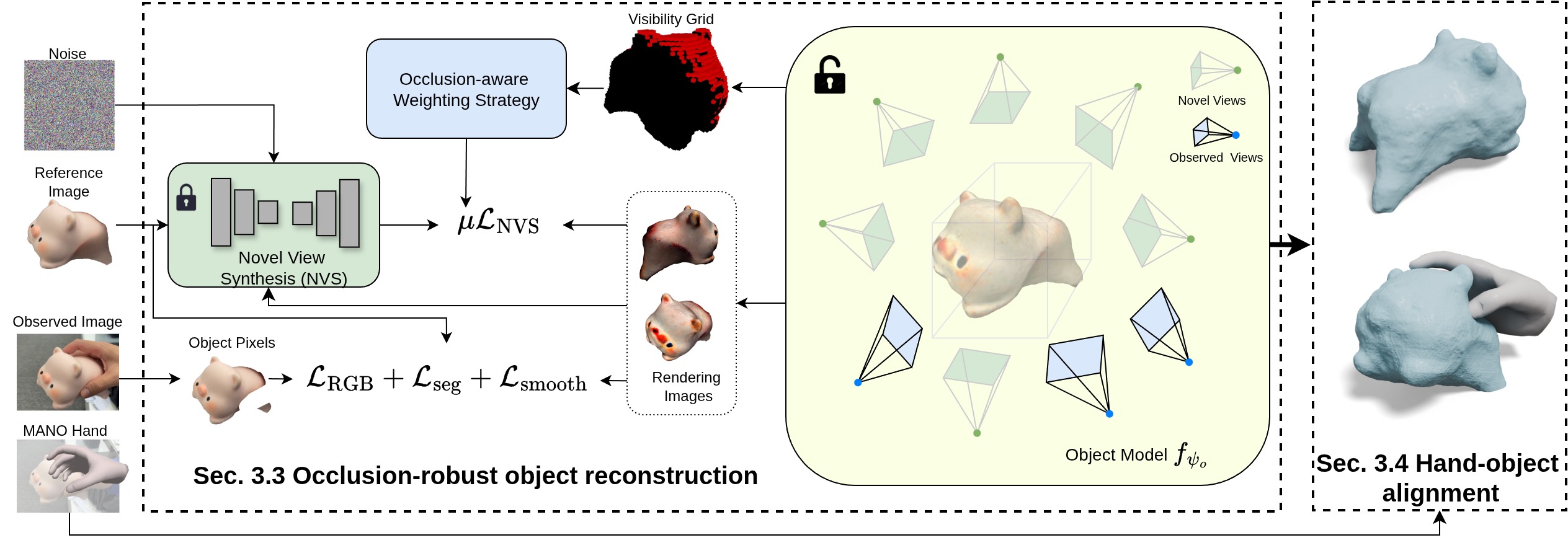
技术框架:MagicHOI的整体框架包含以下几个主要模块:1) 从单目视频中提取手部和物体的2D关键点;2) 使用手部和物体的2D关键点初始化3D手部和物体姿态;3) 利用新视角合成扩散模型生成物体在不同视角下的图像;4) 使用生成的图像作为先验知识,正则化物体重建过程,优化手部和物体的3D姿态和形状;5) 结合可见接触约束,进一步对齐手部和物体。
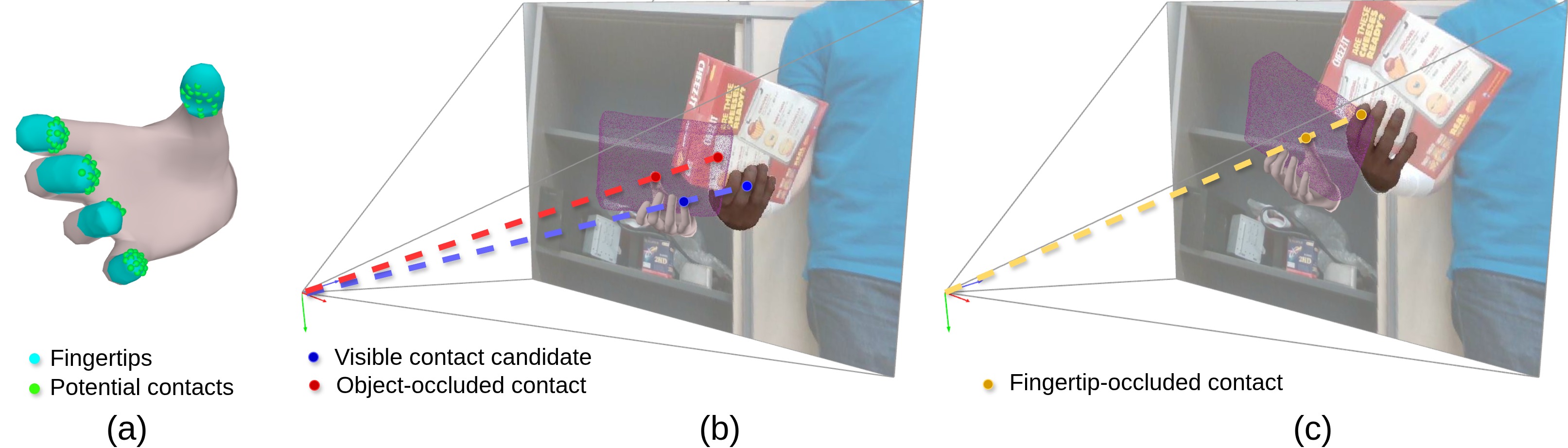
关键创新:最重要的技术创新点是将新视角合成扩散模型引入到手-物交互重建中,并将其作为一种先验知识来正则化未见物体的区域。与现有方法相比,MagicHOI不需要预定义的物体模板,也不需要物体完全可见,因此具有更强的泛化能力和鲁棒性。此外,结合可见接触约束进一步提升了手部和物体的对齐精度。
关键设计:论文的关键设计包括:1) 使用预训练的新视角合成扩散模型,例如DreamFusion或类似的模型,来生成物体在不同视角下的图像;2) 设计合适的损失函数,将扩散模型生成的图像作为正则化项,约束物体重建过程;3) 使用可见接触约束,例如惩罚手部和物体之间的穿透,来对齐手部和物体;4) 通过迭代优化手部和物体的3D姿态和形状,最终得到准确的手-物交互重建结果。
🖼️ 关键图片
📊 实验亮点
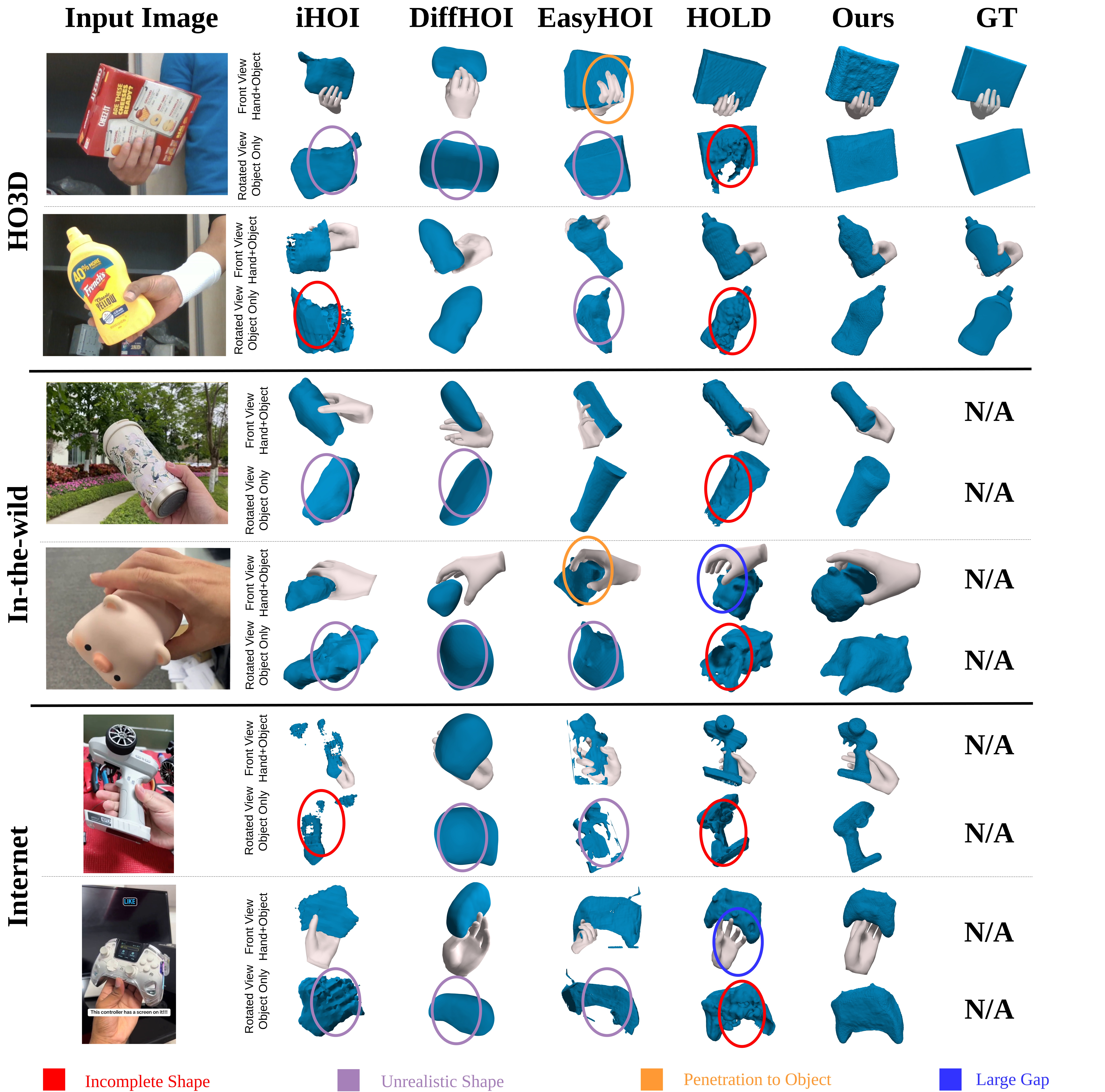
实验结果表明,MagicHOI在手-物重建精度上显著优于现有方法。例如,在HOI4D数据集上,MagicHOI在手部和物体的3D姿态和形状重建误差方面均取得了显著降低。与基线方法相比,MagicHOI能够生成更合理和完整的手-物交互3D模型,尤其是在物体部分遮挡的情况下。
🎯 应用场景
MagicHOI技术可应用于人机交互、虚拟现实/增强现实、机器人操作等领域。例如,在VR/AR中,可以更真实地模拟手与虚拟物体的交互;在机器人操作中,可以帮助机器人更好地理解和执行涉及手部操作的任务。该研究的未来影响在于提升人机交互的自然性和真实感,并促进机器人智能的发展。
📄 摘要(原文)
Most RGB-based hand-object reconstruction methods rely on object templates, while template-free methods typically assume full object visibility. This assumption often breaks in real-world settings, where fixed camera viewpoints and static grips leave parts of the object unobserved, resulting in implausible reconstructions. To overcome this, we present MagicHOI, a method for reconstructing hands and objects from short monocular interaction videos, even under limited viewpoint variation. Our key insight is that, despite the scarcity of paired 3D hand-object data, large-scale novel view synthesis diffusion models offer rich object supervision. This supervision serves as a prior to regularize unseen object regions during hand interactions. Leveraging this insight, we integrate a novel view synthesis model into our hand-object reconstruction framework. We further align hand to object by incorporating visible contact constraints. Our results demonstrate that MagicHOI significantly outperforms existing state-of-the-art hand-object reconstruction methods. We also show that novel view synthesis diffusion priors effectively regularize unseen object regions, enhancing 3D hand-object reconstruction.