RegionMed-CLIP: A Region-Aware Multimodal Contrastive Learning Pre-trained Model for Medical Image Understanding
作者: Tianchen Fang, Guiru Liu
分类: cs.CV, cs.AI
发布日期: 2025-08-07 (更新: 2025-09-19)
备注: Upon further review, we identified that our dataset requires optimization to ensure research reliability and accuracy. Additionally, considering the target journal's latest submission policies, we believe comprehensive manuscript revisions are necessary
💡 一句话要点
提出RegionMed-CLIP,通过区域感知多模态对比学习提升医学图像理解能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学图像理解 多模态学习 对比学习 区域感知 预训练
📋 核心要点
- 现有医学图像理解方法依赖全局特征,忽略了关键病理区域的细微信息,限制了诊断精度。
- RegionMed-CLIP通过引入区域感知机制,自适应地融合局部区域特征与全局上下文,实现更精准的医学图像理解。
- 实验表明,RegionMed-CLIP在多个任务上显著超越现有视觉语言模型,验证了区域感知对比预训练的有效性。
📝 摘要(中文)
医学图像理解在自动化诊断和数据驱动的临床决策支持中至关重要。然而,高质量标注医学数据的稀缺以及过度依赖全局图像特征,忽略细微但具有临床意义的病理区域,阻碍了其发展。为了解决这些问题,我们提出了RegionMed-CLIP,一个区域感知的多模态对比学习框架,它显式地结合了局部病理信号和整体语义表示。该方法的核心是一个创新的感兴趣区域(ROI)处理器,它自适应地将细粒度的区域特征与全局上下文集成,并由渐进式训练策略支持,从而增强分层多模态对齐。为了实现大规模的区域级表示学习,我们构建了MedRegion-500k,一个包含广泛区域注释和多层次临床描述的综合医学图像-文本语料库。在图像-文本检索、零样本分类和视觉问答任务上的大量实验表明,RegionMed-CLIP始终大幅超越最先进的视觉语言模型。我们的结果突出了区域感知对比预训练的关键重要性,并将RegionMed-CLIP定位为推进多模态医学图像理解的强大基础。
🔬 方法详解
问题定义:医学图像理解面临两大挑战:一是高质量标注数据的匮乏,二是现有方法过度依赖全局图像特征,忽略了局部病理区域的关键信息。这些痛点导致模型无法准确捕捉细微的病灶特征,影响诊断的准确性和可靠性。
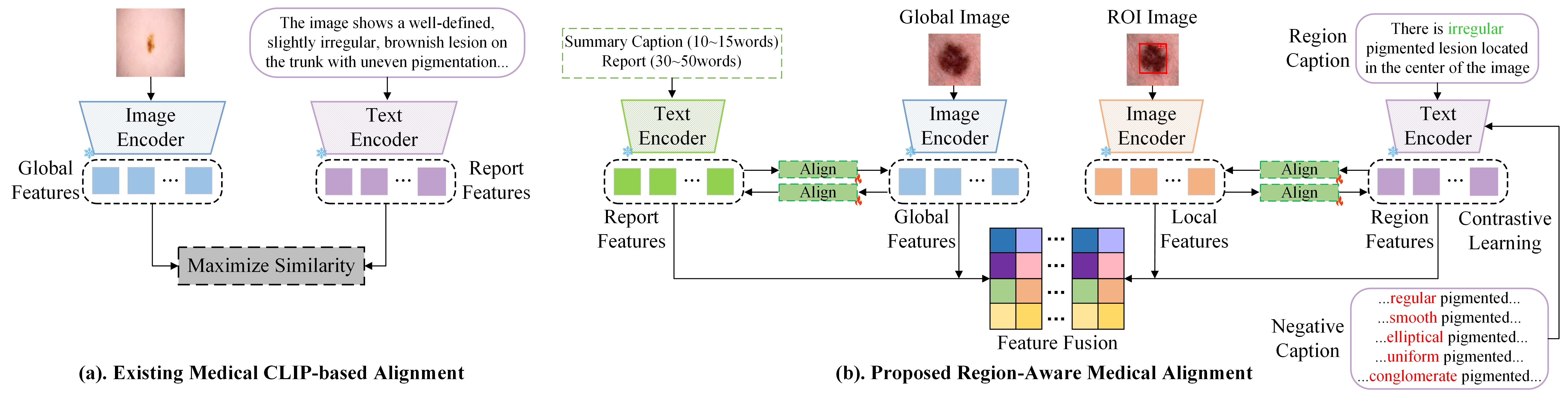
核心思路:RegionMed-CLIP的核心思路是引入区域感知机制,显式地将局部病理区域的特征融入到模型的学习过程中。通过关注图像中的特定区域,模型能够更好地捕捉细微的病灶信息,从而提高医学图像理解的准确性。这种方法旨在弥补全局特征的不足,提升模型对局部病理特征的敏感度。
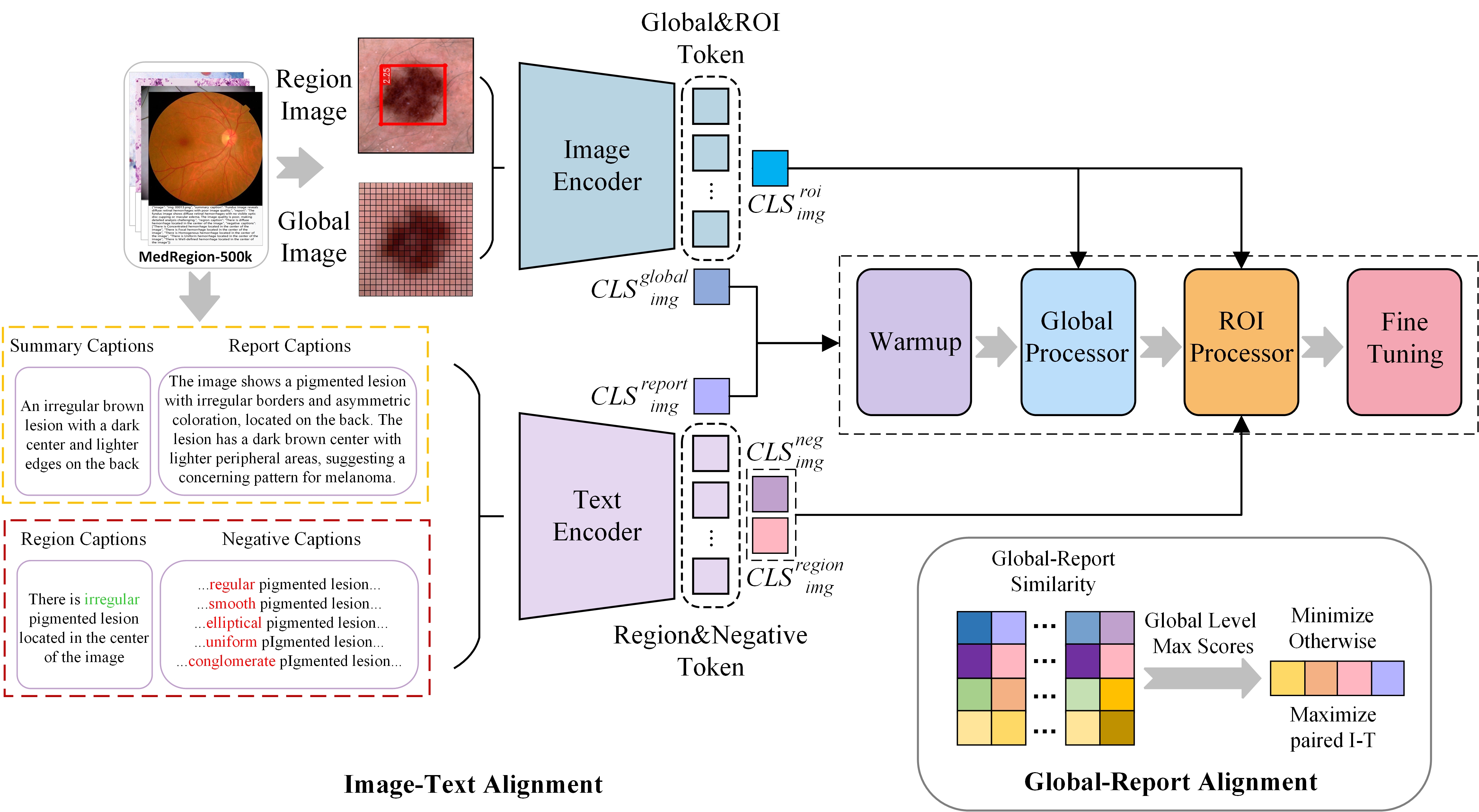
技术框架:RegionMed-CLIP的整体框架包含以下几个主要模块:首先,使用图像编码器提取全局图像特征;然后,通过ROI处理器提取感兴趣区域的特征,该处理器能够自适应地将细粒度的区域特征与全局上下文信息融合;接着,使用文本编码器提取文本描述的特征;最后,通过对比学习损失函数,使图像和文本在特征空间中对齐。此外,该框架还采用了渐进式训练策略,逐步增强分层多模态对齐。
关键创新:RegionMed-CLIP的关键创新在于其区域感知的多模态对比学习方法。与传统的全局特征学习方法不同,RegionMed-CLIP显式地关注图像中的特定区域,并将其特征融入到模型的学习过程中。这种方法能够更好地捕捉细微的病灶信息,提高医学图像理解的准确性。此外,该论文还构建了一个大规模的医学图像-文本语料库MedRegion-500k,为区域级表示学习提供了数据支持。
关键设计:ROI处理器是该方法中的一个关键设计,它能够自适应地将细粒度的区域特征与全局上下文信息融合。具体的实现方式未知,但可以推测可能使用了注意力机制或者其他特征融合方法。此外,对比学习损失函数的选择和参数设置也是影响模型性能的关键因素。渐进式训练策略可能涉及不同层级的特征对齐,例如先对齐全局特征,再对齐区域特征。
🖼️ 关键图片

📊 实验亮点
RegionMed-CLIP在图像-文本检索、零样本分类和视觉问答等任务上均取得了显著的性能提升,大幅超越了现有的视觉语言模型。具体的性能数据未知,但摘要中强调了“wide margin”,表明提升幅度较大。这些实验结果充分验证了区域感知对比预训练的有效性,并证明了RegionMed-CLIP在医学图像理解方面的优越性。
🎯 应用场景
RegionMed-CLIP在医学图像理解领域具有广泛的应用前景,可用于辅助诊断、疾病筛查、病情监测等方面。通过提高医学图像理解的准确性和效率,该研究有望改善临床决策支持系统,提升医疗服务质量,并最终惠及广大患者。未来,该模型可以进一步扩展到其他医学影像模态,例如CT、MRI等,并与其他临床数据相结合,实现更全面的疾病诊断和管理。
📄 摘要(原文)
Medical image understanding plays a crucial role in enabling automated diagnosis and data-driven clinical decision support. However, its progress is impeded by two primary challenges: the limited availability of high-quality annotated medical data and an overreliance on global image features, which often miss subtle but clinically significant pathological regions. To address these issues, we introduce RegionMed-CLIP, a region-aware multimodal contrastive learning framework that explicitly incorporates localized pathological signals along with holistic semantic representations. The core of our method is an innovative region-of-interest (ROI) processor that adaptively integrates fine-grained regional features with the global context, supported by a progressive training strategy that enhances hierarchical multimodal alignment. To enable large-scale region-level representation learning, we construct MedRegion-500k, a comprehensive medical image-text corpus that features extensive regional annotations and multilevel clinical descriptions. Extensive experiments on image-text retrieval, zero-shot classification, and visual question answering tasks demonstrate that RegionMed-CLIP consistently exceeds state-of-the-art vision language models by a wide margin. Our results highlight the critical importance of region-aware contrastive pre-training and position RegionMed-CLIP as a robust foundation for advancing multimodal medical image understanding.