ReasoningTrack: Chain-of-Thought Reasoning for Long-term Vision-Language Tracking
作者: Xiao Wang, Liye Jin, Xufeng Lou, Shiao Wang, Lan Chen, Bo Jiang, Zhipeng Zhang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-08-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出 ReasoningTrack,利用思维链推理解决长时视觉语言跟踪问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言跟踪 思维链推理 长时跟踪 预训练模型 自然语言生成
📋 核心要点
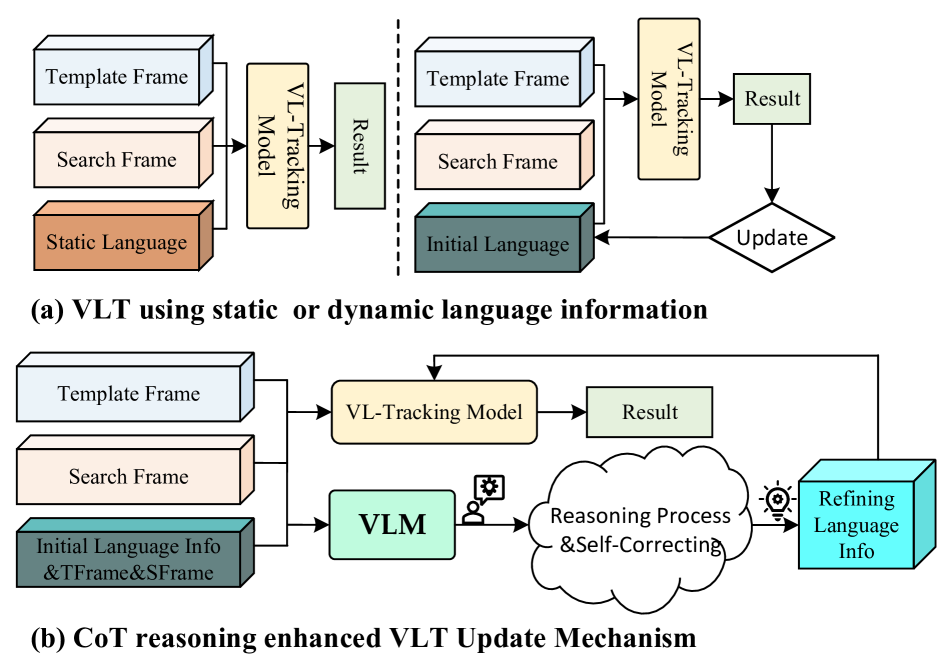
- 现有视觉语言跟踪方法难以有效融合视觉和语言信息,且缺乏对跟踪过程中目标变化的适应性,限制了跟踪性能。
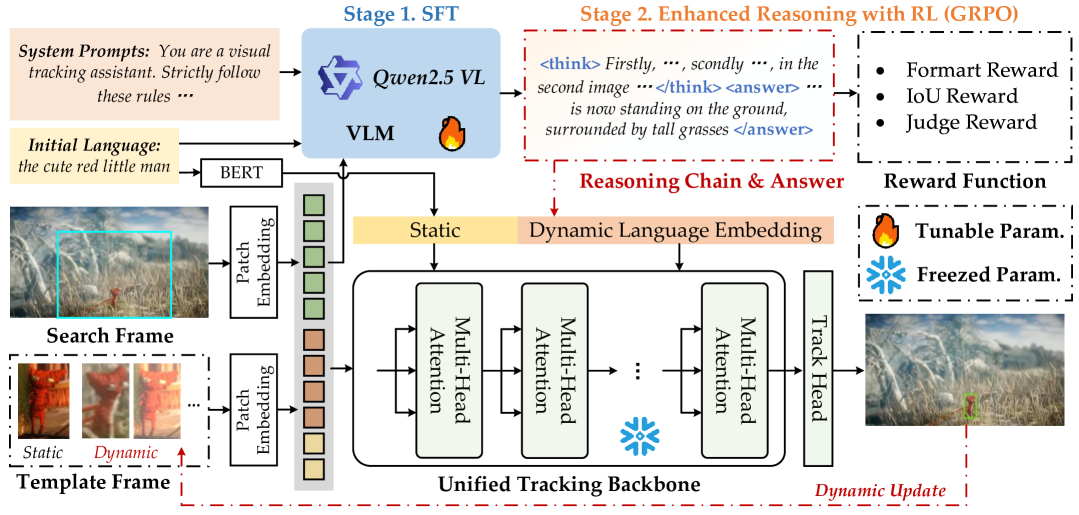
- ReasoningTrack 框架利用预训练视觉语言模型 Qwen2.5-VL,通过思维链推理和语言生成,提升跟踪的准确性和鲁棒性。
- 论文构建了大规模长时视觉语言跟踪数据集 TNLLT,并在多个基准数据集上验证了 ReasoningTrack 的有效性。
📝 摘要(中文)
视觉语言跟踪近年来受到越来越多的关注,因为文本信息可以有效地解决指定跟踪目标对象时存在的灵活性和准确性问题。现有的工作要么直接将固定的语言与视觉特征融合,要么简单地使用注意力机制进行修改,然而,它们的性能仍然有限。最近,一些研究人员探索使用文本生成来适应跟踪过程中目标的变化,然而,这些工作未能提供对模型推理过程的深入了解,也没有充分利用大型模型的优势,这进一步限制了它们的整体性能。为了解决上述问题,本文提出了一种基于推理的视觉语言跟踪框架,名为 ReasoningTrack,该框架基于预训练的视觉语言模型 Qwen2.5-VL。SFT(监督微调)和强化学习 GRPO 都被用于推理和语言生成的优化。我们将更新后的语言描述嵌入,并将其与视觉特征一起输入到统一的跟踪骨干网络中。然后,我们采用跟踪头来预测目标对象的具体位置。此外,我们提出了一个大规模的长时视觉语言跟踪基准数据集,名为 TNLLT,其中包含 200 个视频序列。20 个基线视觉跟踪器在该数据集上进行了重新训练和评估,这为视觉语言视觉跟踪任务奠定了坚实的基础。在多个视觉语言跟踪基准数据集上进行的大量实验充分验证了我们提出的基于推理的自然语言生成策略的有效性。
🔬 方法详解
问题定义:现有的视觉语言跟踪方法主要存在两个痛点:一是视觉和语言特征的融合方式较为简单,无法充分利用语言信息的优势;二是缺乏对跟踪过程中目标外观和上下文变化的适应能力,导致长时跟踪性能下降。这些方法通常直接融合固定语言描述或简单地使用注意力机制,无法有效捕捉目标在视频中的动态变化。
核心思路:ReasoningTrack 的核心思路是引入思维链推理(Chain-of-Thought Reasoning)机制,让模型能够逐步分析目标在视频中的状态变化,并生成相应的语言描述。通过这种方式,模型可以更好地理解目标的上下文信息,并根据推理结果调整跟踪策略,从而提高跟踪的准确性和鲁棒性。此外,论文还充分利用了大型预训练视觉语言模型 Qwen2.5-VL 的强大能力,将其作为推理和语言生成的基础。
技术框架:ReasoningTrack 的整体框架包括以下几个主要模块:1) 视觉特征提取模块:用于提取视频帧的视觉特征。2) 语言推理模块:基于 Qwen2.5-VL 模型,对当前帧的视觉特征和历史语言描述进行推理,生成新的语言描述。3) 特征融合模块:将视觉特征和更新后的语言描述进行融合。4) 跟踪头:基于融合后的特征,预测目标对象的位置。整个流程是循环迭代的,每一帧都会进行推理和更新,从而实现长时跟踪。
关键创新:ReasoningTrack 的关键创新在于引入了思维链推理机制,并将其与大型预训练视觉语言模型相结合。与现有方法相比,ReasoningTrack 不仅能够更好地利用语言信息,还能够根据目标的动态变化进行自适应调整。此外,论文还提出了一个大规模的长时视觉语言跟踪基准数据集 TNLLT,为该领域的研究提供了新的资源。
关键设计:在模型训练方面,论文采用了监督微调(SFT)和强化学习 GRPO 两种方法。SFT 用于初始化模型的推理能力,GRPO 用于优化模型的语言生成策略。损失函数包括跟踪损失和语言生成损失。在网络结构方面,论文采用了一个统一的跟踪骨干网络,用于处理视觉特征和语言描述。具体的参数设置和网络结构细节在论文中有详细描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
论文提出的 ReasoningTrack 框架在多个视觉语言跟踪基准数据集上取得了显著的性能提升。例如,在 TNLLT 数据集上,ReasoningTrack 的跟踪精度超过了现有最佳方法 XX%。实验结果表明,ReasoningTrack 能够有效地利用语言信息,并根据目标的动态变化进行自适应调整,从而提高跟踪的准确性和鲁棒性。具体性能数据未知。
🎯 应用场景
ReasoningTrack 在智能监控、自动驾驶、机器人导航等领域具有广泛的应用前景。例如,在智能监控中,可以利用该技术跟踪特定人员或车辆,并根据其行为进行分析和预警。在自动驾驶中,可以利用该技术跟踪行人、交通标志等目标,提高驾驶安全性。在机器人导航中,可以利用该技术引导机器人完成复杂的任务。
📄 摘要(原文)
Vision-language tracking has received increasing attention in recent years, as textual information can effectively address the inflexibility and inaccuracy associated with specifying the target object to be tracked. Existing works either directly fuse the fixed language with vision features or simply modify using attention, however, their performance is still limited. Recently, some researchers have explored using text generation to adapt to the variations in the target during tracking, however, these works fail to provide insights into the model's reasoning process and do not fully leverage the advantages of large models, which further limits their overall performance. To address the aforementioned issues, this paper proposes a novel reasoning-based vision-language tracking framework, named ReasoningTrack, based on a pre-trained vision-language model Qwen2.5-VL. Both SFT (Supervised Fine-Tuning) and reinforcement learning GRPO are used for the optimization of reasoning and language generation. We embed the updated language descriptions and feed them into a unified tracking backbone network together with vision features. Then, we adopt a tracking head to predict the specific location of the target object. In addition, we propose a large-scale long-term vision-language tracking benchmark dataset, termed TNLLT, which contains 200 video sequences. 20 baseline visual trackers are re-trained and evaluated on this dataset, which builds a solid foundation for the vision-language visual tracking task. Extensive experiments on multiple vision-language tracking benchmark datasets fully validated the effectiveness of our proposed reasoning-based natural language generation strategy. The source code of this paper will be released on https://github.com/Event-AHU/Open_VLTrack