X-MoGen: Unified Motion Generation across Humans and Animals
作者: Xuan Wang, Kai Ruan, Liyang Qian, Zhizhi Guo, Chang Su, Gaoang Wang
分类: cs.CV
发布日期: 2025-08-07 (更新: 2025-11-16)
💡 一句话要点
X-MoGen:首个跨人类与动物的统一运动生成框架,提升运动真实性与泛化性
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 运动生成 跨物种 文本驱动 统一框架 形态一致性 图变分自编码器 掩码运动建模
📋 核心要点
- 现有文本驱动运动生成方法通常独立建模人类和动物运动,缺乏统一表示和跨物种泛化能力。
- X-MoGen通过两阶段架构,利用条件图变分自编码器和形态一致性模块,学习跨物种的共享运动潜在空间。
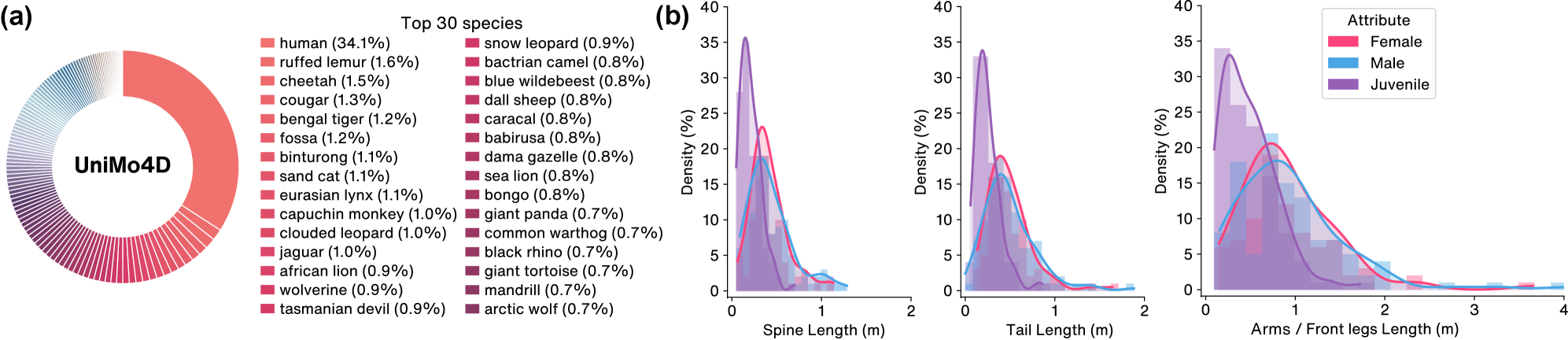
- UniMo4D数据集上的实验表明,X-MoGen在已见和未见物种上均超越现有方法,提升了运动生成的真实性和泛化性。
📝 摘要(中文)
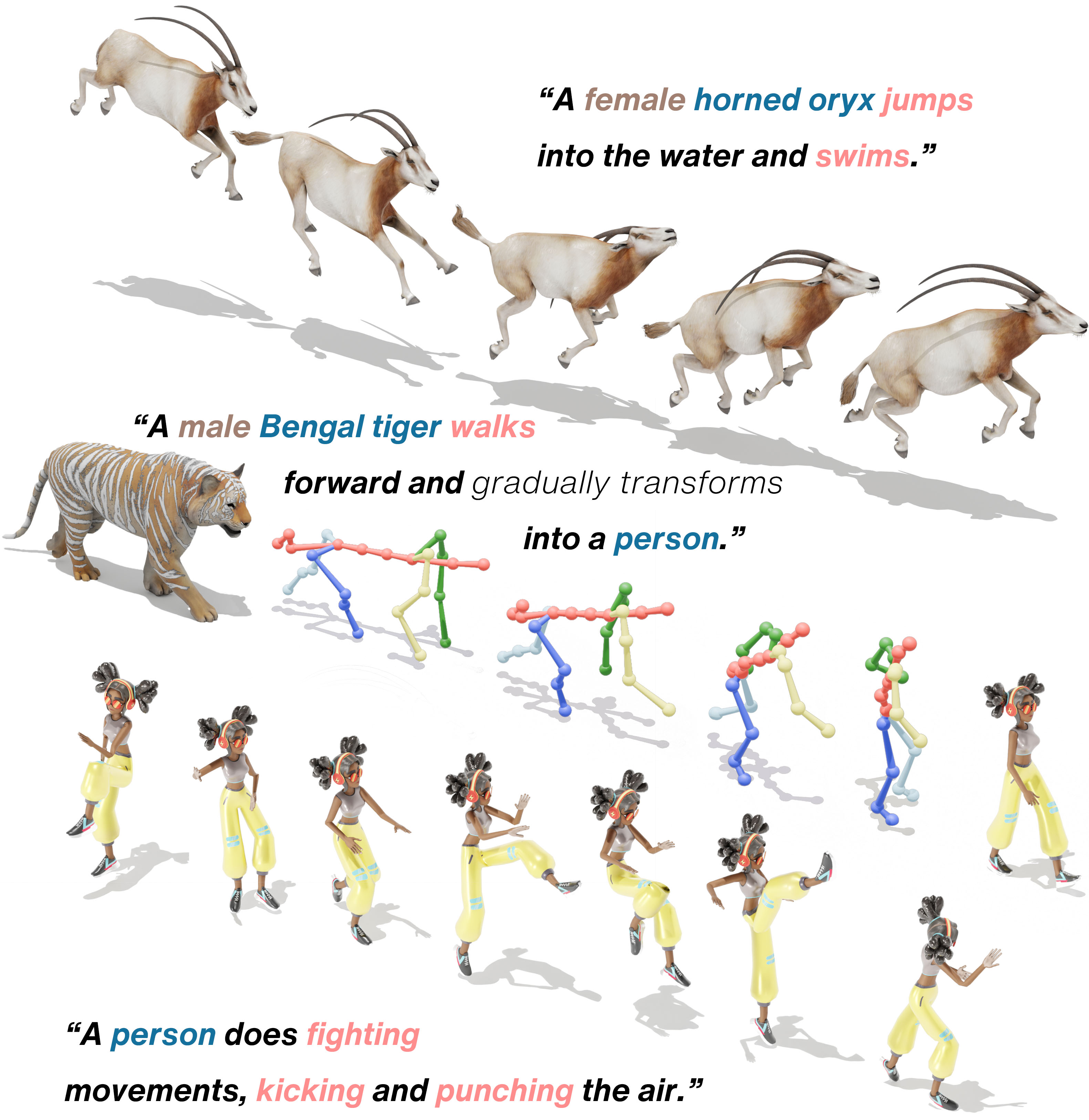
本文提出X-MoGen,首个统一框架,用于跨物种的文本驱动运动生成,涵盖人类和动物。现有方法通常独立建模人类和动物运动,而联合跨物种方法具有统一表示和改进泛化等关键优势。然而,物种间的形态差异仍然是一个关键挑战,经常会损害运动的合理性。为了解决这个问题,X-MoGen采用了两阶段架构。首先,条件图变分自编码器学习规范的T-pose先验,而自编码器将运动编码到由形态损失正则化的共享潜在空间中。在第二阶段,我们执行掩码运动建模,以生成以文本描述为条件的运动嵌入。在训练期间,采用形态一致性模块来提高跨物种的骨骼合理性。为了支持统一建模,我们构建了UniMo4D,一个包含115个物种和119k运动序列的大规模数据集,该数据集在共享骨骼拓扑下集成了人类和动物运动,用于联合训练。在UniMo4D上的大量实验表明,X-MoGen在已见和未见物种上均优于最先进的方法。
🔬 方法详解
问题定义:现有文本驱动的运动生成方法通常针对人类或特定动物分别建模,缺乏跨物种的统一表示和泛化能力。不同物种的形态差异导致难以生成合理的运动,尤其是在未见过的物种上表现更差。因此,如何构建一个能够处理多种物种、生成逼真运动的统一框架是一个关键问题。
核心思路:X-MoGen的核心思路是学习一个跨物种的共享运动潜在空间,并利用形态一致性约束来保证生成运动的合理性。通过将不同物种的运动映射到统一的潜在空间,模型可以学习到通用的运动模式,从而实现跨物种的运动生成。形态一致性约束则确保生成的运动在骨骼结构上是合理的,避免出现不自然的姿势。
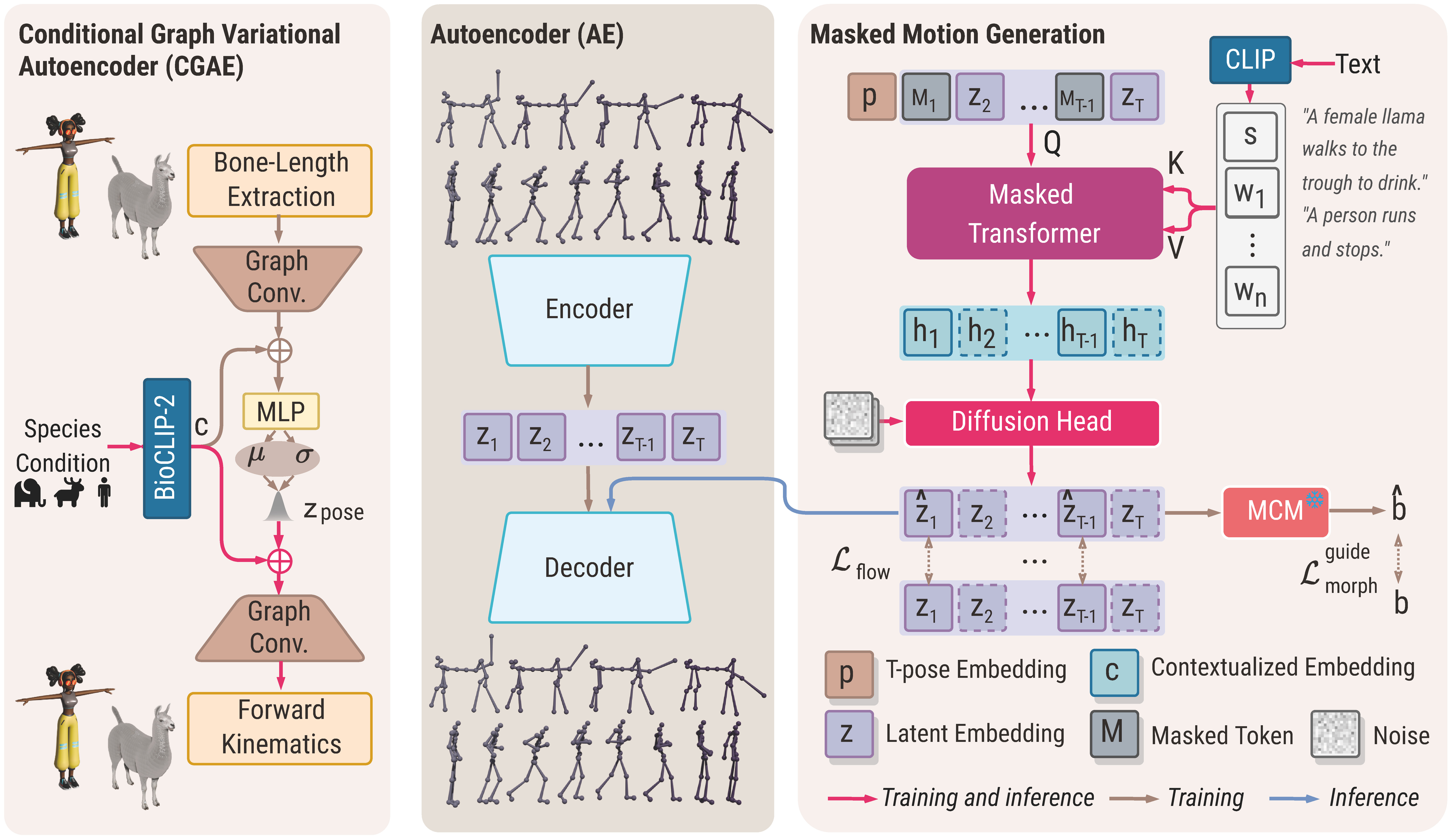
技术框架:X-MoGen采用两阶段架构: 1. T-pose先验学习:使用条件图变分自编码器(Conditional Graph Variational Autoencoder)学习规范的T-pose先验,捕捉不同物种的骨骼结构信息。 2. 运动编码与生成:使用自编码器将运动序列编码到共享潜在空间中,并使用形态损失(Morphological Loss)进行正则化。然后,通过掩码运动建模(Masked Motion Modeling)生成以文本描述为条件的运动嵌入。
关键创新:X-MoGen的关键创新在于: 1. 统一的跨物种运动生成框架:首次提出了一个能够同时处理人类和动物运动的统一框架。 2. 形态一致性模块:通过形态一致性模块,保证了生成运动在骨骼结构上的合理性,避免了不自然的姿势。 3. UniMo4D数据集:构建了一个包含115个物种和119k运动序列的大规模数据集,为跨物种运动生成提供了数据支持。
关键设计: 1. 形态损失(Morphological Loss):用于约束自编码器学习到的潜在空间,保证不同物种的运动在潜在空间中具有相似的表示。 2. 形态一致性模块:通过比较生成运动和真实运动的骨骼结构,计算一致性损失,从而保证生成运动的合理性。 3. 掩码运动建模(Masked Motion Modeling):通过随机掩盖部分运动帧,并使用文本描述作为条件进行预测,从而提高模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
X-MoGen在UniMo4D数据集上进行了广泛的实验,结果表明,X-MoGen在已见和未见物种上均优于现有方法。具体来说,X-MoGen在运动真实性和文本匹配度等指标上均取得了显著提升,尤其是在未见物种上的表现尤为突出,证明了X-MoGen具有良好的泛化能力。
🎯 应用场景
X-MoGen具有广泛的应用前景,包括虚拟现实、动画制作、游戏开发和机器人控制等领域。它可以用于生成各种生物的逼真运动,例如在虚拟现实环境中创建栩栩如生的人物和动物角色,或者在游戏中生成各种生物的运动动画。此外,X-MoGen还可以用于机器人控制,例如控制机器人模仿动物的运动方式,从而提高机器人的运动能力。
📄 摘要(原文)
Text-driven motion generation has attracted increasing attention due to its broad applications in virtual reality, animation, and robotics. While existing methods typically model human and animal motion separately, a joint cross-species approach offers key advantages, such as a unified representation and improved generalization. However, morphological differences across species remain a key challenge, often compromising motion plausibility. To address this, we propose X-MoGen, the first unified framework for cross-species text-driven motion generation covering both humans and animals. X-MoGen adopts a two-stage architecture. First, a conditional graph variational autoencoder learns canonical T-pose priors, while an autoencoder encodes motion into a shared latent space regularized by morphological loss. In the second stage, we perform masked motion modeling to generate motion embeddings conditioned on textual descriptions. During training, a morphological consistency module is employed to promote skeletal plausibility across species. To support unified modeling, we construct UniMo4D, a large-scale dataset of 115 species and 119k motion sequences, which integrates human and animal motions under a shared skeletal topology for joint training. Extensive experiments on UniMo4D demonstrate that X-MoGen outperforms state-of-the-art methods on both seen and unseen species.