Latent Expression Generation for Referring Image Segmentation and Grounding
作者: Seonghoon Yu, Junbeom Hong, Joonseok Lee, Jeany Son
分类: cs.CV, cs.AI
发布日期: 2025-08-07 (更新: 2025-08-18)
备注: Accepted to ICCV 2025
💡 一句话要点
提出基于隐式表达生成的视觉定位框架,提升指代图像分割和定位性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指代图像分割 指代表达理解 视觉定位 隐式表达生成 对比学习
📋 核心要点
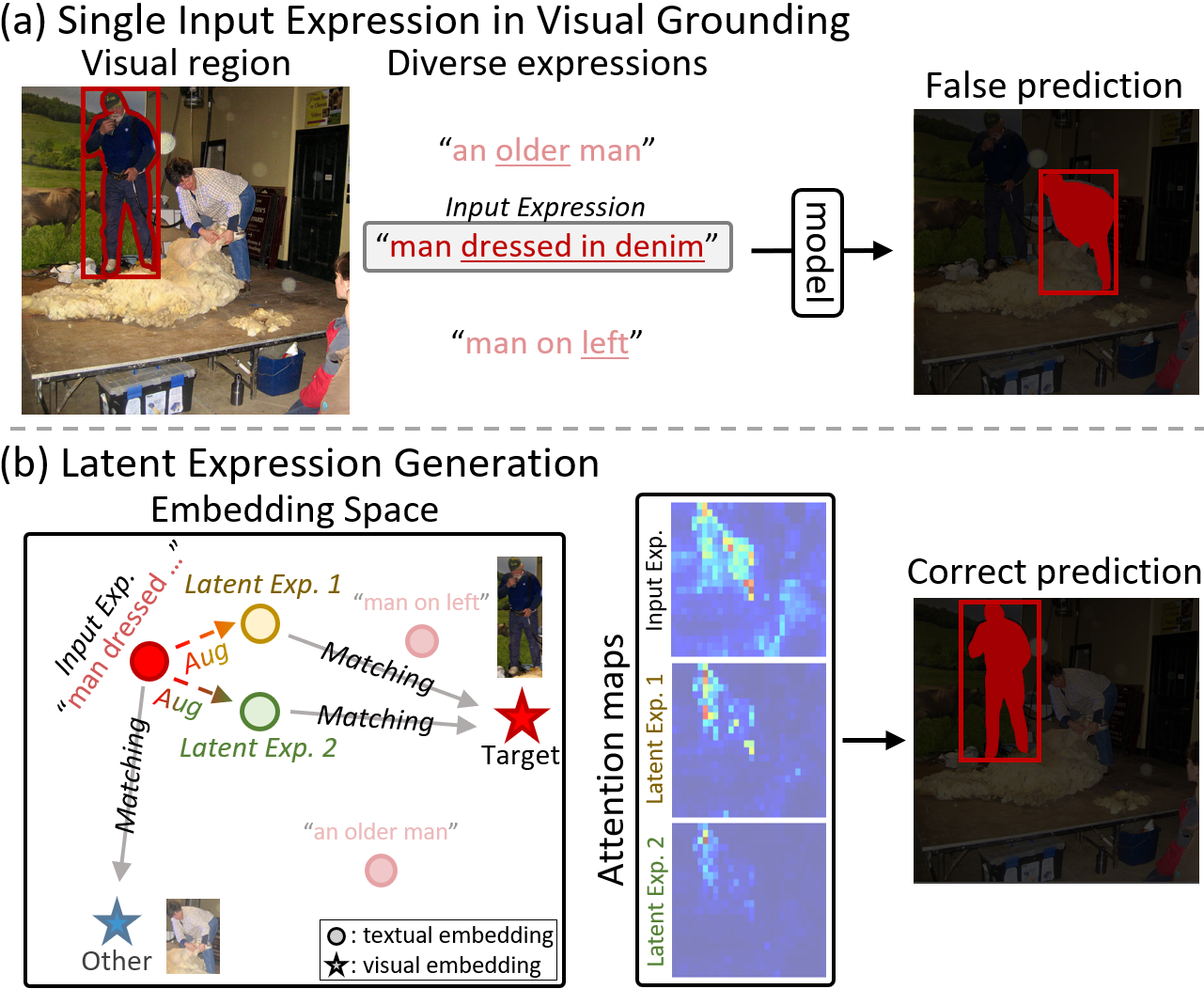
- 现有指代图像分割和定位方法依赖单一文本输入,无法充分利用图像中丰富的视觉信息,导致定位精度受限。
- 论文提出一种新的视觉定位框架,通过生成多个隐式表达来补充文本信息,从而捕捉更全面的视觉线索。
- 实验结果表明,该方法在RIS、REC和GRES等多个基准测试中均优于现有方法,显著提升了定位性能。
📝 摘要(中文)
视觉定位任务,如指代图像分割(RIS)和指代表达理解(REC),旨在根据给定的文本描述定位目标对象。图像中的目标对象可以通过多种方式描述,反映颜色、位置等多种属性。然而,现有方法大多依赖于单一文本输入,仅能捕捉视觉领域中丰富信息的一小部分。这种丰富的视觉细节和稀疏的文本线索之间的不匹配可能导致相似对象的错误识别。为了解决这个问题,我们提出了一种新的视觉定位框架,该框架利用从单个文本输入生成的多个隐式表达,这些表达结合了原始描述中缺少的互补视觉细节。具体来说,我们引入了主体分配器和视觉概念注入器模块,将共享主体和不同属性的概念嵌入到隐式表示中,从而捕捉独特的、特定于目标的视觉线索。我们还提出了一种正边距对比学习策略,以对齐所有隐式表达与原始文本,同时保留细微的变化。实验结果表明,我们的方法不仅在多个基准测试中优于最先进的RIS和REC方法,而且在广义指代表达分割(GRES)基准测试中也取得了出色的性能。
🔬 方法详解
问题定义:指代图像分割(RIS)和指代表达理解(REC)任务旨在根据文本描述定位图像中的目标对象。现有方法主要依赖单一文本输入,忽略了图像中丰富的视觉信息,容易导致相似对象的混淆,限制了定位精度。现有方法无法有效利用视觉信息来补充文本描述的不足。
核心思路:论文的核心思路是通过生成多个“隐式表达”来弥补单一文本描述的不足。这些隐式表达从原始文本出发,但融入了不同的视觉概念,从而更全面地描述目标对象。通过将这些隐式表达与原始文本对齐,模型能够学习到更鲁棒的视觉-文本关联。
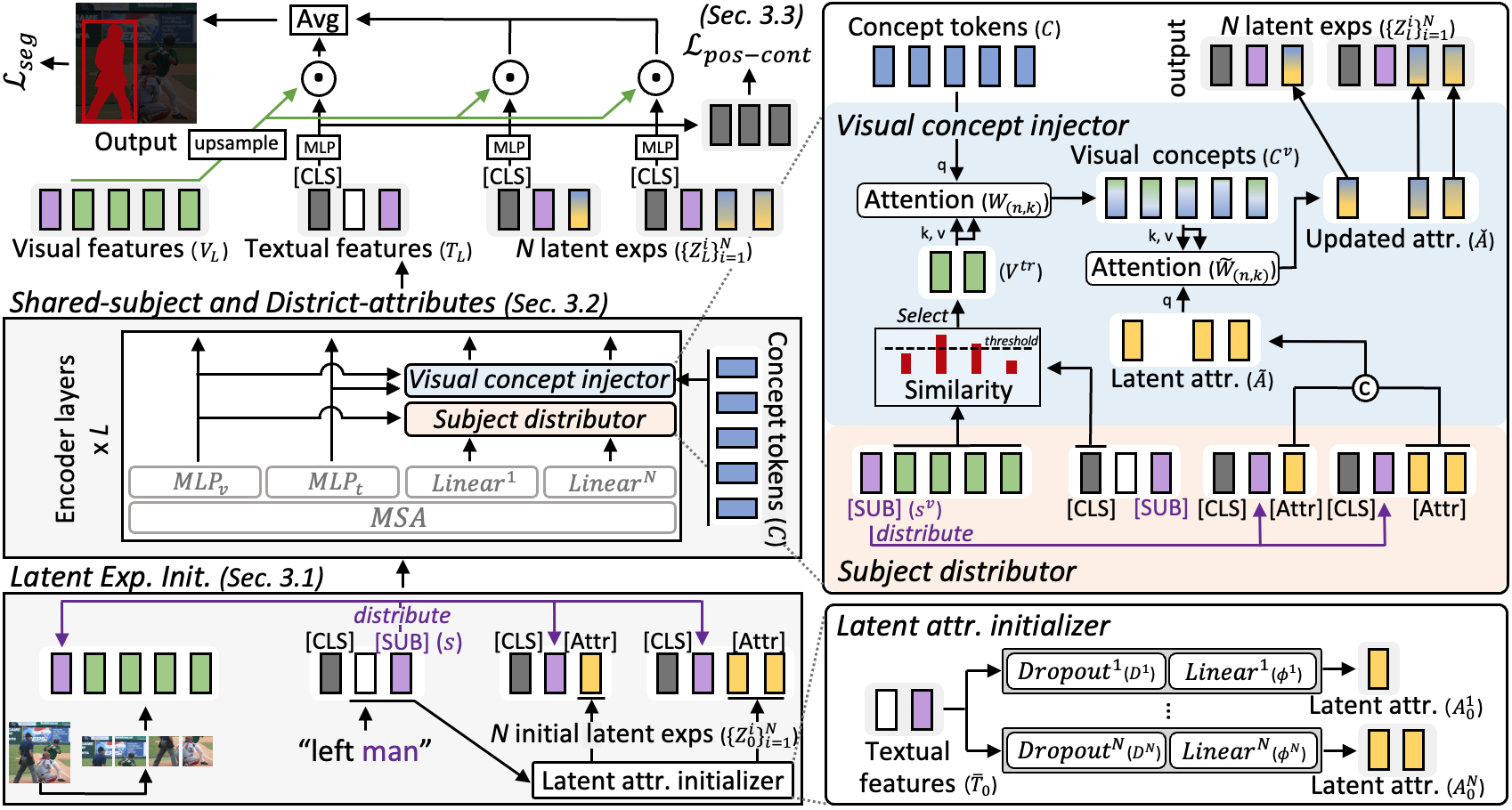
技术框架:整体框架包含以下几个主要模块:1) 文本编码器:将原始文本描述编码为文本特征向量。2) 主体分配器 (Subject Distributor):用于提取共享主体信息,确保生成的隐式表达都围绕同一目标对象。3) 视觉概念注入器 (Visual Concept Injector):将不同的视觉概念(例如颜色、形状、位置等)注入到隐式表达中,生成多个具有不同属性的表达。4) 图像编码器:将输入图像编码为视觉特征图。5) 分割/定位模块:利用文本特征和视觉特征进行分割或定位。6) 对比学习模块:使用正边距对比学习策略,将所有隐式表达与原始文本对齐。
关键创新:关键创新在于隐式表达的生成和利用。通过主体分配器和视觉概念注入器,模型能够从单一文本描述中生成多个包含互补视觉信息的表达。这种方法有效地解决了文本信息稀疏的问题,使模型能够更好地理解图像内容。正边距对比学习策略保证了隐式表达与原始文本的一致性,同时保留了表达之间的差异性。
关键设计:主体分配器和视觉概念注入器的具体实现细节未知,论文可能使用了注意力机制或其他方式来实现。正边距对比学习损失函数的具体形式未知,但其目的是拉近隐式表达和原始文本的距离,同时推开不同隐式表达之间的距离。具体的网络结构和参数设置在论文中应该有详细描述,但摘要中未提及。
🖼️ 关键图片

📊 实验亮点
该方法在RIS、REC和GRES等多个基准测试中取得了显著的性能提升。具体提升幅度未知,但摘要强调了其优于现有最先进方法,并在GRES基准测试中表现出色。这些结果表明该方法能够有效利用视觉信息,提高指代图像分割和定位的准确性。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、图像搜索等领域。例如,在智能监控中,可以根据文本描述快速定位目标人物或物体;在自动驾驶中,可以根据指令识别交通标志或行人;在图像搜索中,可以根据文本描述检索相关图像。
📄 摘要(原文)
Visual grounding tasks, such as referring image segmentation (RIS) and referring expression comprehension (REC), aim to localize a target object based on a given textual description. The target object in an image can be described in multiple ways, reflecting diverse attributes such as color, position, and more. However, most existing methods rely on a single textual input, which captures only a fraction of the rich information available in the visual domain. This mismatch between rich visual details and sparse textual cues can lead to the misidentification of similar objects. To address this, we propose a novel visual grounding framework that leverages multiple latent expressions generated from a single textual input by incorporating complementary visual details absent from the original description. Specifically, we introduce subject distributor and visual concept injector modules to embed both shared-subject and distinct-attributes concepts into the latent representations, thereby capturing unique and target-specific visual cues. We also propose a positive-margin contrastive learning strategy to align all latent expressions with the original text while preserving subtle variations. Experimental results show that our method not only outperforms state-of-the-art RIS and REC approaches on multiple benchmarks but also achieves outstanding performance on the generalized referring expression segmentation (GRES) benchmark.