Multimodal Referring Segmentation: A Survey
作者: Henghui Ding, Song Tang, Shuting He, Chang Liu, Zuxuan Wu, Yu-Gang Jiang
分类: cs.CV
发布日期: 2025-08-01 (更新: 2025-08-05)
备注: Project Page: https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation
🔗 代码/项目: GITHUB
💡 一句话要点
多模态指代分割综述:全面回顾图像、视频和3D场景中的方法与应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态指代分割 视觉语言 图像分割 视频分割 3D场景 深度学习 综述
📋 核心要点
- 现有指代分割方法在处理复杂场景和模糊指代表达式时面临挑战,难以满足实际应用需求。
- 本文提出一个统一的元架构,用于概括和比较不同场景下的指代分割方法,并讨论了广义指代表达式方法。
- 论文对图像、视频和3D场景中的指代分割方法进行了全面的性能比较,并提供了相关资源链接。
📝 摘要(中文)
多模态指代分割旨在根据文本或音频格式的指代表达式,分割视觉场景(如图像、视频和3D场景)中的目标对象。该任务在需要基于用户指令进行精确对象感知的实际应用中起着关键作用。在过去十年中,受益于卷积神经网络、Transformer和大型语言模型的进步,多模态指代分割在多模态社区中受到了广泛关注,这些技术极大地提高了多模态感知能力。本文对多模态指代分割进行了全面的综述。首先介绍该领域的背景,包括问题定义和常用数据集。然后,总结了一个用于指代分割的统一元架构,并回顾了图像、视频和3D场景这三个主要视觉场景中的代表性方法。进一步讨论了广义指代表达式(GREx)方法,以应对现实世界复杂性的挑战,以及相关的任务和实际应用。此外,还提供了在标准基准上的广泛性能比较。我们将持续在https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation上跟踪相关工作。
🔬 方法详解
问题定义:多模态指代分割旨在根据给定的文本或音频描述,精确地分割出视觉场景(图像、视频、3D场景)中对应的目标对象。现有方法在处理复杂场景、长文本描述、以及模棱两可的指代关系时,分割精度和鲁棒性仍有待提高。此外,如何有效地融合多模态信息,并使其适应不同类型的视觉场景,也是一个挑战。
核心思路:本文的核心思路是构建一个统一的元架构,用于描述和比较不同场景下的指代分割方法。通过分析现有方法的共性和差异,总结出通用的模块和流程,从而为未来的研究提供指导。同时,论文关注广义指代表达式(GREx)方法,旨在提升模型在真实复杂场景下的泛化能力。
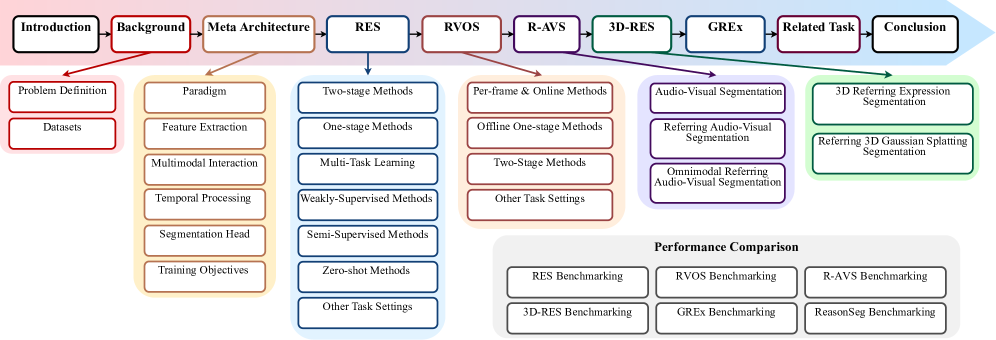
技术框架:论文首先定义了多模态指代分割的基本概念和任务,并介绍了常用的数据集。然后,提出了一个统一的元架构,该架构通常包含以下几个主要模块:1) 特征提取模块,用于提取视觉和语言特征;2) 多模态融合模块,用于融合视觉和语言特征;3) 分割模块,用于生成分割掩码。论文随后分别回顾了图像、视频和3D场景下的代表性方法,并分析了它们在不同模块上的设计。
关键创新:本文的主要创新在于提出了一个统一的元架构,用于描述和比较不同场景下的指代分割方法。该元架构能够帮助研究者更好地理解现有方法的共性和差异,并为未来的研究提供指导。此外,论文还关注广义指代表达式(GREx)方法,旨在提升模型在真实复杂场景下的泛化能力。
关键设计:论文没有提出新的模型或算法,而是一个综述性质的工作,因此没有具体的参数设置、损失函数或网络结构等技术细节。但是,论文对现有方法的关键设计进行了总结和分析,例如,不同的多模态融合策略(如注意力机制、跨模态Transformer等),以及不同的分割模块设计(如全卷积网络、Mask R-CNN等)。
🖼️ 关键图片


📊 实验亮点
该综述论文全面回顾了多模态指代分割领域的研究进展,涵盖图像、视频和3D场景。论文总结了统一的元架构,并对现有方法进行了详细的分类和比较。此外,论文还关注了广义指代表达式(GREx)方法,并提供了在标准基准上的性能比较。论文维护了一个GitHub仓库,持续跟踪相关工作,为研究者提供了宝贵的资源。
🎯 应用场景
多模态指代分割在机器人导航、自动驾驶、智能家居、图像编辑、视频监控等领域具有广泛的应用前景。例如,在机器人导航中,机器人可以根据用户的语音指令(如“把桌子上的红色杯子拿过来”)来定位并抓取目标物体。在自动驾驶中,可以根据文本描述(如“前方那辆白色的轿车”)来识别和跟踪目标车辆。该技术的发展将有助于提升人机交互的自然性和智能化水平。
📄 摘要(原文)
Multimodal referring segmentation aims to segment target objects in visual scenes, such as images, videos, and 3D scenes, based on referring expressions in text or audio format. This task plays a crucial role in practical applications requiring accurate object perception based on user instructions. Over the past decade, it has gained significant attention in the multimodal community, driven by advances in convolutional neural networks, transformers, and large language models, all of which have substantially improved multimodal perception capabilities. This paper provides a comprehensive survey of multimodal referring segmentation. We begin by introducing this field's background, including problem definitions and commonly used datasets. Next, we summarize a unified meta architecture for referring segmentation and review representative methods across three primary visual scenes, including images, videos, and 3D scenes. We further discuss Generalized Referring Expression (GREx) methods to address the challenges of real-world complexity, along with related tasks and practical applications. Extensive performance comparisons on standard benchmarks are also provided. We continually track related works at https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation.