Instruction-Grounded Visual Projectors for Continual Learning of Generative Vision-Language Models
作者: Hyundong Jin, Hyung Jin Chang, Eunwoo Kim
分类: cs.CV, cs.MM
发布日期: 2025-08-01
备注: Accepted to ICCV 2025
💡 一句话要点
提出指令引导的视觉投影器,用于生成式视觉-语言模型的持续学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 持续学习 指令引导 视觉投影器 专家混合模型
📋 核心要点
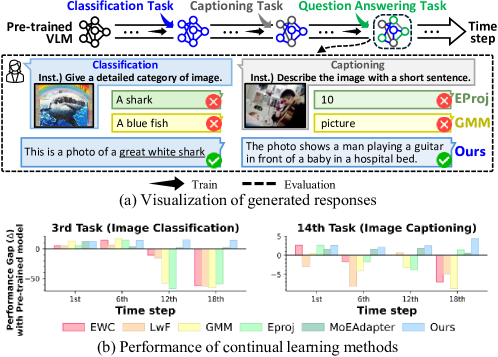
- 现有持续学习方法更新视觉投影器以适应新任务,但可能导致模型过度依赖视觉输入,忽略语言指令。
- 论文提出一种指令引导的视觉投影器混合模型,每个投影器根据指令上下文作为视觉-语言翻译专家。
- 通过专家推荐和剪枝策略,避免不相关指令使用专家,并减轻先前任务专家的干扰,实验表明性能优于现有方法。
📝 摘要(中文)
本文提出了一种新颖的框架,用于解决预训练生成式视觉-语言模型(VLMs)在持续学习中忽略语言指令的问题。现有方法通过更新视觉投影器来适应新任务,但可能导致模型过度依赖视觉输入。为了解决这个问题,我们提出了一个混合视觉投影器,每个投影器都基于给定的指令上下文,作为专门的视觉-语言翻译专家。为了避免不相关的指令上下文使用专家,我们提出了一种专家推荐策略,该策略为与先前学习的任务相似的任务重用专家。此外,我们引入了专家剪枝,以减轻先前任务中累积激活的专家的干扰。在各种视觉-语言任务上的大量实验表明,我们的方法通过生成遵循指令的响应,优于现有的持续学习方法。
🔬 方法详解
问题定义:现有的持续学习方法在更新视觉投影器时,容易使模型偏向视觉输入,忽略语言指令,尤其是在文本指令重复性较高的任务中。这导致模型无法有效利用指令信息,影响生成结果的质量。因此,需要一种方法来更好地将语言指令融入到视觉信息的翻译过程中。
核心思路:论文的核心思路是利用指令信息来引导视觉信息的翻译过程。具体来说,就是为不同的指令上下文训练不同的视觉投影器,每个投影器都作为一个专门的视觉-语言翻译专家,负责处理特定类型的指令。通过这种方式,模型可以更好地理解指令的含义,并生成更符合指令要求的响应。
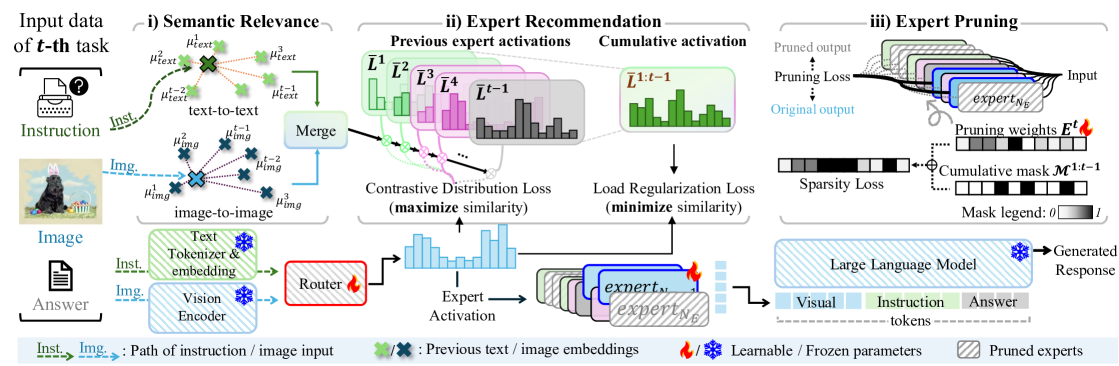
技术框架:整体框架包含一个预训练的视觉编码器、一个预训练的语言模型,以及一个混合视觉投影器。混合视觉投影器由多个独立的视觉投影器组成,每个投影器对应一种特定的指令上下文。此外,框架还包含一个专家推荐模块和一个专家剪枝模块。专家推荐模块负责为新的任务选择合适的视觉投影器,而专家剪枝模块则负责移除不再需要的视觉投影器。
关键创新:论文的关键创新在于提出了指令引导的视觉投影器混合模型。与以往的单一视觉投影器方法相比,该方法可以更好地利用指令信息,提高生成结果的质量。此外,专家推荐和剪枝策略可以有效地避免不相关指令的干扰,并减少模型的参数量。
关键设计:专家推荐模块使用余弦相似度来衡量新任务的指令上下文与已学习任务的指令上下文之间的相似度,并选择相似度最高的视觉投影器。专家剪枝模块则根据视觉投影器的激活频率来判断其是否仍然有用,并移除激活频率低于阈值的视觉投影器。损失函数包括生成损失和正则化损失,其中生成损失用于训练视觉投影器,正则化损失用于防止过拟合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个视觉-语言任务上都取得了显著的性能提升。例如,在图像描述生成任务中,该方法生成的描述更加准确和符合指令要求。与现有的持续学习方法相比,该方法在生成质量和指令遵循度方面都有明显的优势。具体性能提升数据在论文中有详细展示。
🎯 应用场景
该研究成果可应用于各种需要视觉-语言交互的场景,例如图像描述生成、视觉问答、图像编辑等。通过持续学习,模型可以不断适应新的任务和指令,提高其在实际应用中的泛化能力和实用性。该方法在智能客服、人机交互、教育娱乐等领域具有广阔的应用前景。
📄 摘要(原文)
Continual learning enables pre-trained generative vision-language models (VLMs) to incorporate knowledge from new tasks without retraining data from previous ones. Recent methods update a visual projector to translate visual information for new tasks, connecting pre-trained vision encoders with large language models. However, such adjustments may cause the models to prioritize visual inputs over language instructions, particularly learning tasks with repetitive types of textual instructions. To address the neglect of language instructions, we propose a novel framework that grounds the translation of visual information on instructions for language models. We introduce a mixture of visual projectors, each serving as a specialized visual-to-language translation expert based on the given instruction context to adapt to new tasks. To avoid using experts for irrelevant instruction contexts, we propose an expert recommendation strategy that reuses experts for tasks similar to those previously learned. Additionally, we introduce expert pruning to alleviate interference from the use of experts that cumulatively activated in previous tasks. Extensive experiments on diverse vision-language tasks demonstrate that our method outperforms existing continual learning approaches by generating instruction-following responses.