AGA: An adaptive group alignment framework for structured medical cross-modal representation learning
作者: Wei Li, Xun Gong, Jiao Li, Xiaobin Sun
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-31
💡 一句话要点
提出AGA框架,通过自适应分组对齐实现医学跨模态表征学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 医学图像 跨模态学习 表征学习 分组对齐 视觉-语言 自适应阈值 实例感知学习
📋 核心要点
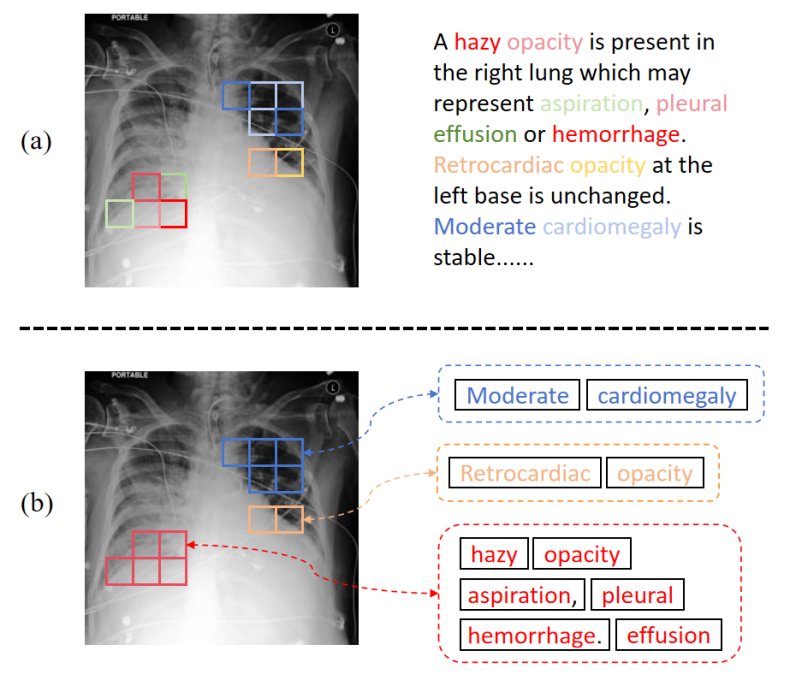
- 现有医学视觉-语言预训练方法忽略了临床报告的内在结构,限制了表征学习的性能。
- AGA框架通过双向分组机制和自适应阈值门,能够捕获图像和报告之间的细粒度结构化语义。
- 实验结果表明,AGA在图像-文本检索和分类任务上表现出色,尤其是在小规模数据集上。
📝 摘要(中文)
本文提出了一种自适应分组对齐(AGA)框架,用于从配对的医学图像和报告中学习医学视觉表征。现有医学领域的视觉-语言预训练方法通常将临床报告简化为单个实体或碎片化的token,忽略了其内在结构。此外,对比学习框架通常依赖于大量的难负样本,这对于小规模医学数据集是不切实际的。为了解决这些挑战,AGA引入了一种基于稀疏相似度矩阵的双向分组机制。对于每个图像-报告对,计算文本token和图像patch之间的细粒度相似度。每个token选择其最佳匹配的patch形成视觉组,每个patch选择其最相关的token形成语言组。为了实现自适应分组,设计了语言分组阈值门和视觉分组阈值门,动态学习分组阈值。组表征计算为基于相似度分数的加权平均。为了将每个token与其组表征对齐,引入了实例感知组对齐损失,该损失在每个图像-文本对内操作,无需外部负样本。最后,应用双向跨模态分组对齐模块来增强视觉和语言组表征之间的细粒度对齐。在公共和私有数据集上的大量实验表明,该方法在微调和零样本设置下,在图像-文本检索和分类任务上都取得了强大的性能。
🔬 方法详解
问题定义:现有医学图像-文本跨模态学习方法,通常将医学报告视为扁平的token序列,忽略了报告中蕴含的结构化信息,例如不同token之间的关联性以及与图像区域的对应关系。此外,依赖大量负样本的对比学习方法在医学领域由于数据稀缺性而难以应用。
核心思路:AGA的核心在于通过自适应分组的方式,显式地建模图像patch和文本token之间的关系,从而捕捉医学报告的结构化语义。通过构建视觉组和语言组,将相关的图像区域和文本token聚合在一起,并学习组级别的表征,从而实现更细粒度的跨模态对齐。
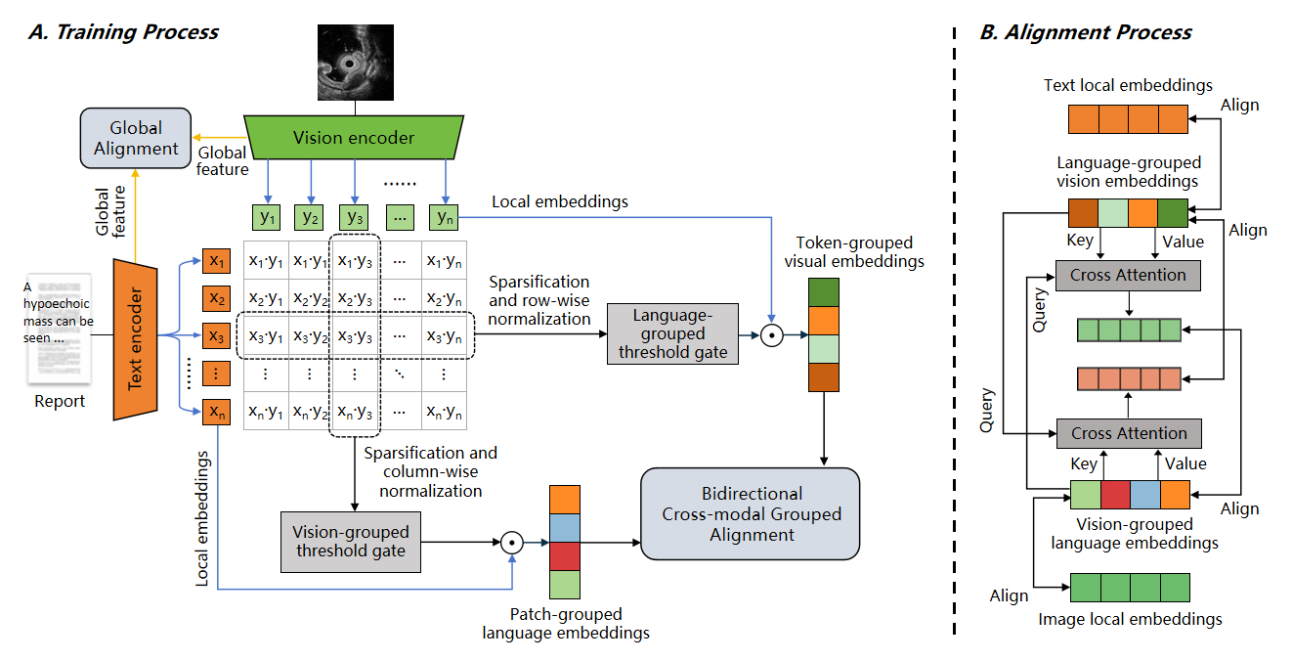
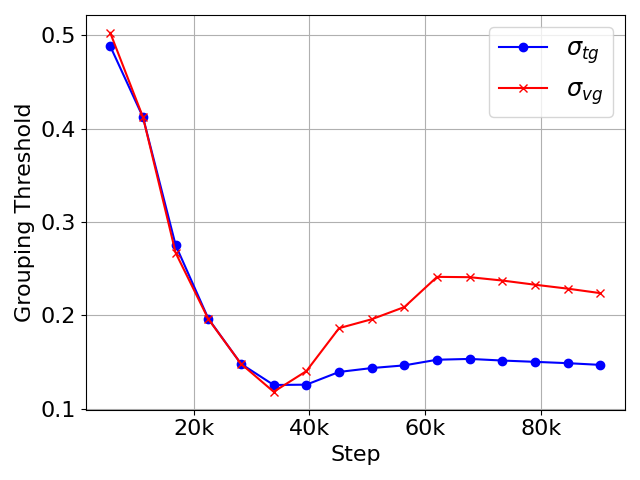
技术框架:AGA框架主要包含以下几个模块:1) 相似度计算模块:计算图像patch和文本token之间的细粒度相似度。2) 双向分组模块:基于相似度矩阵,每个token选择top-k个图像patch形成视觉组,每个patch选择top-k个文本token形成语言组。3) 自适应阈值门:动态学习分组阈值,控制哪些token/patch可以被纳入组中。4) 组表征计算模块:基于相似度分数,计算视觉组和语言组的加权平均表征。5) 实例感知组对齐损失:在每个图像-文本对内,将每个token与其对应的组表征对齐。6) 双向跨模态分组对齐模块:增强视觉和语言组表征之间的细粒度对齐。
关键创新:AGA的关键创新在于:1) 提出了双向分组机制,显式地建模了图像patch和文本token之间的关系。2) 设计了自适应阈值门,能够动态地学习分组阈值,从而更好地适应不同的图像-文本对。3) 提出了实例感知组对齐损失,避免了对大量负样本的依赖。
关键设计:1) 相似度计算采用余弦相似度。2) 自适应阈值门采用sigmoid函数进行归一化。3) 组表征计算采用加权平均,权重为相似度分数。4) 实例感知组对齐损失采用InfoNCE损失的变体,只考虑正样本对。
🖼️ 关键图片
📊 实验亮点
在公共和私有数据集上的实验结果表明,AGA在图像-文本检索和分类任务上都取得了显著的性能提升。例如,在某个数据集上,AGA在图像检索任务上的Recall@1指标比基线方法提高了5%以上,证明了其有效性。
🎯 应用场景
AGA框架可应用于医学图像报告生成、医学图像检索、辅助诊断等领域。通过学习图像和报告之间的细粒度对应关系,可以提升报告生成的准确性和流畅性,提高图像检索的效率和准确性,并为医生提供更全面的诊断信息,具有重要的临床应用价值。
📄 摘要(原文)
Learning medical visual representations from paired images and reports is a promising direction in representation learning. However, current vision-language pretraining methods in the medical domain often simplify clinical reports into single entities or fragmented tokens, ignoring their inherent structure. In addition, contrastive learning frameworks typically depend on large quantities of hard negative samples, which is impractical for small-scale medical datasets. To tackle these challenges, we propose Adaptive Grouped Alignment (AGA), a new framework that captures structured semantics from paired medical images and reports. AGA introduces a bidirectional grouping mechanism based on a sparse similarity matrix. For each image-report pair, we compute fine-grained similarities between text tokens and image patches. Each token selects its top-matching patches to form a visual group, and each patch selects its most related tokens to form a language group. To enable adaptive grouping, we design two threshold gating modules, called Language Grouped Threshold Gate and Vision Grouped Threshold Gate, which learn grouping thresholds dynamically. Group representations are computed as weighted averages based on similarity scores. To align each token with its group representation, we introduce an Instance Aware Group Alignment loss that operates within each image-text pair, removing the need for external negatives. Finally, a Bidirectional Cross-modal Grouped Alignment module is applied to enhance fine-grained alignment between visual and linguistic group representations. Extensive experiments on public and private datasets show that our method achieves strong performance on image-text retrieval and classification tasks under both fine-tuning and zero-shot settings.