VMatcher: State-Space Semi-Dense Local Feature Matching
作者: Ali Youssef
分类: cs.CV
发布日期: 2025-07-31
🔗 代码/项目: GITHUB
💡 一句话要点
VMatcher:结合Mamba和Transformer的状态空间半稠密局部特征匹配
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 特征匹配 Mamba Transformer 状态空间模型 半稠密 图像处理 计算机视觉 实时应用
📋 核心要点
- 现有特征匹配方法依赖Transformer注意力机制,计算复杂度高,限制了实时应用。
- VMatcher融合Mamba的线性复杂度和Transformer的优势,实现高效且鲁棒的特征匹配。
- 实验表明,VMatcher在效率上设立了新基准,并保证了实时应用所需的快速推理能力。
📝 摘要(中文)
本文介绍了一种名为VMatcher的混合Mamba-Transformer网络,用于图像对之间的半稠密特征匹配。基于学习的特征匹配方法,无论是基于检测器还是无检测器的,都取得了最先进的性能,但严重依赖于Transformer的注意力机制。虽然Transformer的注意力机制非常有效,但由于其二次复杂度,导致计算成本很高。相比之下,Mamba引入了一种选择性状态空间模型(SSM),该模型以线性复杂度实现了可比或更优越的性能,从而显著提高了效率。VMatcher利用了一种混合方法,将Mamba的高效长序列处理与Transformer的注意力机制相结合。论文提出了多种VMatcher配置,包括分层架构,证明了它们在高效地设置新基准方面的有效性,同时确保了鲁棒性和实时应用(快速推理至关重要)的实用性。源代码可在https://github.com/ayoussf/VMatcher 获取。
🔬 方法详解
问题定义:论文旨在解决图像对之间半稠密特征匹配问题。现有基于学习的特征匹配方法,特别是依赖Transformer的方法,虽然精度高,但计算复杂度是二次方的,这限制了它们在需要快速推理的实时应用中的应用。因此,如何在保证匹配精度的前提下,降低计算复杂度,是本论文要解决的核心问题。
核心思路:VMatcher的核心思路是结合Mamba和Transformer的优势。Mamba使用选择性状态空间模型(SSM),具有线性复杂度,能够高效处理长序列。Transformer的注意力机制擅长捕捉图像特征之间的关系。VMatcher通过混合这两种机制,在保证匹配精度的同时,显著降低计算复杂度。
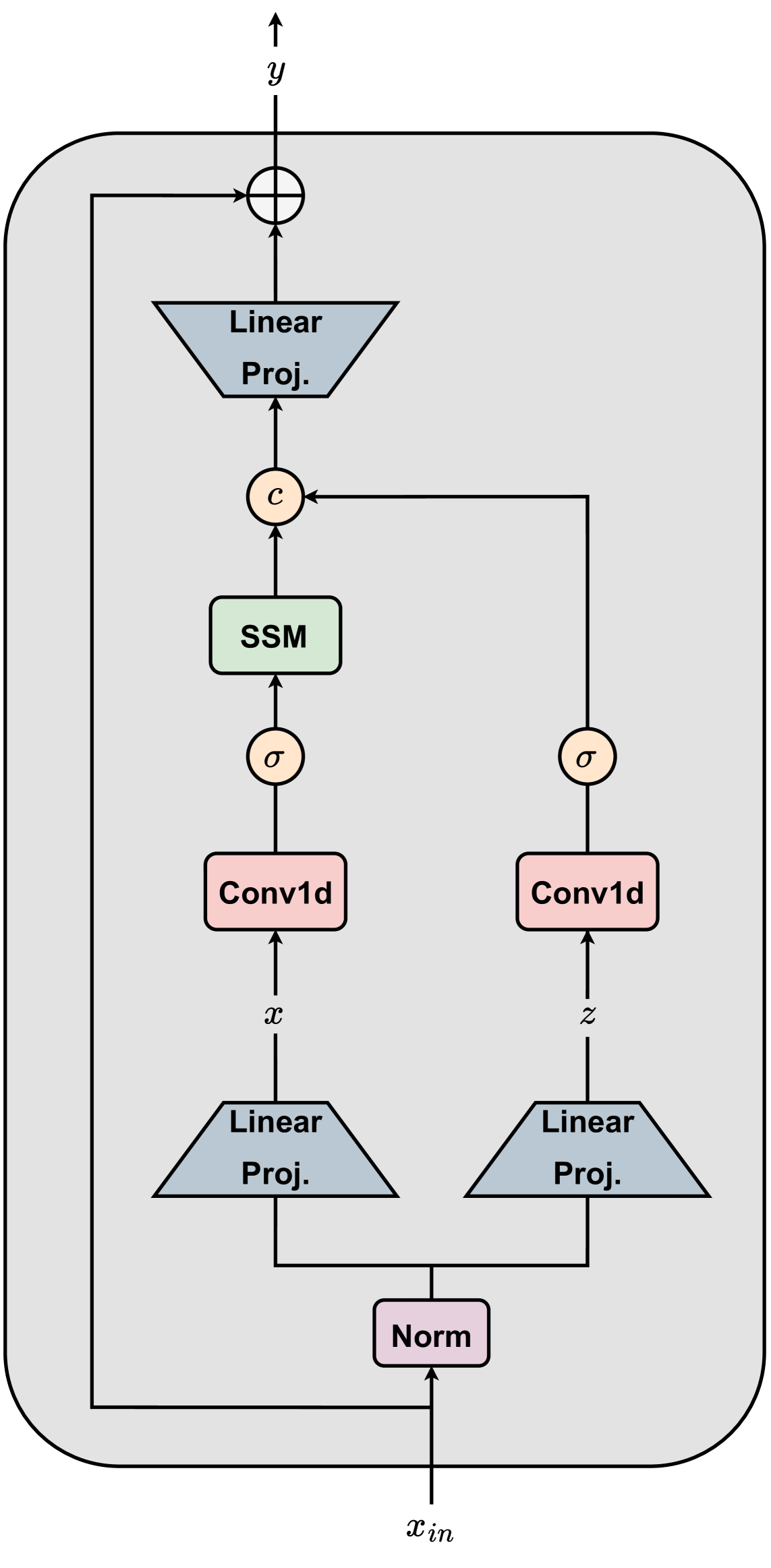
技术框架:VMatcher的整体架构是一个混合网络,包含Mamba模块和Transformer模块。具体流程可能包括:1. 输入图像对;2. 使用卷积神经网络提取图像特征;3. 使用Mamba模块处理特征序列,提取长程依赖关系;4. 使用Transformer模块进行特征融合和匹配;5. 输出匹配结果。论文中提到了多种VMatcher配置,包括分层架构,具体实现细节未知。
关键创新:VMatcher的关键创新在于混合使用了Mamba和Transformer。Mamba的线性复杂度使得VMatcher能够高效处理长序列,而Transformer的注意力机制则保证了匹配精度。这种混合架构在特征匹配领域是一个新的尝试,旨在克服传统Transformer方法的计算瓶颈。
关键设计:论文中没有详细说明关键参数设置、损失函数和网络结构等技术细节。但是,可以推测,损失函数可能包括匹配损失和几何一致性损失。网络结构可能采用分层设计,逐步提取和融合图像特征。Mamba和Transformer模块的具体配置(例如,层数、隐藏层大小等)未知。
🖼️ 关键图片


📊 实验亮点
VMatcher通过结合Mamba和Transformer,在半稠密特征匹配任务上取得了显著的效率提升。论文声称VMatcher在设置新的基准方面表现出色,但具体的性能数据、对比基线和提升幅度未知。论文强调了VMatcher在保证鲁棒性的同时,能够满足实时应用对快速推理的需求。
🎯 应用场景
VMatcher具有广泛的应用前景,包括但不限于:增强现实(AR)、虚拟现实(VR)、机器人导航、三维重建、图像拼接、视觉定位等。其高效的特征匹配能力可以提升这些应用在实时性、准确性和鲁棒性方面的性能。未来,VMatcher有望成为移动设备和嵌入式系统上视觉应用的关键技术。
📄 摘要(原文)
This paper introduces VMatcher, a hybrid Mamba-Transformer network for semi-dense feature matching between image pairs. Learning-based feature matching methods, whether detector-based or detector-free, achieve state-of-the-art performance but depend heavily on the Transformer's attention mechanism, which, while effective, incurs high computational costs due to its quadratic complexity. In contrast, Mamba introduces a Selective State-Space Model (SSM) that achieves comparable or superior performance with linear complexity, offering significant efficiency gains. VMatcher leverages a hybrid approach, integrating Mamba's highly efficient long-sequence processing with the Transformer's attention mechanism. Multiple VMatcher configurations are proposed, including hierarchical architectures, demonstrating their effectiveness in setting new benchmarks efficiently while ensuring robustness and practicality for real-time applications where rapid inference is crucial. Source Code is available at: https://github.com/ayoussf/VMatcher