FastDriveVLA: Efficient End-to-End Driving via Plug-and-Play Reconstruction-based Token Pruning
作者: Jiajun Cao, Qizhe Zhang, Peidong Jia, Xuhui Zhao, Bo Lan, Xiaoan Zhang, Zhuo Li, Xiaobao Wei, Sixiang Chen, Liyun Li, Xianming Liu, Ming Lu, Yang Wang, Shanghang Zhang
分类: cs.CV, cs.AI
发布日期: 2025-07-31 (更新: 2025-11-14)
备注: Accepted by AAAI 2026
💡 一句话要点
FastDriveVLA:提出基于重建的即插即用式Token剪枝,高效端到端自动驾驶。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉语言动作模型 Token剪枝 前景重建 计算效率
📋 核心要点
- VLA模型计算成本高昂,现有token剪枝方法在自动驾驶场景中效果不佳。
- FastDriveVLA通过MAE风格像素重建,优先保留包含前景信息的视觉tokens。
- 在nuScenes数据集上,FastDriveVLA在不同剪枝比例下均取得SOTA结果。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在复杂场景理解和动作推理方面展现出巨大潜力,并越来越多地应用于端到端自动驾驶系统。然而,VLA模型中冗长的视觉tokens显著增加了计算成本。现有的视觉-语言模型(VLM)中的视觉token剪枝方法依赖于视觉token相似性或视觉-文本注意力,但在自动驾驶场景中表现不佳。考虑到人类驾驶员专注于相关前景区域,我们认为保留包含前景信息的视觉tokens对于有效的决策至关重要。受此启发,我们提出FastDriveVLA,一种专为自动驾驶设计的新型基于重建的视觉token剪枝框架。FastDriveVLA包含一个名为ReconPruner的即插即用视觉token剪枝器,通过MAE风格的像素重建来优先考虑前景信息。设计了一种新的对抗性前景-背景重建策略来训练VLA模型视觉编码器的ReconPruner。训练完成后,ReconPruner可以无缝应用于具有相同视觉编码器的不同VLA模型,而无需重新训练。为了训练ReconPruner,我们还引入了一个名为nuScenes-FG的大规模数据集,包含241K图像-掩码对,并标注了前景区域。我们的方法在不同剪枝比例下,在nuScenes开放循环规划基准上取得了最先进的结果。
🔬 方法详解
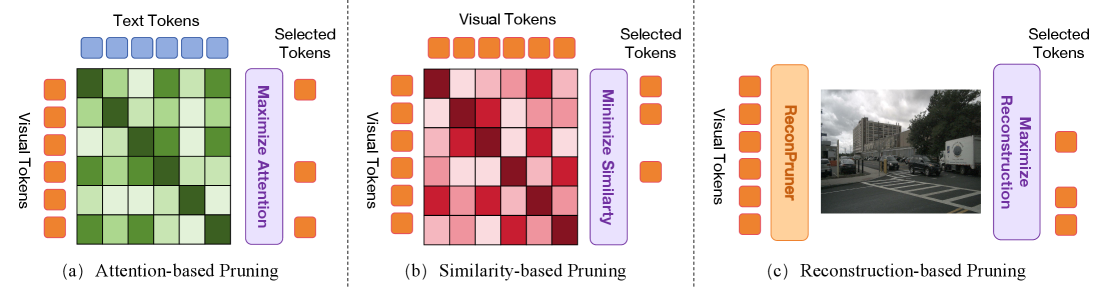
问题定义:论文旨在解决VLA模型在端到端自动驾驶应用中计算成本过高的问题。现有视觉token剪枝方法,如基于token相似性或视觉-文本注意力的方法,无法有效识别并保留自动驾驶场景中的关键信息,导致性能下降。这些方法忽略了驾驶场景中前景区域的重要性,而人类驾驶员通常专注于这些区域。
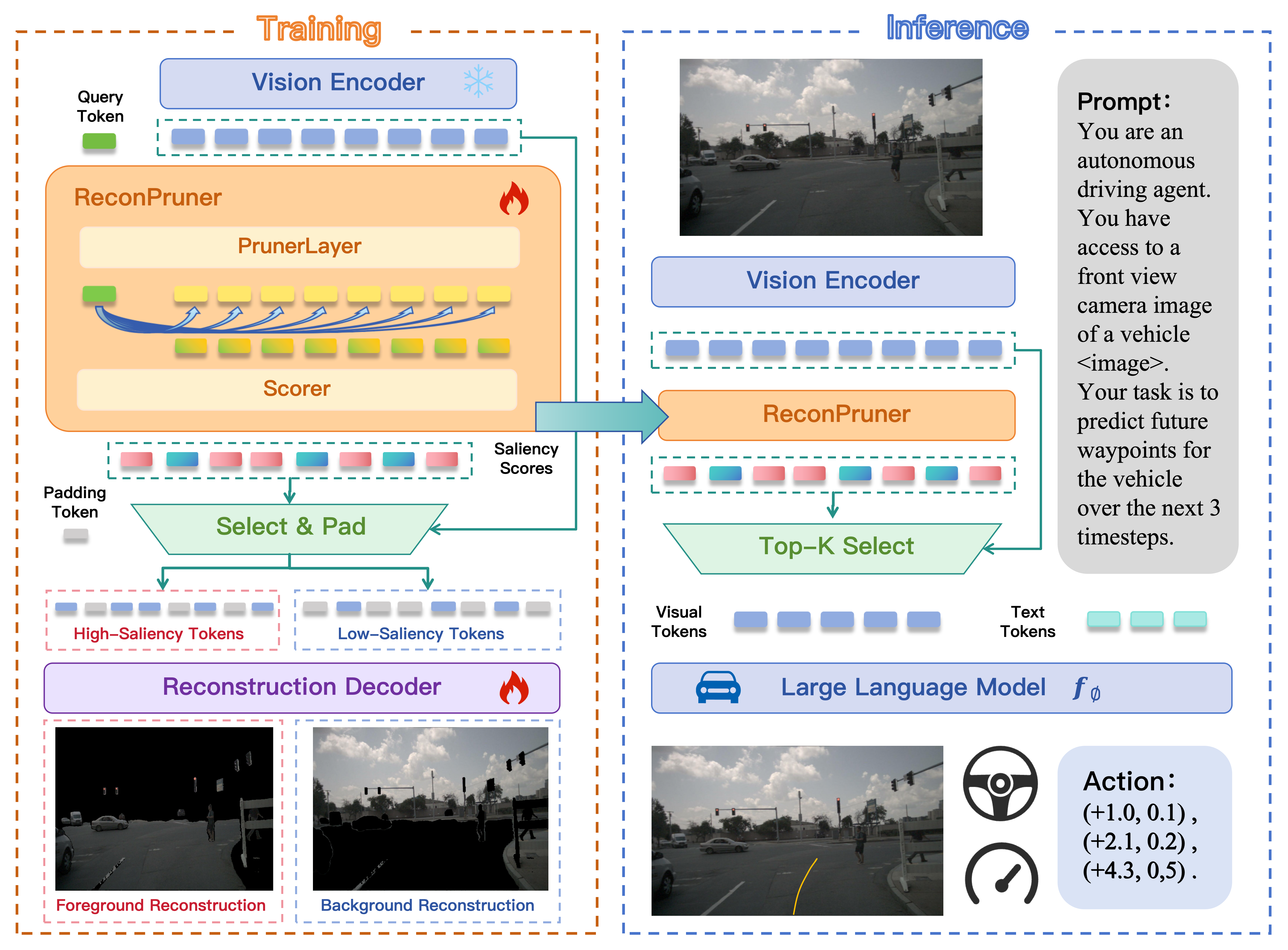
核心思路:论文的核心思路是,通过重建图像像素来判断视觉token的重要性,并优先保留包含前景信息的token。这种方法模拟了人类驾驶员关注前景区域的机制,从而提高剪枝后的模型性能。通过对抗性训练,ReconPruner能够更好地区分前景和背景,从而更准确地进行token选择。
技术框架:FastDriveVLA框架包含一个即插即用的视觉token剪枝器ReconPruner。该剪枝器在VLA模型的视觉编码器之后插入。ReconPruner通过MAE风格的像素重建来评估每个token的重要性。框架使用nuScenes-FG数据集进行训练,该数据集包含带有前景区域标注的图像。训练完成后,ReconPruner可以应用于具有相同视觉编码器的不同VLA模型,无需重新训练。
关键创新:论文的关键创新在于ReconPruner,它是一种基于重建的视觉token剪枝器,专为自动驾驶场景设计。与现有方法不同,ReconPruner通过像素重建来优先考虑前景信息,从而更有效地保留关键信息。此外,对抗性前景-背景重建策略进一步提高了ReconPruner的性能。
关键设计:ReconPruner使用MAE风格的像素重建作为评估token重要性的指标。对抗性前景-背景重建策略包括两个损失函数:一个用于重建前景区域,另一个用于重建背景区域。这两个损失函数以对抗的方式进行优化,从而使ReconPruner能够更好地区分前景和背景。nuScenes-FG数据集包含241K图像-掩码对,用于训练ReconPruner。
🖼️ 关键图片

📊 实验亮点
FastDriveVLA在nuScenes开放循环规划基准上取得了最先进的结果。实验表明,在不同的剪枝比例下,FastDriveVLA均优于现有的视觉token剪枝方法。例如,在保持相同性能的情况下,FastDriveVLA可以显著减少计算量,从而提高自动驾驶系统的效率。
🎯 应用场景
该研究成果可应用于各种自动驾驶系统,尤其是在计算资源受限的场景中,例如嵌入式自动驾驶平台。通过减少计算量,FastDriveVLA可以提高自动驾驶系统的实时性和效率,并降低硬件成本。此外,该方法还可以推广到其他需要关注特定区域的视觉任务中,例如目标检测和图像分割。
📄 摘要(原文)
Vision-Language-Action (VLA) models have demonstrated significant potential in complex scene understanding and action reasoning, leading to their increasing adoption in end-to-end autonomous driving systems. However, the long visual tokens of VLA models greatly increase computational costs. Current visual token pruning methods in Vision-Language Models (VLM) rely on either visual token similarity or visual-text attention, but both have shown poor performance in autonomous driving scenarios. Given that human drivers concentrate on relevant foreground areas while driving, we assert that retaining visual tokens containing this foreground information is essential for effective decision-making. Inspired by this, we propose FastDriveVLA, a novel reconstruction-based vision token pruning framework designed specifically for autonomous driving. FastDriveVLA includes a plug-and-play visual token pruner called ReconPruner, which prioritizes foreground information through MAE-style pixel reconstruction. A novel adversarial foreground-background reconstruction strategy is designed to train ReconPruner for the visual encoder of VLA models. Once trained, ReconPruner can be seamlessly applied to different VLA models with the same visual encoder without retraining. To train ReconPruner, we also introduce a large-scale dataset called nuScenes-FG, consisting of 241K image-mask pairs with annotated foreground regions. Our approach achieves state-of-the-art results on the nuScenes open-loop planning benchmark across different pruning ratios.