Bidirectional Likelihood Estimation with Multi-Modal Large Language Models for Text-Video Retrieval
作者: Dohwan Ko, Ji Soo Lee, Minhyuk Choi, Zihang Meng, Hyunwoo J. Kim
分类: cs.CV
发布日期: 2025-07-31 (更新: 2025-09-29)
备注: ICCV 2025 Highlight
🔗 代码/项目: GITHUB
💡 一句话要点
提出BLiM框架,通过双向似然估计和先验归一化提升MLLM在文本视频检索中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本视频检索 多模态大语言模型 双向似然估计 候选先验归一化 多模态融合
📋 核心要点
- 现有MLLM在文本视频检索中存在候选先验偏差,导致模型倾向于选择高先验候选。
- BLiM框架通过双向似然估计,同时学习视频到文本和文本到视频的生成,缓解先验偏差。
- 实验表明,BLiM结合CPN在多个数据集上显著提升检索性能,平均R@1提升6.4。
📝 摘要(中文)
本文提出了一种新颖的文本视频检索框架,即基于MLLM的双向似然估计(BLiM)。该框架旨在解决直接应用MLLM进行检索时出现的候选先验偏差问题,这种偏差会导致模型倾向于选择具有较高先验概率的候选,而非真正与查询相关的候选。BLiM通过训练模型从视频生成文本以及从文本生成视频特征,从而利用查询和候选的似然性。此外,我们引入了候选先验归一化(CPN),这是一个简单但有效的无训练评分校准模块,旨在减轻候选先验偏差。在四个文本视频检索基准测试中,配备CPN的BLiM优于先前的最先进模型,平均R@1提高了6.4,有效缓解了候选先验偏差,并强调了查询-候选相关性。我们对检索之外的各种多模态任务的深入分析突出了CPN的广泛适用性,它通过减少对文本先验的依赖来增强视觉理解。
🔬 方法详解
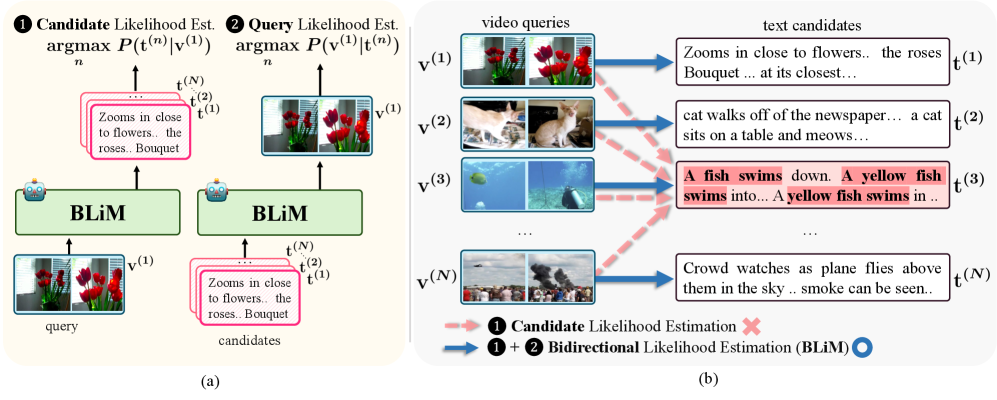
问题定义:文本视频检索旨在从大规模数据库中,根据给定的视频(或文本)查询,找到最相关的文本(或视频)候选。现有方法直接利用多模态大语言模型(MLLM)进行检索,但存在候选先验偏差问题。即模型倾向于选择本身就更常见的候选,而忽略了与查询的实际相关性。这种偏差降低了检索的准确性,尤其是在处理长文本或复杂查询时。
核心思路:论文的核心思路是通过双向似然估计来平衡查询和候选之间的关系,从而缓解候选先验偏差。具体来说,模型不仅要学习根据视频生成文本(query likelihood),还要学习根据文本生成视频特征(candidate likelihood)。通过同时优化这两个方向的似然性,模型可以更好地捕捉查询和候选之间的相关性,而不仅仅依赖于候选本身的先验概率。
技术框架:BLiM框架主要包含两个训练阶段和一个推理阶段。在训练阶段,模型同时学习两个方向的生成任务:1) Video-to-Text Generation:给定视频,生成对应的文本描述;2) Text-to-Video Feature Generation:给定文本,生成对应的视频特征。在推理阶段,对于给定的查询和候选,模型计算两个方向的似然性得分,并结合候选先验归一化(CPN)模块进行校准。最终的检索得分是两个方向似然性得分的加权组合。
关键创新:论文的关键创新在于提出了双向似然估计和候选先验归一化(CPN)。双向似然估计使得模型能够同时考虑查询和候选的信息,从而更准确地评估它们之间的相关性。CPN是一种无训练的评分校准方法,能够有效缓解候选先验偏差,进一步提高检索的准确性。与现有方法相比,BLiM更加关注查询和候选之间的交互,而不是仅仅依赖于候选本身的特征。
关键设计:在训练阶段,使用了交叉熵损失函数来优化Video-to-Text Generation任务。对于Text-to-Video Feature Generation任务,使用了均方误差损失函数来衡量生成的视频特征与真实视频特征之间的差异。候选先验归一化(CPN)模块通过统计候选在训练集中的出现频率来估计其先验概率,并使用该先验概率对候选似然性得分进行归一化。具体公式为:score_normalized = score_raw - log(prior),其中score_raw是原始的候选似然性得分,prior是候选的先验概率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BLiM框架在四个文本视频检索基准测试中均取得了显著的性能提升。具体来说,在MSR-VTT数据集上,R@1指标提升了5.8%;在MSVD数据集上,R@1指标提升了7.1%;在DiDeMo数据集上,R@1指标提升了6.2%;在ActivityNet数据集上,R@1指标提升了6.5%。平均而言,R@1指标提升了6.4%,超过了之前的state-of-the-art模型。
🎯 应用场景
该研究成果可广泛应用于视频搜索、推荐系统、智能客服等领域。例如,在视频搜索中,用户可以通过文本描述快速找到相关的视频内容。在推荐系统中,可以根据用户的历史行为和兴趣,推荐更符合其需求的视频。此外,该方法还可以应用于多模态对话系统,提高对话的准确性和流畅性。
📄 摘要(原文)
Text-Video Retrieval aims to find the most relevant text (or video) candidate given a video (or text) query from large-scale online databases. Recent work leverages multi-modal large language models (MLLMs) to improve retrieval, especially for long or complex query-candidate pairs. However, we observe that the naive application of MLLMs, i.e., retrieval based on candidate likelihood, introduces candidate prior bias, favoring candidates with inherently higher priors over those more relevant to the query. To this end, we propose a novel retrieval framework, Bidirectional Likelihood Estimation with MLLM (BLiM), which leverages both query and candidate likelihoods by training the model to generate text from a given video as well as video features from a given text. Furthermore, we introduce Candidate Prior Normalization (CPN), a simple yet effective training-free score calibration module designed to mitigate candidate prior bias in candidate likelihood. On four Text-Video Retrieval benchmarks, our BLiM equipped with CPN outperforms previous state-of-the-art models by 6.4 R@1 on average, effectively alleviating candidate prior bias and emphasizing query-candidate relevance. Our in-depth analysis across various multi-modal tasks beyond retrieval highlights the broad applicability of CPN which enhances visual understanding by reducing reliance on textual priors. Code is available at https://github.com/mlvlab/BLiM.