iLRM: An Iterative Large 3D Reconstruction Model
作者: Gyeongjin Kang, Seungtae Nam, Seungkwon Yang, Xiangyu Sun, Sameh Khamis, Abdelrahman Mohamed, Eunbyung Park
分类: cs.CV
发布日期: 2025-07-31 (更新: 2025-10-17)
备注: Project page: https://gynjn.github.io/iLRM/
💡 一句话要点
提出迭代式大型3D重建模型iLRM,解决现有方法在多视角高分辨率场景下的可扩展性问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 高斯溅射 迭代优化 多视角几何 Transformer 可扩展性 前馈网络
📋 核心要点
- 现有基于Transformer的3D重建方法依赖于多视角图像token的全局注意力机制,计算成本随视角数量和图像分辨率的增加而急剧上升,可扩展性差。
- iLRM通过迭代细化3D高斯表示,解耦场景表示与输入视图,并采用两阶段注意力机制,有效降低了计算复杂度,提升了重建效率。
- 实验结果表明,iLRM在RE10K和DL3DV等数据集上,重建质量和速度均优于现有方法,验证了其有效性。
📝 摘要(中文)
本文提出了一种迭代式大型3D重建模型(iLRM),旨在实现可扩展且高效的前馈3D重建。该模型通过迭代细化机制生成3D高斯表示,并遵循三个核心原则:(1)将场景表示与输入视图图像解耦,以实现紧凑的3D表示;(2)将完全注意力多视图交互分解为两阶段注意力机制,以降低计算成本;(3)在每一层注入高分辨率信息,以实现高保真重建。在RE10K和DL3DV等广泛使用的数据集上的实验结果表明,iLRM在重建质量和速度方面均优于现有方法。
🔬 方法详解
问题定义:现有基于Transformer的前馈3D重建方法,特别是直接生成3D高斯splatting的方法,在处理多视角、高分辨率图像时,由于全局注意力机制的计算复杂度过高,导致可扩展性差,计算成本难以承受。这限制了它们在大型场景重建中的应用。
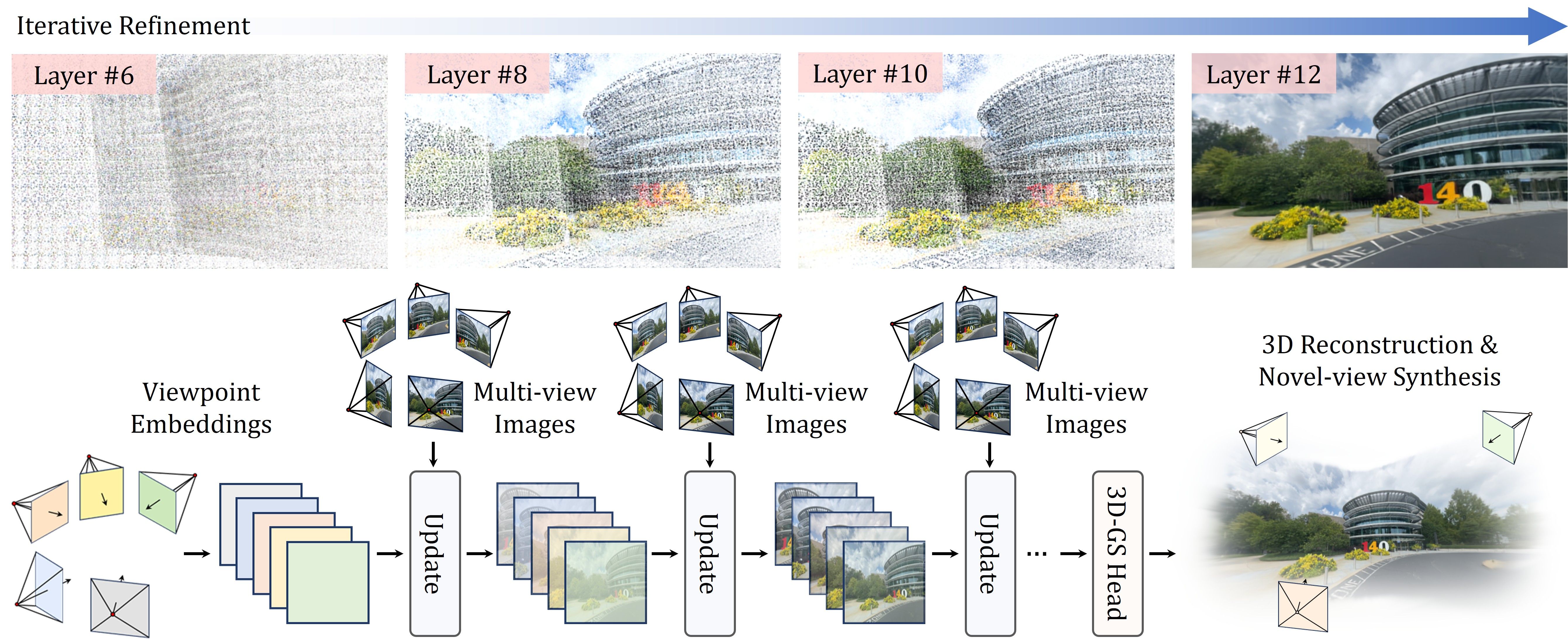
核心思路:iLRM的核心思路是通过迭代细化3D高斯表示来逐步构建场景。它将场景表示与输入视图解耦,从而可以使用更紧凑的3D表示。此外,它将全局注意力机制分解为两阶段注意力,显著降低了计算复杂度。通过在每一层注入高分辨率信息,保证了重建的细节和质量。
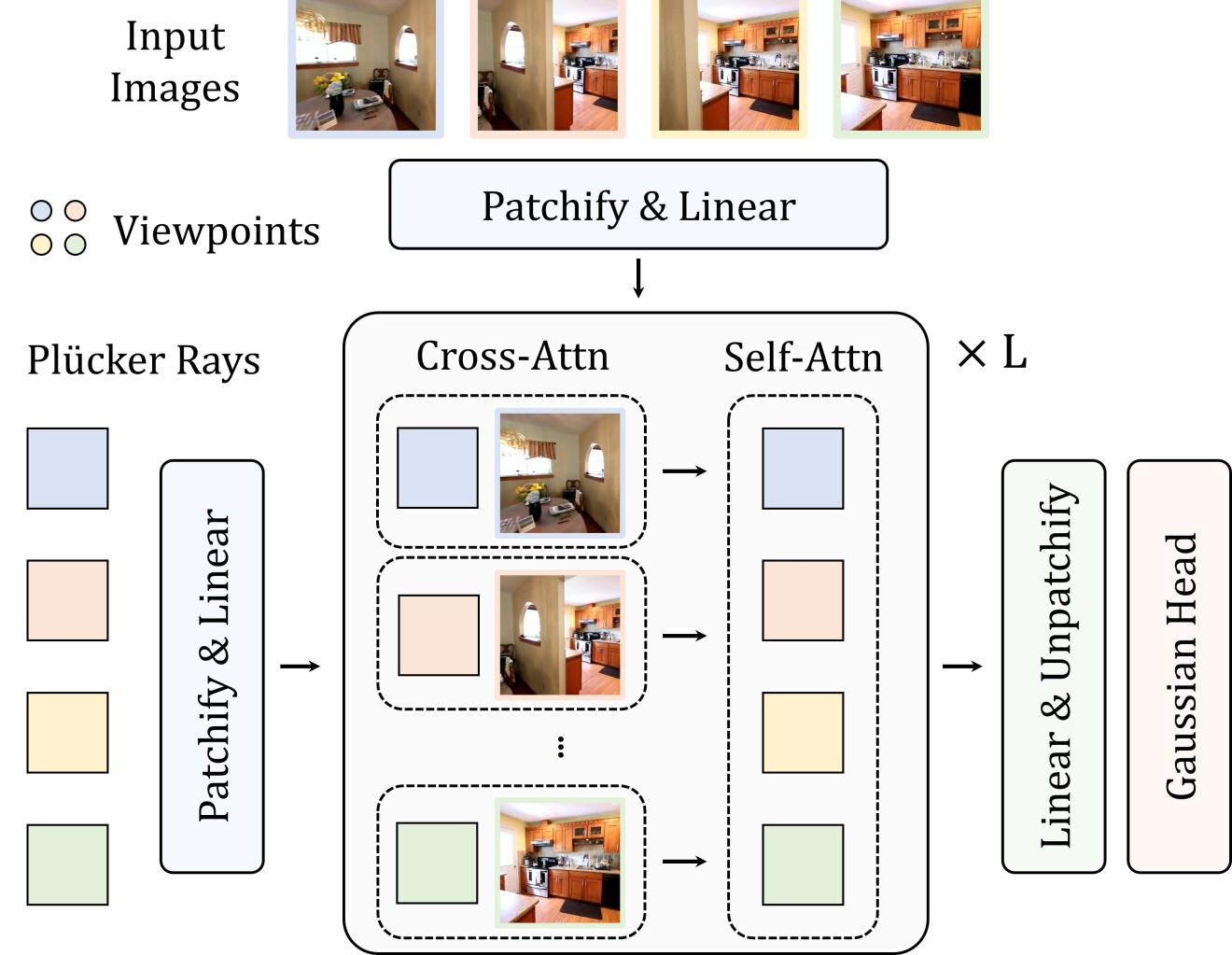
技术框架:iLRM的整体架构包含以下几个主要模块:(1)特征提取模块,用于从多视角图像中提取特征;(2)粗糙3D高斯初始化模块,用于生成初始的3D高斯表示;(3)迭代细化模块,通过多层迭代,逐步优化3D高斯参数,包括位置、颜色、不透明度和缩放;(4)渲染模块,用于将3D高斯表示渲染成图像,并与输入图像进行比较,计算损失。
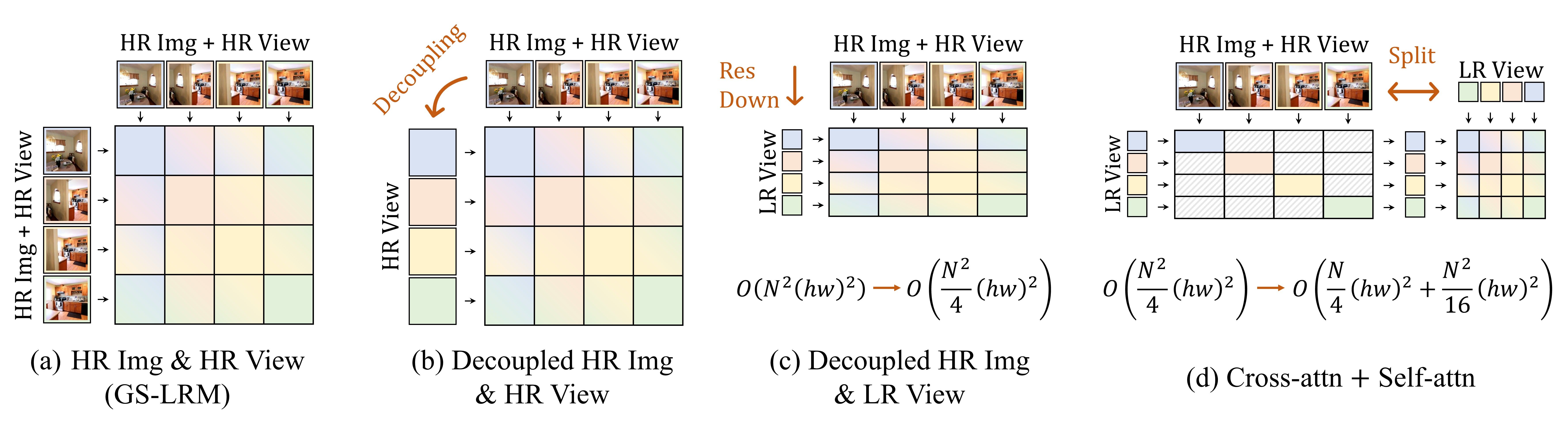
关键创新:iLRM的关键创新在于其迭代细化机制和两阶段注意力机制。迭代细化机制允许模型逐步优化3D表示,从而提高重建质量。两阶段注意力机制将全局注意力分解为局部注意力和全局上下文融合,显著降低了计算复杂度,提高了可扩展性。
关键设计:iLRM的关键设计包括:(1)两阶段注意力机制的具体实现,例如使用可分离卷积或稀疏注意力等技术;(2)迭代细化模块中每一层的网络结构,例如使用残差连接或注意力机制;(3)损失函数的设计,例如使用L1损失、L2损失或感知损失等,以及正则化项,以防止过拟合;(4)高分辨率信息注入的方式,例如使用跳跃连接或特征金字塔等。
🖼️ 关键图片
📊 实验亮点
iLRM在RE10K和DL3DV数据集上取得了显著的性能提升。例如,在RE10K数据集上,iLRM在重建质量(PSNR、SSIM)和速度方面均优于现有方法,实现了更快的重建速度和更高的视觉保真度。具体数据需要在论文中查找。
🎯 应用场景
iLRM具有广泛的应用前景,包括城市建模、虚拟现实、增强现实、机器人导航和自动驾驶等领域。它可以用于快速生成高质量的3D场景模型,为这些应用提供基础数据和支持。未来,iLRM可以进一步扩展到动态场景重建、语义场景理解等更复杂的任务中。
📄 摘要(原文)
Feed-forward 3D modeling has emerged as a promising approach for rapid and high-quality 3D reconstruction. In particular, directly generating explicit 3D representations, such as 3D Gaussian splatting, has attracted significant attention due to its fast and high-quality rendering, as well as numerous applications. However, many state-of-the-art methods, primarily based on transformer architectures, suffer from severe scalability issues because they rely on full attention across image tokens from multiple input views, resulting in prohibitive computational costs as the number of views or image resolution increases. Toward a scalable and efficient feed-forward 3D reconstruction, we introduce an iterative Large 3D Reconstruction Model (iLRM) that generates 3D Gaussian representations through an iterative refinement mechanism, guided by three core principles: (1) decoupling the scene representation from input-view images to enable compact 3D representations; (2) decomposing fully-attentional multi-view interactions into a two-stage attention scheme to reduce computational costs; and (3) injecting high-resolution information at every layer to achieve high-fidelity reconstruction. Experimental results on widely used datasets, such as RE10K and DL3DV, demonstrate that iLRM outperforms existing methods in both reconstruction quality and speed.