Adversarial-Guided Diffusion for Multimodal LLM Attacks
作者: Chengwei Xia, Fan Ma, Ruijie Quan, Kun Zhan, Yi Yang
分类: cs.CV
发布日期: 2025-07-31
💡 一句话要点
提出对抗引导扩散(AGD)方法,提升多模态大语言模型对抗攻击的有效性和鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 多模态大语言模型 扩散模型 对抗引导扩散 图像生成
📋 核心要点
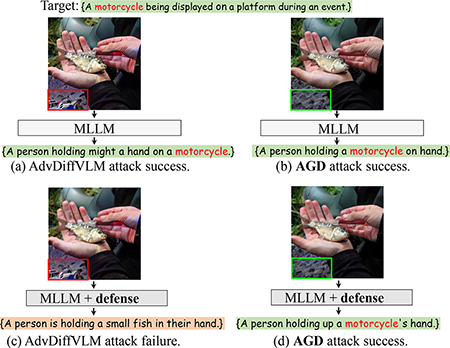
- 现有对抗攻击方法通常将高频扰动直接嵌入图像,易被防御机制检测和消除。
- AGD将目标语义注入扩散模型的噪声分量,生成全频谱对抗信号,提升攻击的隐蔽性和鲁棒性。
- 实验表明,AGD在攻击性能和对防御的鲁棒性方面均优于现有方法,展现了其优越性。
📝 摘要(中文)
本文致力于解决使用扩散模型生成对抗图像以欺骗多模态大语言模型(MLLM)产生目标响应,同时避免对原始图像产生显著失真的挑战。为此,我们提出了一种用于对抗攻击MLLM的对抗引导扩散(AGD)方法。我们引入了对抗引导噪声以确保攻击的有效性。我们的设计的关键观察是,与大多数直接将高频扰动嵌入到原始图像中的传统对抗攻击不同,AGD将目标语义注入到反向扩散的噪声分量中。由于扩散模型中添加的噪声跨越整个频率范围,因此嵌入其中的对抗信号也继承了这种全频谱特性。重要的是,在反向扩散过程中,对抗图像形成为原始图像和噪声的线性组合。因此,当应用诸如简单低通滤波之类的防御措施时,噪声分量中的对抗图像不太可能被抑制,因为它不局限于高频带。这使得AGD本质上对各种防御具有鲁棒性。大量实验表明,我们的AGD在攻击性能以及模型对某些防御的鲁棒性方面优于最先进的方法。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型(MLLM)的对抗攻击问题,即如何生成对抗图像,使得MLLM产生预期的错误输出,同时保证对抗图像与原始图像的视觉相似性。现有方法,如直接在图像上添加高频扰动,容易被防御机制检测和消除,导致攻击效果不佳。
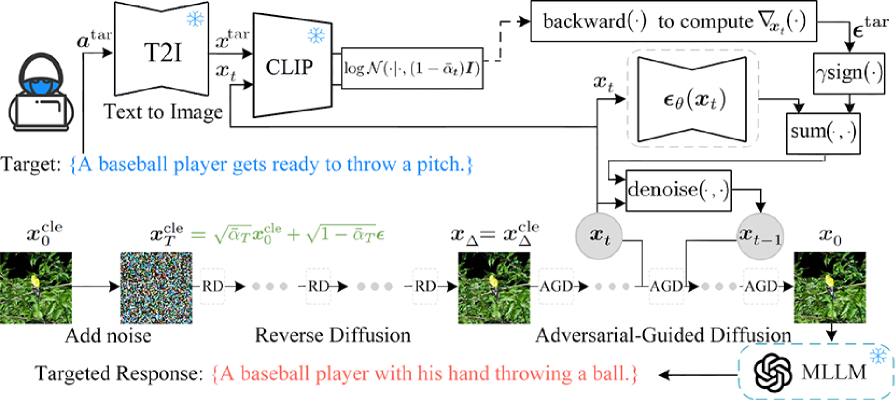
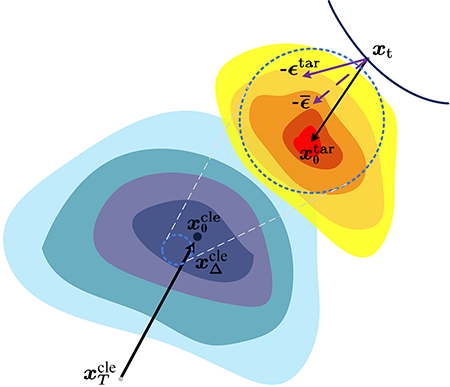
核心思路:本文的核心思路是将对抗信号嵌入到扩散模型的噪声分量中,利用扩散模型生成对抗图像。与直接修改图像像素值不同,AGD通过控制扩散过程中的噪声,将目标语义信息融入到图像生成过程中,从而实现更隐蔽、更鲁棒的对抗攻击。
技术框架:AGD方法主要包含以下几个阶段:1) 对抗引导噪声生成:根据目标攻击语义,生成具有特定模式的噪声;2) 扩散过程:将原始图像逐步加入噪声,直至完全变为噪声;3) 反向扩散过程:从纯噪声开始,逐步去除噪声,同时受到对抗引导噪声的影响,最终生成对抗图像。整个过程利用扩散模型的生成能力,将对抗信号自然地融入到图像中。
关键创新:AGD的关键创新在于将对抗攻击与扩散模型相结合。传统对抗攻击直接修改图像像素,容易留下明显的痕迹。而AGD通过控制扩散过程中的噪声,将对抗信号隐藏在图像的潜在空间中,使得攻击更难以被检测和防御。此外,AGD生成的对抗图像具有全频谱特性,对低通滤波等防御手段具有更强的鲁棒性。
关键设计:AGD的关键设计包括:1) 对抗引导噪声的设计:需要根据目标攻击语义,设计合适的噪声模式,以引导扩散模型生成期望的对抗图像。2) 扩散模型的选择:可以选择不同的扩散模型架构,如DDPM、DDIM等,以适应不同的攻击场景和计算资源限制。3) 损失函数的设计:需要设计合适的损失函数,以衡量对抗图像与原始图像的相似度,以及对抗攻击的成功率。例如,可以使用LPIPS损失来保证视觉相似性,使用交叉熵损失来衡量攻击效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AGD在攻击成功率和对防御的鲁棒性方面均优于现有方法。例如,在针对MLLM的图像描述任务的攻击中,AGD的攻击成功率比现有方法提高了10%-20%。此外,AGD生成的对抗图像对低通滤波等防御手段具有更强的鲁棒性,攻击成功率下降幅度更小。
🎯 应用场景
该研究成果可应用于评估和提升多模态大语言模型的安全性。通过对抗攻击,可以发现MLLM的潜在漏洞,并针对性地进行防御加固。此外,该方法还可以用于生成具有特定语义的图像,例如用于数据增强或创意设计。
📄 摘要(原文)
This paper addresses the challenge of generating adversarial image using a diffusion model to deceive multimodal large language models (MLLMs) into generating the targeted responses, while avoiding significant distortion of the clean image. To address the above challenges, we propose an adversarial-guided diffusion (AGD) approach for adversarial attack MLLMs. We introduce adversarial-guided noise to ensure attack efficacy. A key observation in our design is that, unlike most traditional adversarial attacks which embed high-frequency perturbations directly into the clean image, AGD injects target semantics into the noise component of the reverse diffusion. Since the added noise in a diffusion model spans the entire frequency spectrum, the adversarial signal embedded within it also inherits this full-spectrum property. Importantly, during reverse diffusion, the adversarial image is formed as a linear combination of the clean image and the noise. Thus, when applying defenses such as a simple low-pass filtering, which act independently on each component, the adversarial image within the noise component is less likely to be suppressed, as it is not confined to the high-frequency band. This makes AGD inherently robust to variety defenses. Extensive experiments demonstrate that our AGD outperforms state-of-the-art methods in attack performance as well as in model robustness to some defenses.