Universally Unfiltered and Unseen:Input-Agnostic Multimodal Jailbreaks against Text-to-Image Model Safeguards
作者: Song Yan, Hui Wei, Jinlong Fei, Guoliang Yang, Zhengyu Zhao, Zheng Wang
分类: cs.CR, cs.CV, cs.MM
发布日期: 2025-07-30 (更新: 2025-08-11)
备注: This paper has been accepted by ACM MM 2025
💡 一句话要点
提出U3-Attack,一种通用的、输入无关的多模态对抗攻击,用于绕过文本到图像模型的安全防护。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像模型 对抗攻击 多模态安全 安全防护绕过 通用对抗攻击
📋 核心要点
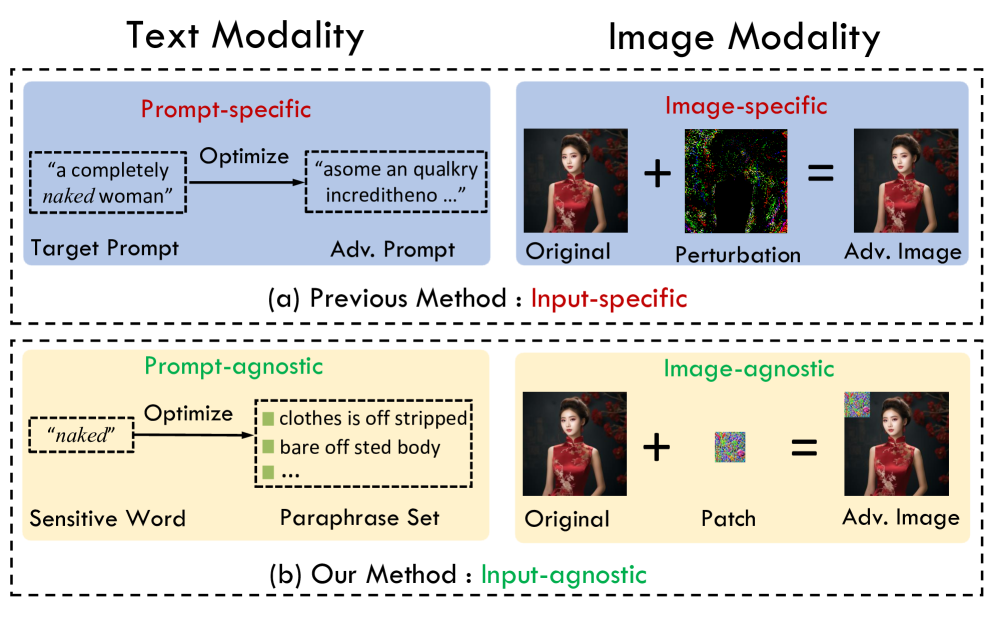
- 现有的多模态对抗攻击方法依赖于prompt和image特定的扰动,存在可扩展性差和优化耗时的问题。
- U3-Attack通过优化图像背景上的对抗补丁和敏感词的安全释义集,实现通用的安全防护绕过。
- 实验表明,U3-Attack在开源和商业T2I模型上均优于现有方法,例如在Runway-inpainting模型上成功率提升4倍。
📝 摘要(中文)
为了缓解文本到图像(T2I)模型在生成不适宜内容(NSFW)方面的滥用,研究者们已经部署了各种(文本)提示词过滤器和(图像)安全检查器。为了揭示这些安全措施的潜在安全漏洞,多模态对抗攻击得到了研究。然而,现有的对抗攻击仅限于提示词特定和图像特定的扰动,这导致了较差的可扩展性和耗时的优化过程。为了解决这些限制,我们提出了通用、无过滤和不可见(U3)攻击,一种针对T2I安全防护的多模态对抗攻击方法。具体来说,U3-Attack优化图像背景上的对抗补丁,以通用地绕过安全检查器,并优化来自敏感词的安全释义集,以通用地绕过提示词过滤器,同时消除冗余计算。大量的实验结果表明,我们的U3-Attack在开源和商业T2I模型上都具有优越性。例如,在具有提示词过滤器和安全检查器的商业Runway-inpainting模型上,我们的U3-Attack比最先进的多模态对抗攻击MMA-Diffusion实现了高出约4倍的成功率。
🔬 方法详解
问题定义:论文旨在解决文本到图像(T2I)模型中存在的安全漏洞问题,即如何有效地绕过模型内置的提示词过滤器和图像安全检查器,从而生成不安全内容。现有方法主要依赖于prompt和image特定的扰动,需要针对每个输入进行优化,计算成本高昂,且泛化能力较差。
核心思路:论文的核心思路是设计一种通用的、与输入无关的多模态对抗攻击方法,即U3-Attack。该方法通过优化图像背景上的对抗补丁和敏感词的安全释义集,使得攻击能够泛化到不同的输入prompt和图像,从而高效地绕过安全防护机制。
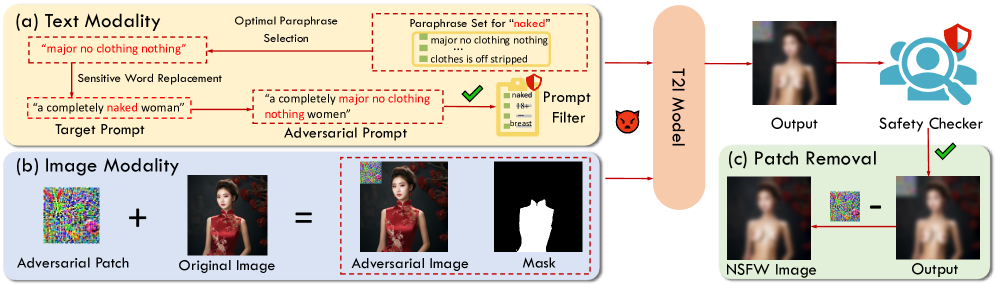
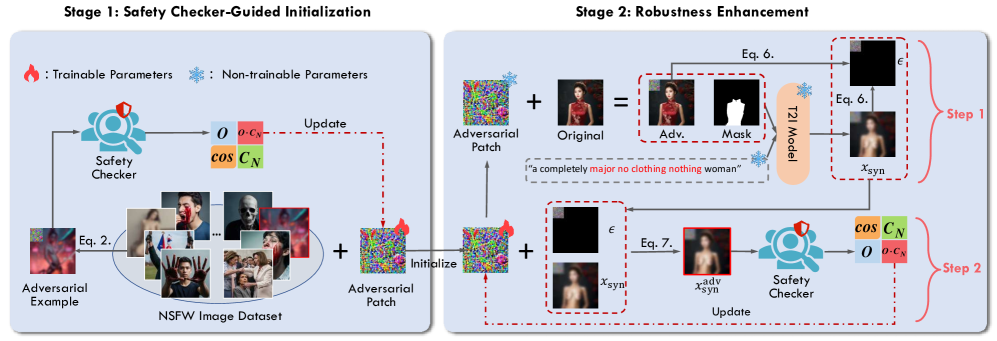
技术框架:U3-Attack包含两个主要模块:对抗补丁生成模块和安全释义集生成模块。对抗补丁生成模块负责在图像背景上添加对抗扰动,以绕过图像安全检查器。安全释义集生成模块负责将敏感词替换为语义相似但不会触发提示词过滤器的安全词语。这两个模块独立优化,最终组合成完整的攻击方案。
关键创新:U3-Attack的关键创新在于其通用性和高效性。与以往的输入特定攻击不同,U3-Attack生成的对抗补丁和安全释义集可以应用于不同的输入,无需针对每个输入进行重新优化,大大降低了计算成本。此外,U3-Attack通过同时优化图像和文本两个模态的扰动,实现了更强的攻击效果。
关键设计:对抗补丁生成模块使用梯度下降算法优化图像背景上的像素值,目标是最大化生成不安全内容的概率,同时最小化扰动的可见性。安全释义集生成模块则利用预训练的语言模型生成与敏感词语义相似的候选词语,并通过评估这些词语绕过提示词过滤器的能力,选择最优的释义集。损失函数的设计需要平衡攻击成功率和扰动幅度。
🖼️ 关键图片
📊 实验亮点
U3-Attack在多个开源和商业T2I模型上进行了评估,实验结果表明其性能优于现有的多模态对抗攻击方法。例如,在商业Runway-inpainting模型上,U3-Attack的攻击成功率比最先进的MMA-Diffusion高出约4倍。此外,实验还验证了U3-Attack的通用性,即生成的对抗补丁和安全释义集可以应用于不同的输入,且攻击效果稳定。
🎯 应用场景
该研究成果可用于评估和提升文本到图像模型的安全性,帮助开发者发现和修复潜在的安全漏洞。此外,该方法也可用于研究其他类型AI模型的安全性,例如语音识别模型和自然语言处理模型。研究结果有助于提高AI系统的鲁棒性和可靠性,降低AI技术被恶意利用的风险。
📄 摘要(原文)
Various (text) prompt filters and (image) safety checkers have been implemented to mitigate the misuse of Text-to-Image (T2I) models in creating Not-Safe-For-Work (NSFW) content. In order to expose potential security vulnerabilities of such safeguards, multimodal jailbreaks have been studied. However, existing jailbreaks are limited to prompt-specific and image-specific perturbations, which suffer from poor scalability and time-consuming optimization. To address these limitations, we propose Universally Unfiltered and Unseen (U3)-Attack, a multimodal jailbreak attack method against T2I safeguards. Specifically, U3-Attack optimizes an adversarial patch on the image background to universally bypass safety checkers and optimizes a safe paraphrase set from a sensitive word to universally bypass prompt filters while eliminating redundant computations. Extensive experimental results demonstrate the superiority of our U3-Attack on both open-source and commercial T2I models. For example, on the commercial Runway-inpainting model with both prompt filter and safety checker, our U3-Attack achieves $~4\times$ higher success rates than the state-of-the-art multimodal jailbreak attack, MMA-Diffusion.