ScreenCoder: Advancing Visual-to-Code Generation for Front-End Automation via Modular Multimodal Agents
作者: Yilei Jiang, Yaozhi Zheng, Yuxuan Wan, Jiaming Han, Qunzhong Wang, Michael R. Lyu, Xiangyu Yue
分类: cs.CV
发布日期: 2025-07-30 (更新: 2025-10-20)
备注: ScreenCoder-v2
🔗 代码/项目: GITHUB
💡 一句话要点
ScreenCoder:通过模块化多模态Agent提升视觉到代码的生成,用于前端自动化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉到代码生成 前端自动化 多模态大语言模型 模块化Agent UI设计 代码生成 监督微调 强化学习
📋 核心要点
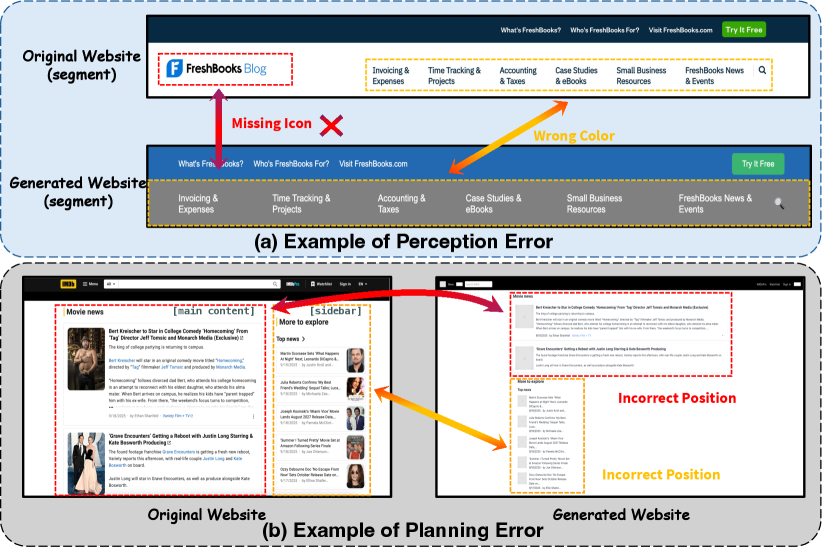
- 现有端到端多模态大语言模型在将复杂UI设计转换为代码时,难以兼顾视觉感知、布局规划和代码生成,容易出错。
- ScreenCoder采用模块化多Agent框架,将任务分解为grounding、planning和generation三个阶段,由专门Agent负责。
- ScreenCoder作为数据引擎生成高质量图像-代码对,并用于微调开源MLLM,在布局准确性等方面达到SOTA。
📝 摘要(中文)
本文提出ScreenCoder,一个模块化的多Agent框架,旨在解决将用户界面(UI)设计自动转换为前端代码的问题。现有多模态大语言模型(MLLM)在处理复杂UI时,难以在单一模型中统一视觉感知、布局规划和代码生成,导致感知和规划错误。ScreenCoder将任务分解为三个可解释的阶段:grounding, planning, 和 generation,并为每个阶段分配专门的Agent。这种分解显著提高了框架的鲁棒性和保真度,优于端到端方法。此外,ScreenCoder作为一个可扩展的数据引擎,能够生成高质量的图像-代码对。利用这些数据,通过监督微调和强化学习的双阶段pipeline对开源MLLM进行微调,显著提升了其UI生成能力。实验结果表明,该方法在布局准确性、结构一致性和代码正确性方面均达到了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决将用户界面(UI)设计稿自动转换为前端代码的问题。现有的端到端多模态大语言模型(MLLM)在处理复杂UI时,存在视觉感知、布局规划和代码生成能力不足的问题,容易产生感知和规划错误,导致生成的代码质量不高。
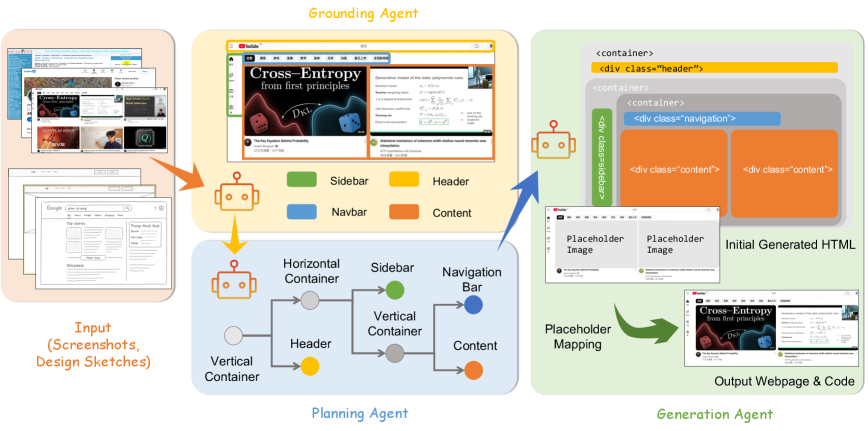
核心思路:论文的核心思路是将复杂的UI到代码生成任务分解为三个独立的、可解释的阶段:grounding(理解UI元素)、planning(规划布局结构)和generation(生成代码)。每个阶段由专门的Agent负责,从而降低了单个Agent的复杂度,提高了整体的鲁棒性和准确性。
技术框架:ScreenCoder框架包含三个主要模块:Grounding Agent、Planning Agent和Generation Agent。Grounding Agent负责从UI图像中提取元素信息,例如位置、大小、类型等。Planning Agent基于Grounding Agent的输出,规划UI的布局结构,例如使用何种布局方式(Flexbox、Grid等)。Generation Agent根据布局规划和元素信息,生成最终的前端代码。整个流程是串行的,每个Agent的输出作为下一个Agent的输入。
关键创新:ScreenCoder的关键创新在于其模块化的多Agent架构,将复杂的端到端任务分解为多个独立的子任务,每个子任务由专门的Agent负责。这种分解降低了单个Agent的复杂度,使得每个Agent可以专注于自己的任务,从而提高了整体的性能。与现有的端到端方法相比,ScreenCoder具有更高的可解释性和可控性。
关键设计:论文使用预训练的多模态模型作为每个Agent的基础模型,并通过微调来适应特定的任务。例如,Grounding Agent可以使用目标检测模型,Planning Agent可以使用序列到序列模型,Generation Agent可以使用代码生成模型。此外,论文还设计了一个双阶段的微调pipeline,包括监督微调和强化学习,以进一步提高模型的性能。具体参数设置和损失函数等细节在论文中有详细描述,此处未知。
🖼️ 关键图片

📊 实验亮点
ScreenCoder在布局准确性、结构一致性和代码正确性方面均达到了最先进的性能。通过模块化设计和双阶段微调,ScreenCoder显著提升了UI生成能力,优于现有的端到端方法。具体实验数据未知,但论文强调了其在多个指标上的SOTA表现。
🎯 应用场景
ScreenCoder具有广泛的应用前景,可以用于加速软件开发流程,降低前端开发的门槛。它可以帮助设计师快速将设计稿转换为可用的代码,减少开发人员的手动编码工作量。此外,ScreenCoder还可以用于自动化测试和UI生成等领域,提高软件开发的效率和质量。未来,该技术有望应用于更复杂的UI设计和跨平台开发。
📄 摘要(原文)
Automating the transformation of user interface (UI) designs into front-end code holds significant promise for accelerating software development and democratizing design workflows. While multimodal large language models (MLLMs) can translate images to code, they often fail on complex UIs, struggling to unify visual perception, layout planning, and code synthesis within a single monolithic model, which leads to frequent perception and planning errors. To address this, we propose ScreenCoder, a modular multi-agent framework that decomposes the task into three interpretable stages: grounding, planning, and generation. By assigning these distinct responsibilities to specialized agents, our framework achieves significantly higher robustness and fidelity than end-to-end approaches. Furthermore, ScreenCoder serves as a scalable data engine, enabling us to generate high-quality image-code pairs. We use this data to fine-tune open-source MLLM via a dual-stage pipeline of supervised fine-tuning and reinforcement learning, demonstrating substantial gains in its UI generation capabilities. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in layout accuracy, structural coherence, and code correctness. Our code is made publicly available at https://github.com/leigest519/ScreenCoder.