DepR: Depth Guided Single-view Scene Reconstruction with Instance-level Diffusion
作者: Qingcheng Zhao, Xiang Zhang, Haiyang Xu, Zeyuan Chen, Jianwen Xie, Yuan Gao, Zhuowen Tu
分类: cs.CV
发布日期: 2025-07-30
备注: ICCV 2025
💡 一句话要点
DepR:深度引导的单视图场景重建,融合实例级扩散模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单视图重建 深度引导 扩散模型 实例级生成 场景理解
📋 核心要点
- 现有单视图场景重建方法未能充分利用深度信息,限制了重建质量和几何一致性。
- DepR通过深度引导的实例级扩散模型,显式地将深度信息融入到对象生成和布局优化中。
- 实验表明,DepR在合成和真实数据集上均取得了SOTA性能,展现了良好的泛化能力。
📝 摘要(中文)
本文提出DepR,一个深度引导的单视图场景重建框架,它在组合范式中集成了实例级别的扩散模型。DepR不是整体地重建整个场景,而是生成单个对象,然后将它们组合成一个连贯的3D布局。与之前仅在推理期间使用深度进行对象布局估计,因此未能充分利用其丰富的几何信息的方法不同,DepR在训练和推理过程中都利用了深度。具体来说,我们引入了深度引导的条件作用,以有效地将形状先验编码到扩散模型中。在推理过程中,深度进一步指导DDIM采样和布局优化,从而增强重建与输入图像之间的对齐。尽管DepR仅在有限的合成数据上进行训练,但它在单视图场景重建中实现了最先进的性能,并通过在合成和真实世界数据集上的评估证明了其强大的泛化能力。
🔬 方法详解
问题定义:单视图场景重建旨在从单个图像中恢复场景的3D结构。现有方法通常未能充分利用深度信息,或者在推理阶段才使用深度进行布局估计,导致重建结果与输入图像的几何信息不一致,且泛化能力有限。
核心思路:DepR的核心思路是将深度信息贯穿于训练和推理过程,通过深度引导的扩散模型生成具有几何一致性的实例,并将其组合成完整的3D场景。这种方法能够更有效地利用深度信息,提高重建质量和泛化能力。
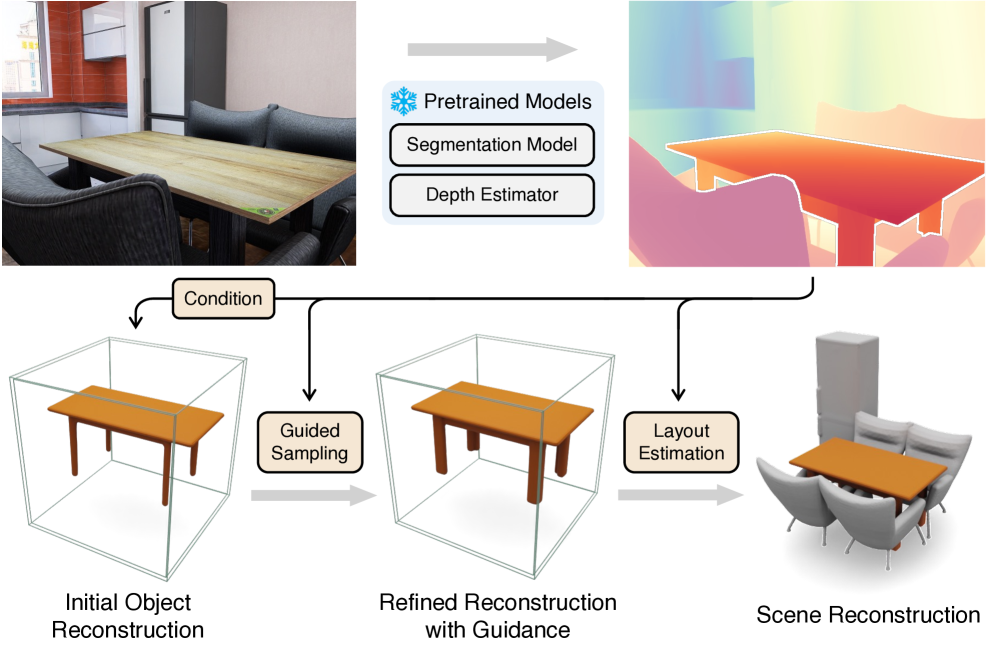
技术框架:DepR框架主要包含以下几个模块:1) 深度估计模块:用于从输入图像中估计深度图;2) 深度引导的扩散模型:用于生成单个对象的3D形状,该模型以深度图作为条件输入;3) 布局优化模块:用于将生成的对象组合成一个连贯的3D场景,该模块也利用深度信息进行优化。整个流程是先估计深度,然后利用深度信息引导实例生成和布局优化,最终得到重建的3D场景。
关键创新:DepR的关键创新在于深度引导的实例级扩散模型。该模型通过将深度信息作为条件输入,能够生成与输入图像几何信息一致的3D对象。此外,DepR在训练和推理过程中都利用了深度信息,从而更有效地利用了深度信息的优势。
关键设计:在深度引导的扩散模型中,作者使用了深度图的编码作为扩散模型的条件输入。具体来说,深度图首先经过一个编码器网络提取特征,然后将特征与扩散模型的中间层特征进行融合。此外,在布局优化模块中,作者设计了一个损失函数,用于衡量重建结果与输入图像之间的几何一致性,该损失函数包括深度一致性损失和法向量一致性损失。
🖼️ 关键图片


📊 实验亮点
DepR在合成和真实数据集上均取得了SOTA性能。在合成数据集上,DepR的重建质量和几何一致性均优于现有方法。在真实数据集上,DepR展现了良好的泛化能力,能够重建出具有几何细节的3D场景。具体性能数据未知。
🎯 应用场景
DepR在机器人导航、虚拟现实、增强现实、自动驾驶等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,为用户提供更逼真的虚拟现实体验,并提高自动驾驶系统的安全性。
📄 摘要(原文)
We propose DepR, a depth-guided single-view scene reconstruction framework that integrates instance-level diffusion within a compositional paradigm. Instead of reconstructing the entire scene holistically, DepR generates individual objects and subsequently composes them into a coherent 3D layout. Unlike previous methods that use depth solely for object layout estimation during inference and therefore fail to fully exploit its rich geometric information, DepR leverages depth throughout both training and inference. Specifically, we introduce depth-guided conditioning to effectively encode shape priors into diffusion models. During inference, depth further guides DDIM sampling and layout optimization, enhancing alignment between the reconstruction and the input image. Despite being trained on limited synthetic data, DepR achieves state-of-the-art performance and demonstrates strong generalization in single-view scene reconstruction, as shown through evaluations on both synthetic and real-world datasets.