MoCHA: Advanced Vision-Language Reasoning with MoE Connector and Hierarchical Group Attention
作者: Yuqi Pang, Bowen Yang, Yun Cao, Rong Fan, Xiaoyu Li, Chen He
分类: cs.CV, cs.AI
发布日期: 2025-07-30 (更新: 2025-11-17)
💡 一句话要点
提出MoCHA以解决视觉语言模型的训练与推理成本问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态学习 稀疏混合专家 层次化组注意力 特征提取 智能视觉助手 模型优化
📋 核心要点
- 现有的视觉语言模型在处理复杂视觉信息时面临高昂的训练和推理成本,以及跨模态信息提取的困难。
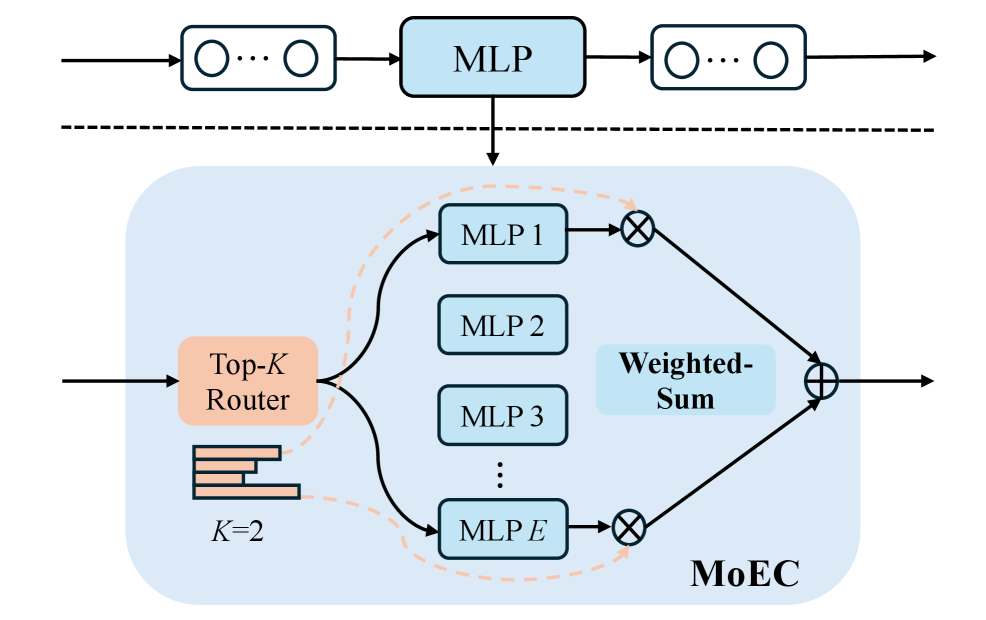
- 本文提出的MoCHA框架通过集成多种视觉主干和稀疏混合专家连接器,动态选择适应不同视觉特征的专家,从而提高视觉信息的利用效率。
- 实验结果显示,MoCHA在多个任务上超越了最先进的开源模型,例如在POPE任务中减少幻觉的表现提升了3.25%。
📝 摘要(中文)
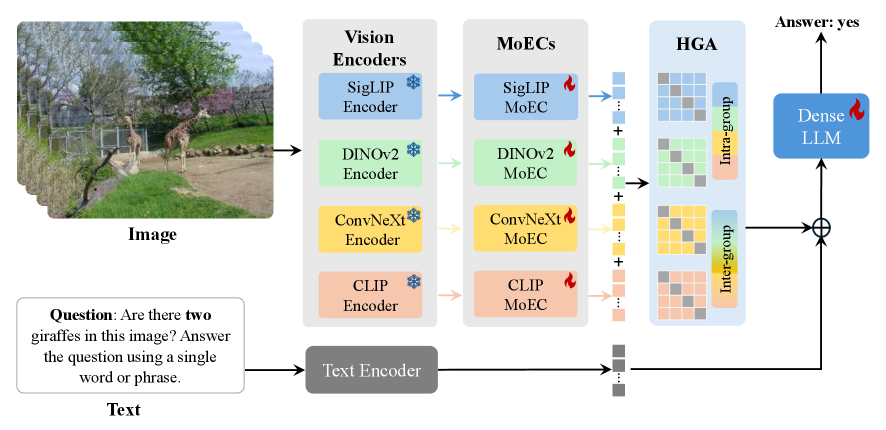
视觉大型语言模型(VLLMs)主要集中在处理复杂和细粒度的视觉信息,但面临高训练和推理成本以及跨模态桥接的挑战。本文提出了一种新颖的视觉框架MoCHA,集成了四个视觉主干(CLIP、SigLIP、DINOv2和ConvNeXt)以提取互补的视觉特征,并配备稀疏混合专家连接器(MoECs)模块,动态选择适应不同视觉维度的专家。为了解决MoECs模块编码的视觉信息的冗余或不足使用,本文进一步设计了具有组内和组间操作的层次化组注意力(HGA)及自适应门控策略。实验表明,MoCHA在多个基准测试中超越了现有的开源模型,尤其在减轻幻觉和遵循视觉指令方面表现突出。
🔬 方法详解
问题定义:本文旨在解决现有视觉语言模型在处理复杂视觉信息时的高训练和推理成本,以及在跨模态信息提取中的不足。现有方法往往无法有效利用视觉信息,导致性能受限。
核心思路:论文提出的MoCHA框架通过集成多个视觉主干(CLIP、SigLIP、DINOv2和ConvNeXt)来提取互补的视觉特征,并利用稀疏混合专家连接器(MoECs)动态选择适应不同视觉维度的专家,从而提高信息的有效利用。
技术框架:MoCHA的整体架构包括四个视觉主干用于特征提取,MoECs模块用于动态选择专家,以及层次化组注意力(HGA)模块用于优化特征的使用。HGA模块通过组内和组间操作以及自适应门控策略来增强特征的表达能力。
关键创新:MoCHA的主要创新在于结合了多种视觉主干和稀疏混合专家机制,显著提高了视觉信息的利用效率,并通过层次化组注意力优化了特征的编码与解码过程。这种设计与现有方法相比,能够更灵活地适应不同的视觉任务。
关键设计:在MoCHA中,MoECs模块的设计允许根据输入的视觉特征动态选择专家,减少冗余计算。同时,HGA模块通过自适应门控策略,确保了特征的有效利用,提升了模型的整体性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MoCHA在多个基准测试中表现优异,特别是在POPE任务中减少幻觉的表现提升了3.25%,在遵循视觉指令的MME任务中提高了153分,显示出其在实际应用中的强大能力。
🎯 应用场景
该研究的潜在应用场景包括智能视觉助手、自动驾驶、医疗影像分析等领域,能够有效提升多模态系统的理解和响应能力。未来,MoCHA框架有望在更广泛的视觉语言任务中发挥重要作用,推动智能系统的进一步发展。
📄 摘要(原文)
Vision large language models (VLLMs) are focusing primarily on handling complex and fine-grained visual information by incorporating advanced vision encoders and scaling up visual models. However, these approaches face high training and inference costs, as well as challenges in extracting visual details, effectively bridging across modalities. In this work, we propose a novel visual framework, MoCHA, to address these issues. Our framework integrates four vision backbones (i.e., CLIP, SigLIP, DINOv2 and ConvNeXt) to extract complementary visual features and is equipped with a sparse Mixture of Experts Connectors (MoECs) module to dynamically select experts tailored to different visual dimensions. To mitigate redundant or insufficient use of the visual information encoded by the MoECs module, we further design a Hierarchical Group Attention (HGA) with intra- and inter-group operations and an adaptive gating strategy for encoded visual features. We train MoCHA on two mainstream LLMs (e.g., Phi2-2.7B and Vicuna-7B) and evaluate their performance across various benchmarks. Notably, MoCHA outperforms state-of-the-art open-weight models on various tasks. For example, compared to CuMo (Mistral-7B), our MoCHA (Phi2-2.7B) presents outstanding abilities to mitigate hallucination by showing improvements of 3.25% in POPE and to follow visual instructions by raising 153 points on MME. Finally, ablation studies further confirm the effectiveness and robustness of the proposed MoECs and HGA in improving the overall performance of MoCHA.