LIDAR: Lightweight Adaptive Cue-Aware Fusion Vision Mamba for Multimodal Segmentation of Structural Cracks
作者: Hui Liu, Chen Jia, Fan Shi, Xu Cheng, Mengfei Shi, Xia Xie, Shengyong Chen
分类: cs.CV, cs.AI
发布日期: 2025-07-30 (更新: 2025-07-31)
备注: This paper has been accepted by ACM MM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出LIDAR:轻量级自适应线索感知视觉Mamba网络,用于结构裂缝的多模态分割。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 裂缝分割 多模态融合 视觉Mamba 轻量级网络 自适应感知 结构健康监测 计算机视觉
📋 核心要点
- 现有裂缝分割方法难以在低计算成本下,有效融合多模态信息,实现像素级分割。
- LIDAR通过自适应线索感知和动态协作融合,有效整合多模态形态和纹理信息。
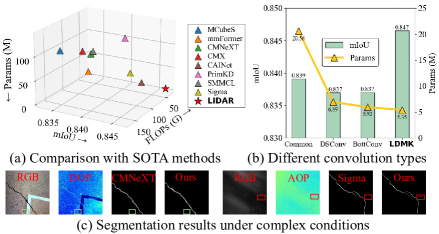
- 实验表明,LIDAR在多个数据集上超越SOTA方法,并在光场深度数据集上取得显著性能提升。
📝 摘要(中文)
本文提出了一种轻量级自适应线索感知视觉Mamba网络(LIDAR),旨在以低计算成本实现多模态数据下的像素级裂缝分割。现有方法缺乏对跨模态特征的自适应感知和高效交互融合能力。LIDAR通过轻量级自适应线索感知视觉状态空间模块(LacaVSS)和轻量级双域动态协作融合模块(LD3CF)有效地感知和整合来自不同模态的形态和纹理线索,从而生成清晰的像素级裂缝分割图。LacaVSS通过提出的掩码引导的高效动态引导扫描策略(EDG-SS)自适应地建模裂缝线索。LD3CF利用自适应频域感知器(AFDP)和双池化融合策略来有效地捕获跨模态的空间和频域线索。此外,我们设计了一种轻量级动态调制多核卷积(LDMK)以最小的计算开销感知复杂的形态结构,替代LIDAR中的大部分卷积操作。在三个数据集上的实验表明,我们的方法优于其他最先进的方法。在光场深度数据集上,我们的方法仅使用5.35M参数就实现了0.8204的F1和0.8465的mIoU。
🔬 方法详解
问题定义:论文旨在解决多模态裂缝分割任务中,现有方法无法兼顾分割精度和计算效率的问题。现有方法在跨模态特征的自适应感知和高效融合方面存在不足,导致分割结果不理想,且计算成本较高。
核心思路:论文的核心思路是设计一个轻量级的网络结构,能够自适应地感知不同模态的裂缝线索,并高效地融合这些线索。通过引入Mamba架构和精心设计的模块,在保证分割精度的同时,降低计算复杂度。
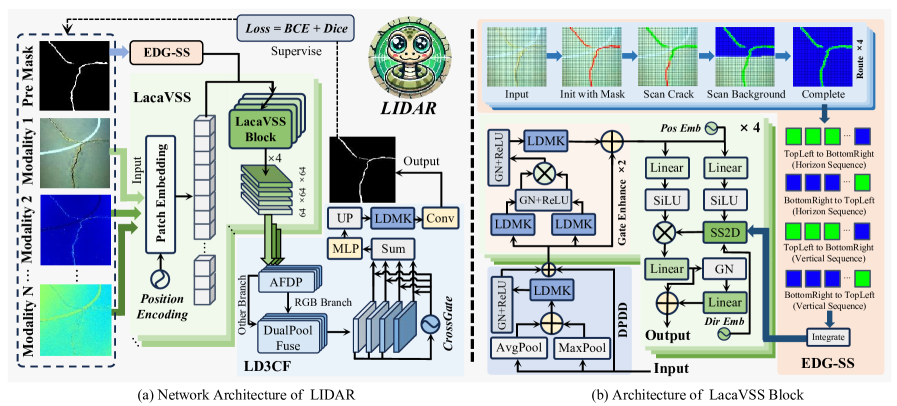
技术框架:LIDAR网络主要由两个核心模块组成:轻量级自适应线索感知视觉状态空间模块(LacaVSS)和轻量级双域动态协作融合模块(LD3CF)。LacaVSS负责从单模态数据中提取特征,并自适应地建模裂缝线索。LD3CF负责融合来自不同模态的特征,并利用空间和频域信息进行分割。此外,还使用了轻量级动态调制多核卷积(LDMK)来降低计算成本。
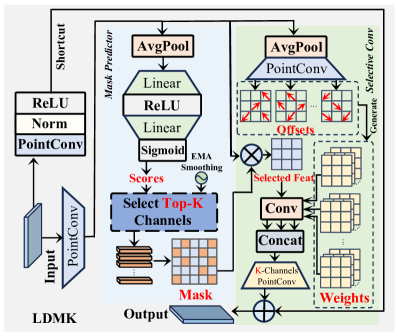
关键创新:论文的关键创新在于以下几点:1) 提出了LacaVSS模块,通过掩码引导的高效动态引导扫描策略(EDG-SS)自适应地建模裂缝线索。2) 提出了LD3CF模块,利用自适应频域感知器(AFDP)和双池化融合策略来有效地捕获跨模态的空间和频域线索。3) 设计了LDMK,以最小的计算开销感知复杂的形态结构。
关键设计:LacaVSS模块中的EDG-SS策略利用掩码信息来引导扫描过程,从而提高特征提取的效率。LD3CF模块中的AFDP利用频域信息来增强特征的表达能力。LDMK采用动态调制和多核卷积,能够在降低计算成本的同时,保持模型的表达能力。损失函数未知。
🖼️ 关键图片
📊 实验亮点
LIDAR在三个数据集上均取得了优于SOTA方法的性能。特别是在光场深度数据集上,LIDAR仅使用5.35M参数,就实现了0.8204的F1值和0.8465的mIoU值,表明该方法在保证分割精度的同时,具有很高的计算效率。
🎯 应用场景
该研究成果可应用于桥梁、隧道、道路等基础设施的裂缝检测与分割,有助于实现自动化、高精度的结构健康监测,降低人工检测成本,提高检测效率,为基础设施的安全维护提供保障,具有重要的社会和经济价值。
📄 摘要(原文)
Achieving pixel-level segmentation with low computational cost using multimodal data remains a key challenge in crack segmentation tasks. Existing methods lack the capability for adaptive perception and efficient interactive fusion of cross-modal features. To address these challenges, we propose a Lightweight Adaptive Cue-Aware Vision Mamba network (LIDAR), which efficiently perceives and integrates morphological and textural cues from different modalities under multimodal crack scenarios, generating clear pixel-level crack segmentation maps. Specifically, LIDAR is composed of a Lightweight Adaptive Cue-Aware Visual State Space module (LacaVSS) and a Lightweight Dual Domain Dynamic Collaborative Fusion module (LD3CF). LacaVSS adaptively models crack cues through the proposed mask-guided Efficient Dynamic Guided Scanning Strategy (EDG-SS), while LD3CF leverages an Adaptive Frequency Domain Perceptron (AFDP) and a dual-pooling fusion strategy to effectively capture spatial and frequency-domain cues across modalities. Moreover, we design a Lightweight Dynamically Modulated Multi-Kernel convolution (LDMK) to perceive complex morphological structures with minimal computational overhead, replacing most convolutional operations in LIDAR. Experiments on three datasets demonstrate that our method outperforms other state-of-the-art (SOTA) methods. On the light-field depth dataset, our method achieves 0.8204 in F1 and 0.8465 in mIoU with only 5.35M parameters. Code and datasets are available at https://github.com/Karl1109/LIDAR-Mamba.