MINR: Implicit Neural Representations with Masked Image Modelling
作者: Sua Lee, Joonhun Lee, Myungjoo Kang
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-30
备注: Accepted to the ICCV 2023 workshop on Out-of-Distribution Generalization in Computer Vision
💡 一句话要点
提出MINR框架,结合隐式神经表示与掩码图像建模,提升图像重建的鲁棒性和泛化性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 隐式神经表示 掩码图像建模 自监督学习 图像重建 鲁棒性 泛化能力 分布外数据 连续表示
📋 核心要点
- 现有基于掩码自编码器的自监督学习方法依赖于特定的掩码策略,在处理分布外数据时性能下降。
- MINR框架结合隐式神经表示,学习图像的连续函数表达,从而提升重建的鲁棒性和泛化能力,减少对特定掩码策略的依赖。
- 实验结果表明,MINR在同分布和异分布场景下均优于MAE,同时降低了模型复杂度,并可应用于多种自监督学习任务。
📝 摘要(中文)
本文提出了一种名为掩码隐式神经表示(MINR)的框架,它将隐式神经表示与掩码图像建模相结合。MINR学习一个连续函数来表示图像,从而实现更鲁棒和更具泛化性的重建,且不受掩码策略的影响。实验表明,MINR不仅在同分布场景中优于掩码自编码器(MAE),而且在异分布设置中也表现更好,同时降低了模型复杂度。MINR的多功能性扩展到各种自监督学习应用,证实了其作为现有框架的稳健且高效的替代方案的实用性。
🔬 方法详解
问题定义:现有基于掩码图像建模的自监督学习方法,如MAE,在很大程度上依赖于训练期间使用的掩码策略。当应用于分布外数据时,这些方法通常表现出性能下降,缺乏鲁棒性和泛化能力。因此,如何设计一种对掩码策略不敏感,且能有效处理分布外数据的图像重建方法是一个关键问题。
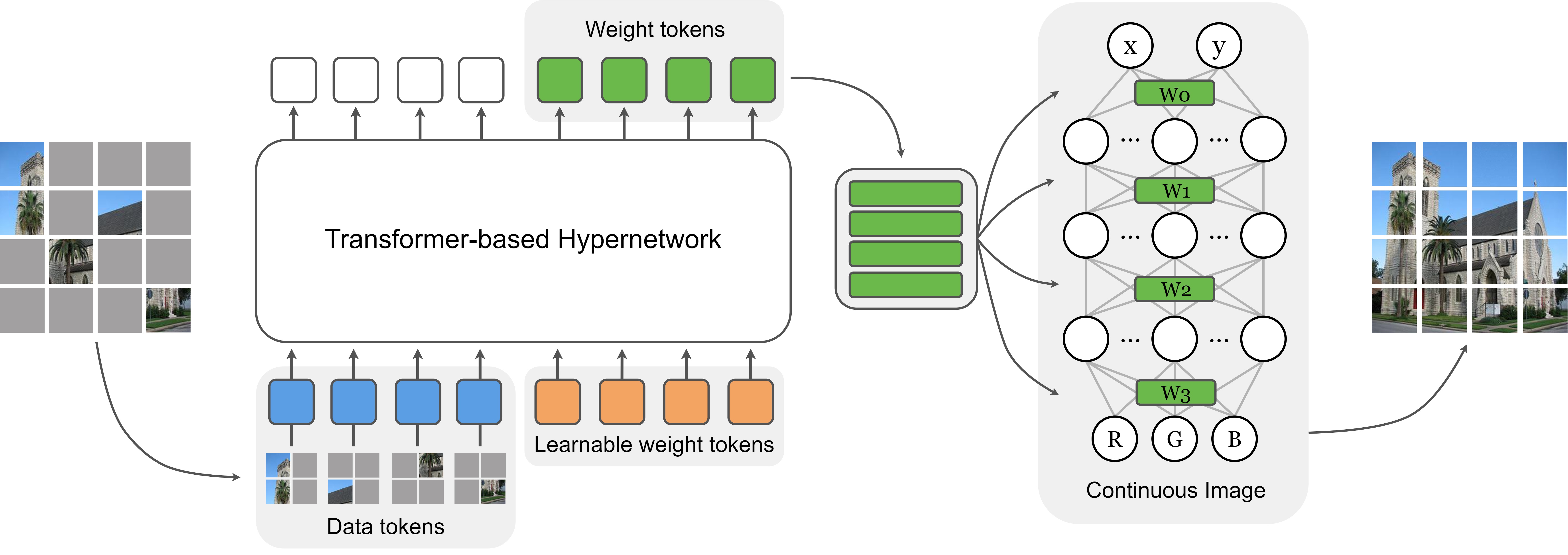
核心思路:MINR的核心思路是将图像表示为一个连续函数,利用隐式神经表示(INR)的优势。通过学习一个将坐标映射到像素值的函数,MINR能够捕获图像的底层结构,从而实现更鲁棒的重建,减少对特定掩码策略的依赖。这种连续表示使得模型能够更好地泛化到未见过的掩码模式和分布外数据。
技术框架:MINR框架主要包含以下几个步骤:1. 图像编码:输入图像被随机掩码。2. 坐标采样:从图像坐标空间中采样坐标点。3. 隐式表示:将采样坐标输入到隐式神经表示网络中,该网络预测对应坐标的像素值。4. 重建损失:计算预测像素值与原始像素值之间的重建损失,用于优化隐式神经表示网络。整个框架通过最小化重建误差来学习图像的连续表示。
关键创新:MINR的关键创新在于将隐式神经表示与掩码图像建模相结合。与传统的基于像素的离散表示不同,MINR学习图像的连续函数表示,从而提高了模型的鲁棒性和泛化能力。这种方法使得模型能够更好地处理不同的掩码策略和分布外数据,克服了传统掩码自编码器的局限性。
关键设计:MINR的关键设计包括:1. 隐式神经表示网络结构:使用多层感知机(MLP)作为隐式神经表示网络,将坐标映射到像素值。2. 掩码策略:采用随机掩码策略,但模型对不同的掩码比例和模式具有鲁棒性。3. 损失函数:使用均方误差(MSE)作为重建损失函数,衡量预测像素值与原始像素值之间的差异。4. 坐标归一化:将图像坐标归一化到[-1, 1]范围内,以提高训练的稳定性和收敛速度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MINR在同分布图像重建任务上优于MAE,在异分布图像重建任务上性能提升更为显著。例如,在ImageNet数据集上,MINR在不同掩码比例下均取得了比MAE更好的结果。此外,MINR在模型复杂度方面也具有优势,参数量小于MAE,更易于部署和应用。
🎯 应用场景
MINR框架具有广泛的应用前景,包括图像修复、图像生成、图像压缩和图像超分辨率等。其鲁棒性和泛化能力使其在医学图像分析、遥感图像处理和自动驾驶等领域具有潜在的应用价值。此外,MINR还可以作为一种通用的自监督学习框架,用于预训练各种视觉模型。
📄 摘要(原文)
Self-supervised learning methods like masked autoencoders (MAE) have shown significant promise in learning robust feature representations, particularly in image reconstruction-based pretraining task. However, their performance is often strongly dependent on the masking strategies used during training and can degrade when applied to out-of-distribution data. To address these limitations, we introduce the masked implicit neural representations (MINR) framework that synergizes implicit neural representations with masked image modeling. MINR learns a continuous function to represent images, enabling more robust and generalizable reconstructions irrespective of masking strategies. Our experiments demonstrate that MINR not only outperforms MAE in in-domain scenarios but also in out-of-distribution settings, while reducing model complexity. The versatility of MINR extends to various self-supervised learning applications, confirming its utility as a robust and efficient alternative to existing frameworks.