UFV-Splatter: Pose-Free Feed-Forward 3D Gaussian Splatting Adapted to Unfavorable Views
作者: Yuki Fujimura, Takahiro Kushida, Kazuya Kitano, Takuya Funatomi, Yasuhiro Mukaigawa
分类: cs.CV
发布日期: 2025-07-30 (更新: 2025-08-06)
备注: Project page: https://yfujimura.github.io/UFV-Splatter_page/
💡 一句话要点
UFV-Splatter:用于不利视角的三维高斯溅射快速前馈方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 三维高斯溅射 不利视角 前馈网络 低秩自适应 视角自适应
📋 核心要点
- 现有前馈3DGS方法依赖于有利视角,限制了其在真实场景中处理未知相机姿态物体的能力。
- UFV-Splatter通过引入自适应框架,利用LoRA和高斯适配器,使预训练模型能处理不利视角。
- 实验表明,该方法在合成和真实数据集上均有效,能够处理不利视角下的三维重建任务。
📝 摘要(中文)
本文提出了一种无需姿态、快速前馈的三维高斯溅射(3DGS)框架,旨在处理不利的输入视角。训练前馈方法的常见渲染设置是将三维物体置于世界坐标原点,并从指向原点的相机进行渲染——即从有利视角进行渲染,这限制了这些模型在涉及变化和未知相机姿态的真实场景中的适用性。为了克服这一限制,我们引入了一种新的自适应框架,使预训练的无姿态前馈3DGS模型能够处理不利视角。我们通过将重新居中的图像输入到预训练模型中,并使用低秩自适应(LoRA)层进行增强,从而利用从有利图像中学习到的先验知识。我们进一步提出了一个高斯适配器模块,以增强从重新居中的输入中导出的高斯几何一致性,以及一种高斯对齐方法,以渲染用于训练的精确目标视图。此外,我们还引入了一种新的训练策略,该策略利用仅由有利图像组成的现成数据集。在来自Google扫描对象数据集的合成图像和来自OmniObject3D数据集的真实图像上的实验结果验证了我们的方法在处理不利输入视角方面的有效性。
🔬 方法详解
问题定义:现有基于前馈网络的三维高斯溅射方法通常需要在有利视角下进行训练,即相机指向物体中心。这限制了它们在实际应用中的泛化能力,因为真实场景中相机姿态是任意的,可能存在不利视角,导致重建质量下降。因此,需要一种方法能够使前馈3DGS模型适应不利视角。
核心思路:本文的核心思路是利用在有利视角下预训练的模型所学习到的先验知识,通过对输入图像进行重新居中,并结合低秩自适应(LoRA)和高斯适配器模块,使模型能够适应不利视角。通过这种方式,模型可以在不需要重新训练整个网络的情况下,快速适应新的视角。
技术框架:UFV-Splatter的整体框架包括以下几个主要模块: 1. 图像重居中:将输入图像进行变换,使其视角尽可能接近有利视角。 2. LoRA适配:在预训练的3DGS模型中加入LoRA层,用于学习视角变换带来的细微调整。 3. 高斯适配器:增强从重居中输入中导出的高斯几何一致性,提高重建质量。 4. 高斯对齐:使用高斯对齐方法渲染精确的目标视图,用于训练。 5. 训练策略:使用仅包含有利图像的现成数据集进行训练。
关键创新:该方法最重要的创新点在于提出了一种自适应框架,能够使预训练的无姿态前馈3DGS模型处理不利视角。通过结合图像重居中、LoRA适配和高斯适配器,该方法能够在不重新训练整个网络的情况下,快速适应新的视角,提高了模型的泛化能力。
关键设计: * LoRA层:在预训练模型的关键层中插入LoRA层,通过少量参数调整来适应新的视角。 * 高斯适配器模块:设计专门的模块来增强高斯分布的几何一致性,例如通过引入正则化项来约束高斯分布的形状。 * 高斯对齐方法:设计损失函数,使渲染出的高斯分布与目标视图对齐,例如使用L2损失或感知损失。 * 训练数据集:使用现成的、仅包含有利图像的数据集进行训练,避免了手动标注或生成不利视角数据的麻烦。
🖼️ 关键图片

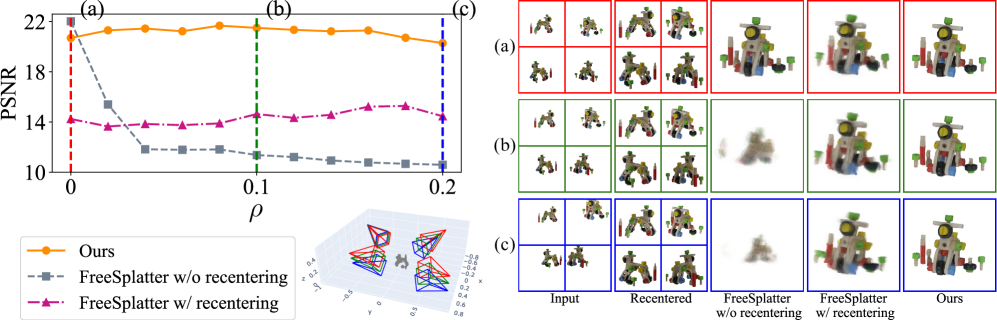

📊 实验亮点
实验结果表明,UFV-Splatter在处理不利视角方面表现出色。在Google Scanned Objects数据集和OmniObject3D数据集上,该方法能够有效地重建三维模型,并且在不利视角下的重建质量明显优于现有方法。具体性能数据未知,但论文强调了该方法在处理不利视角方面的有效性。
🎯 应用场景
UFV-Splatter技术可应用于三维重建、虚拟现实、增强现实等领域。例如,在机器人导航中,机器人可以利用该技术从任意视角重建周围环境的三维模型,从而更好地进行路径规划和避障。在电商领域,该技术可以用于生成商品的3D模型,方便用户从不同角度查看商品。
📄 摘要(原文)
This paper presents a pose-free, feed-forward 3D Gaussian Splatting (3DGS) framework designed to handle unfavorable input views. A common rendering setup for training feed-forward approaches places a 3D object at the world origin and renders it from cameras pointed toward the origin -- i.e., from favorable views, limiting the applicability of these models to real-world scenarios involving varying and unknown camera poses. To overcome this limitation, we introduce a novel adaptation framework that enables pretrained pose-free feed-forward 3DGS models to handle unfavorable views. We leverage priors learned from favorable images by feeding recentered images into a pretrained model augmented with low-rank adaptation (LoRA) layers. We further propose a Gaussian adapter module to enhance the geometric consistency of the Gaussians derived from the recentered inputs, along with a Gaussian alignment method to render accurate target views for training. Additionally, we introduce a new training strategy that utilizes an off-the-shelf dataset composed solely of favorable images. Experimental results on both synthetic images from the Google Scanned Objects dataset and real images from the OmniObject3D dataset validate the effectiveness of our method in handling unfavorable input views.