Ov3R: Open-Vocabulary Semantic 3D Reconstruction from RGB Videos
作者: Ziren Gong, Xiaohan Li, Fabio Tosi, Jiawei Han, Stefano Mattoccia, Jianfei Cai, Matteo Poggi
分类: cs.CV
发布日期: 2025-07-29 (更新: 2025-12-02)
💡 一句话要点
Ov3R:基于RGB视频的开放词汇语义3D重建框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 语义分割 开放词汇 CLIP 空间人工智能
📋 核心要点
- 现有3D重建方法缺乏对场景语义信息的有效利用,难以实现细粒度的语义理解和开放词汇的识别。
- Ov3R框架通过将CLIP的语义信息直接融入3D重建过程,实现了几何结构和语义信息的全局一致性。
- 实验结果表明,Ov3R在稠密3D重建和开放词汇3D分割任务上均达到了当前最佳水平。
📝 摘要(中文)
本文提出了Ov3R,一个用于从RGB视频流中进行开放词汇语义3D重建的新框架,旨在推进空间人工智能(Spatial AI)的发展。该系统包含两个关键组件:CLIP3R,一个CLIP驱动的3D重建模块,用于从重叠的视频片段中预测稠密点云图,同时嵌入对象级别的语义信息;以及2D-3D OVS,一个2D-3D开放词汇语义模块,通过学习融合了空间、几何和语义线索的描述符,将2D特征提升到3D空间。与现有方法不同,Ov3R直接将CLIP语义融入重建过程,从而实现全局一致的几何结构和精细的语义对齐。该框架在稠密3D重建和开放词汇3D分割方面均取得了最先进的性能,标志着朝着实时、语义感知的空间人工智能迈出了一步。
🔬 方法详解
问题定义:现有3D重建方法通常依赖于预定义的类别标签,难以处理开放词汇场景下的语义分割任务。此外,将2D语义信息提升到3D空间时,容易出现几何和语义不一致的问题。因此,如何实现开放词汇场景下的精确3D重建和语义分割是一个关键挑战。
核心思路:Ov3R的核心思路是将CLIP的强大语义表示能力融入到3D重建过程中。通过CLIP,模型可以理解和区分各种物体,即使这些物体在训练数据中没有明确标注。同时,通过融合空间、几何和语义信息,确保2D到3D的特征提升过程中的一致性。
技术框架:Ov3R框架包含两个主要模块:CLIP3R和2D-3D OVS。CLIP3R模块负责从RGB视频片段中重建稠密点云,并嵌入对象级别的语义信息。该模块利用CLIP的图像编码器提取图像特征,并将其与3D几何信息融合,生成带有语义信息的3D点云。2D-3D OVS模块则负责将2D特征提升到3D空间,通过学习融合了空间、几何和语义线索的描述符,实现2D和3D特征的对齐。
关键创新:Ov3R的关键创新在于直接将CLIP语义融入重建过程,从而实现全局一致的几何结构和精细的语义对齐。与以往方法相比,Ov3R不再依赖于预定义的类别标签,而是能够利用CLIP的开放词汇能力,识别和分割各种物体。此外,2D-3D OVS模块通过学习融合了空间、几何和语义线索的描述符,有效地解决了2D到3D特征提升过程中的不一致性问题。
关键设计:CLIP3R模块使用CLIP的图像编码器提取图像特征,并将其与深度信息融合,生成带有语义信息的3D点云。2D-3D OVS模块使用对比学习的方式训练,目标是学习到能够区分不同物体和场景的描述符。损失函数的设计考虑了空间、几何和语义信息的一致性,以确保2D和3D特征的对齐。
🖼️ 关键图片

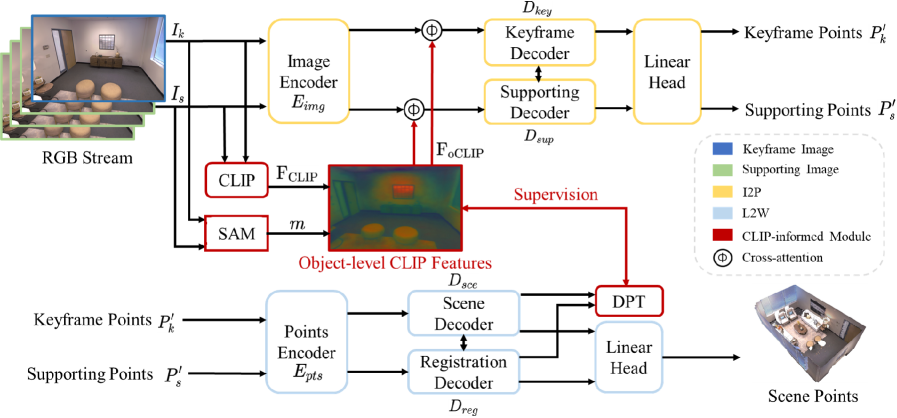

📊 实验亮点
Ov3R在ScanNet数据集上进行了实验,并在稠密3D重建和开放词汇3D分割任务上均取得了最先进的性能。具体而言,Ov3R在开放词汇3D分割任务上的性能显著优于现有方法,表明其能够有效地利用CLIP的语义信息。此外,实验结果还表明,Ov3R能够生成全局一致的几何结构和精细的语义对齐,从而提高了3D重建的质量。
🎯 应用场景
Ov3R框架具有广泛的应用前景,例如机器人导航、增强现实、虚拟现实、城市建模等。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在增强现实和虚拟现实领域,Ov3R可以用于创建更逼真的3D场景,并提供更丰富的语义信息。此外,Ov3R还可以用于城市建模,帮助城市规划者更好地了解城市结构和功能。
📄 摘要(原文)
We present Ov3R, a novel framework for open-vocabulary semantic 3D reconstruction from RGB video streams, designed to advance Spatial AI. The system features two key components: CLIP3R, a CLIP-informed 3D reconstruction module that predicts dense point maps from overlapping clips while embedding object-level semantics; and 2D-3D OVS, a 2D-3D open-vocabulary semantic module that lifts 2D features into 3D by learning fused descriptors integrating spatial, geometric, and semantic cues. Unlike prior methods, Ov3R incorporates CLIP semantics directly into the reconstruction process, enabling globally consistent geometry and fine-grained semantic alignment. Our framework achieves state-of-the-art performance in both dense 3D reconstruction and open-vocabulary 3D segmentation, marking a step forward toward real-time, semantics-aware Spatial AI.