EIFNet: Leveraging Event-Image Fusion for Robust Semantic Segmentation
作者: Zhijiang Li, Haoran He
分类: cs.CV
发布日期: 2025-07-29
💡 一句话要点
EIFNet:利用事件-图像融合实现鲁棒的语义分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 事件相机 语义分割 多模态融合 特征提取 注意力机制
📋 核心要点
- 事件语义分割面临从稀疏噪声事件流中提取可靠特征,并与图像数据有效融合的挑战。
- EIFNet通过自适应事件特征细化、模态自适应重校准和多头注意力门控融合来解决上述问题。
- 实验表明,EIFNet在DDD17-Semantic和DSEC-Semantic数据集上取得了最先进的性能。
📝 摘要(中文)
基于事件的语义分割旨在探索事件相机的潜力,它提供高动态范围和精细的时间分辨率,以在具有挑战性的环境中实现鲁棒的场景理解。尽管有这些优点,但由于两个主要挑战,这项任务仍然很困难:从稀疏和嘈杂的事件流中提取可靠的特征,以及有效地将它们与结构和表示不同的密集、语义丰富的图像数据融合。为了解决这些问题,我们提出了EIFNet,一个多模态融合网络,它结合了事件和基于帧的输入的优势。该网络包括一个自适应事件特征细化模块(AEFRM),通过多尺度活动建模和空间注意力来改进事件表示。此外,我们引入了一个模态自适应重校准模块(MARM)和一个多头注意力门控融合模块(MGFM),它们使用注意力机制和门控融合策略来对齐和整合跨模态的特征。在DDD17-Semantic和DSEC-Semantic数据集上的实验表明,EIFNet实现了最先进的性能,证明了其在基于事件的语义分割中的有效性。
🔬 方法详解
问题定义:事件语义分割旨在利用事件相机的高动态范围和时间分辨率优势,在复杂环境中实现鲁棒的场景理解。然而,事件数据通常稀疏且噪声大,难以提取可靠特征。此外,如何有效地将事件数据与图像数据融合,也是一个挑战,因为它们在结构和表示上存在差异。现有方法在处理事件数据的噪声和稀疏性,以及有效融合多模态信息方面存在不足。
核心思路:EIFNet的核心思路是设计一个多模态融合网络,充分利用事件数据和图像数据的互补信息。通过自适应的特征提取和融合机制,提高事件特征的质量,并有效地将事件特征与图像特征对齐和融合。这样可以克服事件数据的噪声和稀疏性,并充分利用图像数据的语义信息,从而提高语义分割的准确性和鲁棒性。
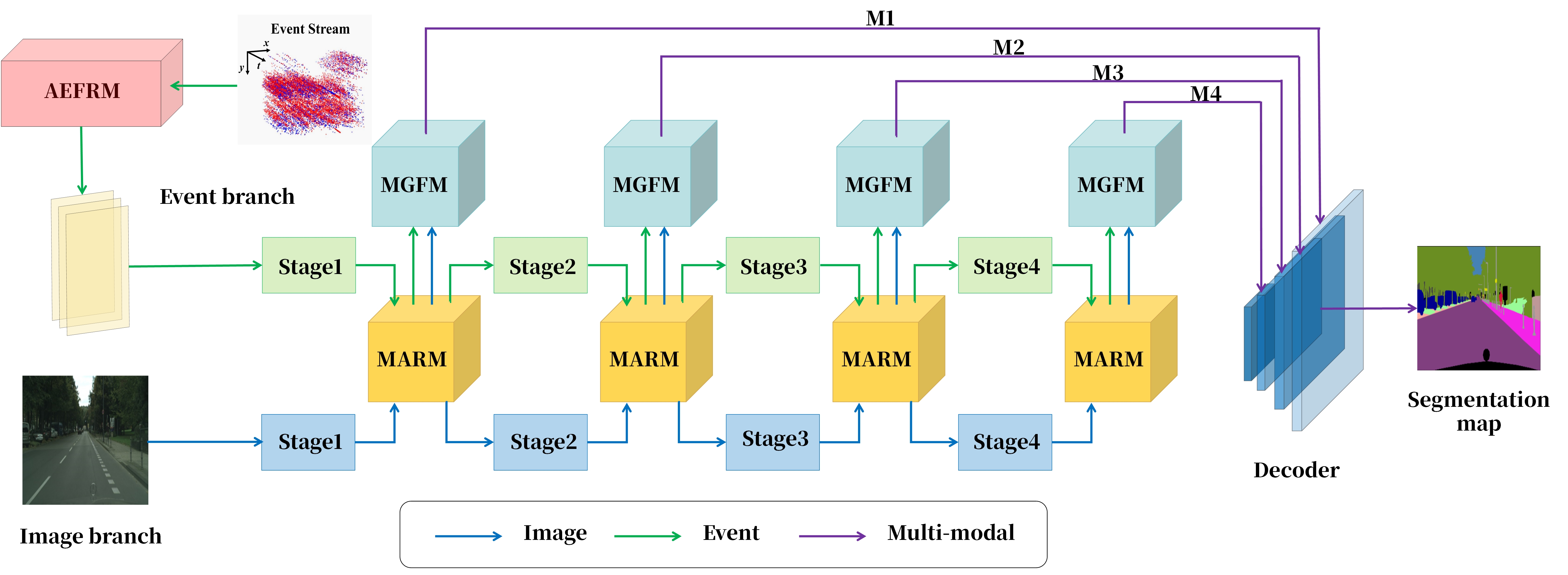
技术框架:EIFNet的整体架构包含以下几个主要模块:1) 事件特征提取模块:用于从事件流中提取特征。2) 自适应事件特征细化模块(AEFRM):用于提高事件特征的质量,减少噪声的影响。3) 图像特征提取模块:用于从图像数据中提取特征。4) 模态自适应重校准模块(MARM):用于对齐不同模态的特征。5) 多头注意力门控融合模块(MGFM):用于融合事件特征和图像特征。最后,通过一个分割头进行语义分割预测。
关键创新:EIFNet的关键创新在于以下几个方面:1) 提出了自适应事件特征细化模块(AEFRM),通过多尺度活动建模和空间注意力机制,有效地提高了事件特征的质量。2) 提出了模态自适应重校准模块(MARM),通过注意力机制,对齐了不同模态的特征,减少了模态差异带来的影响。3) 提出了多头注意力门控融合模块(MGFM),通过门控机制,自适应地融合了事件特征和图像特征,提高了融合的效率和准确性。
关键设计:AEFRM采用了多尺度卷积来捕捉不同尺度的事件活动信息,并使用空间注意力机制来关注重要的空间区域。MARM使用注意力机制来学习不同模态特征的重要性,并进行重校准。MGFM使用多头注意力机制来捕捉不同模态特征之间的关系,并使用门控机制来控制不同模态特征的贡献。损失函数方面,使用了交叉熵损失函数来优化语义分割结果。具体的网络结构参数和训练策略未知。
🖼️ 关键图片

📊 实验亮点
EIFNet在DDD17-Semantic和DSEC-Semantic数据集上取得了state-of-the-art的性能。具体提升幅度未知,但结果表明,EIFNet提出的自适应事件特征细化模块(AEFRM)、模态自适应重校准模块(MARM)和多头注意力门控融合模块(MGFM)能够有效地提高事件语义分割的准确性和鲁棒性。
🎯 应用场景
EIFNet在自动驾驶、机器人导航、安防监控等领域具有广泛的应用前景。在这些场景中,光照条件可能较差,传统的相机难以获得清晰的图像,而事件相机可以提供高动态范围和时间分辨率的信息,从而提高系统的鲁棒性和可靠性。EIFNet通过融合事件数据和图像数据,可以进一步提高场景理解的准确性和鲁棒性,为这些应用提供更可靠的技术支持。
📄 摘要(原文)
Event-based semantic segmentation explores the potential of event cameras, which offer high dynamic range and fine temporal resolution, to achieve robust scene understanding in challenging environments. Despite these advantages, the task remains difficult due to two main challenges: extracting reliable features from sparse and noisy event streams, and effectively fusing them with dense, semantically rich image data that differ in structure and representation. To address these issues, we propose EIFNet, a multi-modal fusion network that combines the strengths of both event and frame-based inputs. The network includes an Adaptive Event Feature Refinement Module (AEFRM), which improves event representations through multi-scale activity modeling and spatial attention. In addition, we introduce a Modality-Adaptive Recalibration Module (MARM) and a Multi-Head Attention Gated Fusion Module (MGFM), which align and integrate features across modalities using attention mechanisms and gated fusion strategies. Experiments on DDD17-Semantic and DSEC-Semantic datasets show that EIFNet achieves state-of-the-art performance, demonstrating its effectiveness in event-based semantic segmentation.