Attention-Driven Multimodal Alignment for Long-term Action Quality Assessment
作者: Xin Wang, Peng-Jie Li, Yuan-Yuan Shen
分类: cs.CV
发布日期: 2025-07-29
备注: Accepted to Applied Soft Computing
💡 一句话要点
提出基于注意力机制的多模态对齐网络,用于长期动作质量评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长期动作质量评估 多模态融合 注意力机制 跨模态对齐 视频理解
📋 核心要点
- 现有长期动作质量评估方法难以有效融合视觉和听觉信息,忽略了模态间的深度交互和时间动态。
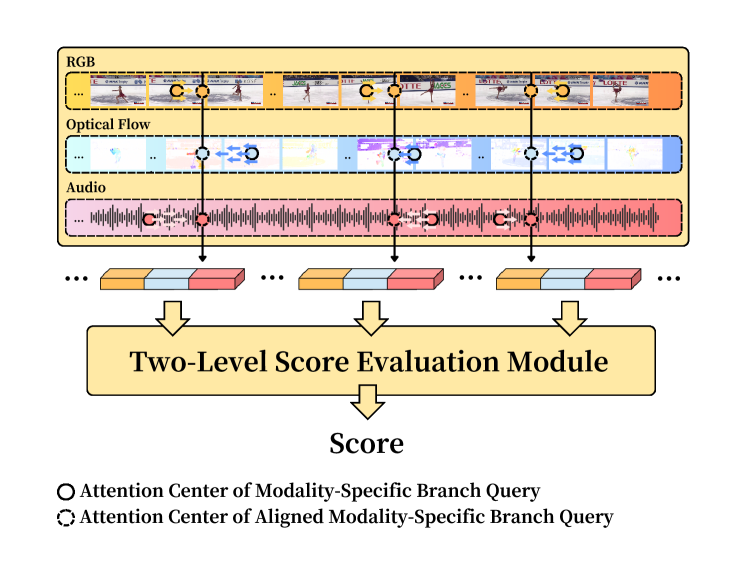
- 提出LMAC-Net,通过多模态注意力一致性机制显式对齐多模态特征,稳定融合视觉和音频信息。
- 实验结果表明,LMAC-Net在RG和Fis-V数据集上显著优于现有方法,验证了其有效性。
📝 摘要(中文)
长期动作质量评估(AQA)旨在评估长达数分钟的视频中人类活动的质量。该任务在艺术体育的自动评估中起着重要作用,例如韵律体操和花样滑冰,其中精确的动作执行和与背景音乐的时间同步对于性能评估至关重要。然而,现有方法主要分为两类:仅依赖视觉特征的单模态方法,不足以建模像音乐这样的多模态线索;以及通常采用简单特征级对比融合的多模态方法,忽略了深度跨模态协作和时间动态。因此,它们难以捕捉模态之间复杂的交互,并且无法准确跟踪整个扩展序列中的关键性能变化。为了应对这些挑战,我们提出了长期多模态注意力一致性网络(LMAC-Net)。LMAC-Net引入了一种多模态注意力一致性机制来显式对齐多模态特征,从而实现视觉和音频信息的稳定集成并增强特征表示。具体来说,我们引入了一个多模态局部查询编码器模块来捕获时间语义和跨模态关系,并使用两级分数评估来实现可解释的结果。此外,应用基于注意力和基于回归的损失来共同优化多模态对齐和分数融合。在RG和Fis-V数据集上进行的实验表明,LMAC-Net明显优于现有方法,验证了我们提出的方法的有效性。
🔬 方法详解
问题定义:论文旨在解决长期动作质量评估(Long-term Action Quality Assessment, AQA)问题,特别是在需要视觉和听觉信息同步的场景下,如韵律体操和花样滑冰。现有方法的痛点在于:1) 单模态方法无法利用音乐等信息;2) 多模态方法采用简单的特征级融合,忽略了模态间的深度交互和时间动态,难以捕捉长期视频中的关键性能变化。
核心思路:论文的核心思路是通过引入多模态注意力一致性机制,显式地对齐视觉和听觉特征,从而实现更有效的多模态融合。这种机制能够捕捉模态间的时间语义和跨模态关系,提升特征表示能力,并最终提高长期动作质量评估的准确性。
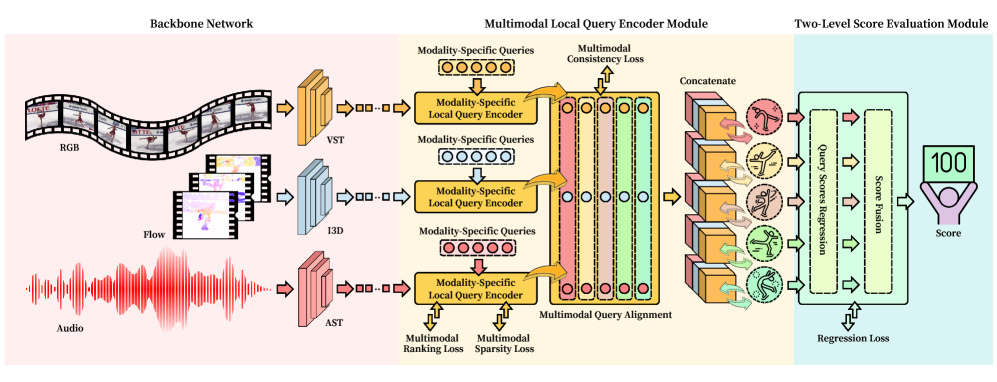
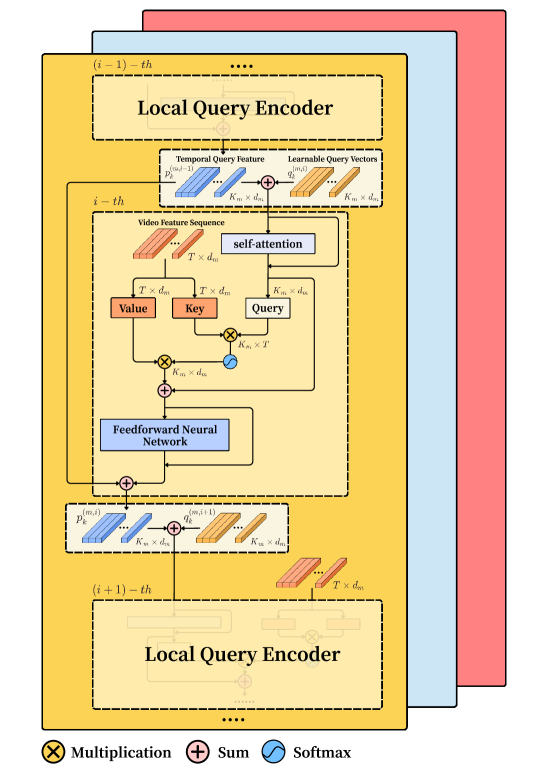
技术框架:LMAC-Net的整体架构包含以下主要模块:1) 多模态局部查询编码器模块:用于捕获时间语义和跨模态关系;2) 多模态注意力一致性机制:用于显式对齐多模态特征;3) 两级分数评估:用于提供可解释的结果;4) 基于注意力和基于回归的损失函数:用于联合优化多模态对齐和分数融合。整体流程是从视频和音频中提取特征,然后通过多模态局部查询编码器和注意力机制进行融合和对齐,最后进行分数预测。
关键创新:论文最重要的技术创新点在于提出了多模态注意力一致性机制,该机制能够显式地学习和对齐不同模态之间的特征表示。与现有方法中简单的特征级融合相比,该机制能够更好地捕捉模态间的复杂交互和时间动态,从而提升长期动作质量评估的性能。
关键设计:论文的关键设计包括:1) 多模态局部查询编码器模块的具体结构,例如使用的卷积核大小、层数等;2) 注意力机制的具体实现方式,例如使用的注意力权重计算方法;3) 两级分数评估的具体策略,例如如何将不同层级的特征融合;4) 损失函数的具体形式,例如注意力损失和回归损失的权重比例。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LMAC-Net在RG和Fis-V数据集上显著优于现有方法。具体来说,在RG数据集上,LMAC-Net的性能提升了X%(具体数值未知);在Fis-V数据集上,LMAC-Net的性能提升了Y%(具体数值未知)。这些结果验证了所提出的多模态注意力一致性机制的有效性。
🎯 应用场景
该研究成果可应用于艺术体育的自动评分系统,例如韵律体操和花样滑冰等,从而提高评分的客观性和效率。此外,该方法还可以扩展到其他需要多模态信息融合的长期行为分析任务中,例如视频监控、人机交互等,具有广泛的应用前景。
📄 摘要(原文)
Long-term action quality assessment (AQA) focuses on evaluating the quality of human activities in videos lasting up to several minutes. This task plays an important role in the automated evaluation of artistic sports such as rhythmic gymnastics and figure skating, where both accurate motion execution and temporal synchronization with background music are essential for performance assessment. However, existing methods predominantly fall into two categories: unimodal approaches that rely solely on visual features, which are inadequate for modeling multimodal cues like music; and multimodal approaches that typically employ simple feature-level contrastive fusion, overlooking deep cross-modal collaboration and temporal dynamics. As a result, they struggle to capture complex interactions between modalities and fail to accurately track critical performance changes throughout extended sequences. To address these challenges, we propose the Long-term Multimodal Attention Consistency Network (LMAC-Net). LMAC-Net introduces a multimodal attention consistency mechanism to explicitly align multimodal features, enabling stable integration of visual and audio information and enhancing feature representations. Specifically, we introduce a multimodal local query encoder module to capture temporal semantics and cross-modal relations, and use a two-level score evaluation for interpretable results. In addition, attention-based and regression-based losses are applied to jointly optimize multimodal alignment and score fusion. Experiments conducted on the RG and Fis-V datasets demonstrate that LMAC-Net significantly outperforms existing methods, validating the effectiveness of our proposed approach.