ArtSeek: Deep artwork understanding via multimodal in-context reasoning and late interaction retrieval
作者: Nicola Fanelli, Gennaro Vessio, Giovanna Castellano
分类: cs.CV
发布日期: 2025-07-29
🔗 代码/项目: GITHUB
💡 一句话要点
ArtSeek:通过多模态上下文推理和延迟交互检索实现深度艺术品理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 艺术品理解 多模态学习 检索增强生成 视觉问答 知识图谱 深度学习 上下文推理
📋 核心要点
- 现有数字化艺术品分析方法依赖外部知识链接,限制了其在缺乏此类信息的艺术品上的应用。
- ArtSeek利用多模态大语言模型和检索增强生成,仅通过图像输入即可实现艺术品的深度理解和分析。
- ArtSeek在风格分类和字幕生成等任务上取得了显著提升,证明了其在艺术品理解方面的有效性。
📝 摘要(中文)
分析数字化艺术品面临独特的挑战,不仅需要视觉解释,还需要对丰富的艺术、语境和历史知识有深刻的理解。我们介绍了ArtSeek,一个用于艺术分析的多模态框架,它结合了多模态大型语言模型和检索增强生成。与之前的工作不同,我们的流程仅依赖于图像输入,使其适用于大多数数字化馆藏中没有链接到Wikidata或Wikipedia的艺术品。ArtSeek集成了三个关键组件:一个基于延迟交互检索的智能多模态检索模块,一个用于预测艺术家、流派、风格、媒介和标签的对比多任务分类网络,以及一个通过Qwen2.5-VL中的上下文示例实现的代理推理策略,用于复杂的视觉问答和艺术品解释。该方法的核心是WikiFragments,一个维基百科规模的图像-文本片段数据集,旨在支持基于知识的多模态推理。我们的框架在多个基准测试中取得了最先进的结果,包括在风格分类方面比GraphCLIP提高了+8.4%的F1,在ArtPedia上的字幕生成方面提高了+7.1 BLEU@1。定性分析表明,ArtSeek可以解释视觉主题,推断历史背景,并检索相关知识,即使对于晦涩的作品也是如此。虽然专注于视觉艺术,但我们的方法可以推广到其他需要外部知识的领域,支持可扩展的多模态AI研究。数据集和源代码将在https://github.com/cilabuniba/artseek上公开。
🔬 方法详解
问题定义:论文旨在解决数字化艺术品理解问题,现有方法通常依赖于与艺术品相关的外部知识链接(如Wikidata或Wikipedia),这限制了它们在缺乏这些链接的艺术品上的应用。此外,现有方法在视觉问答和艺术品解释方面存在不足,难以进行深度推理和知识整合。
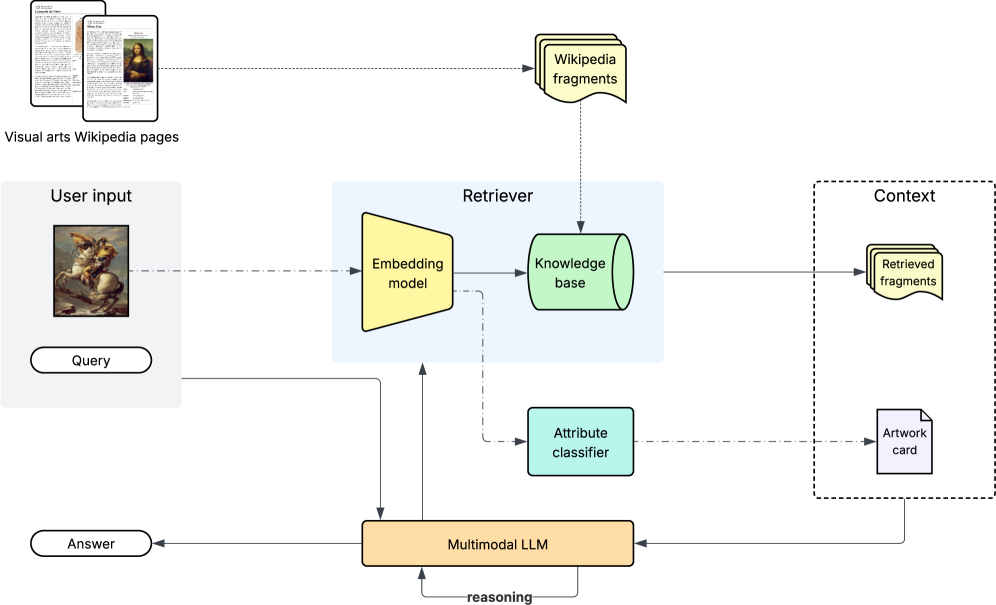
核心思路:ArtSeek的核心思路是利用多模态大语言模型(MLLM)和检索增强生成(RAG),仅通过图像输入即可实现艺术品的深度理解。通过构建一个大规模的图像-文本片段数据集(WikiFragments),并结合延迟交互检索模块,ArtSeek能够检索与艺术品相关的知识,并利用这些知识进行推理和解释。
技术框架:ArtSeek框架包含三个主要模块:1) 智能多模态检索模块:基于延迟交互检索,用于从WikiFragments数据集中检索与输入图像相关的知识片段。2) 对比多任务分类网络:用于预测艺术品的艺术家、流派、风格、媒介和标签。3) 代理推理策略:利用Qwen2.5-VL模型,通过上下文示例进行视觉问答和艺术品解释。整个流程是,首先输入艺术品图像,检索模块检索相关知识,分类网络进行初步分类,最后代理推理策略结合图像和检索到的知识进行深度推理和解释。
关键创新:ArtSeek的关键创新在于:1) 仅依赖图像输入,无需外部知识链接,扩展了适用范围。2) 提出了WikiFragments数据集,为知识驱动的多模态推理提供了支持。3) 采用了延迟交互检索模块,提高了检索的准确性和效率。4) 利用代理推理策略,实现了更复杂的视觉问答和艺术品解释。
关键设计:WikiFragments数据集包含从维基百科提取的图像-文本片段,用于知识检索。延迟交互检索模块采用多层感知机(MLP)对图像和文本特征进行融合,并计算相似度。对比多任务分类网络采用对比学习损失函数,以提高分类的准确性。代理推理策略使用Qwen2.5-VL模型,并通过上下文示例进行微调,以提高推理能力。具体的参数设置和网络结构在论文中有详细描述,此处未知。
🖼️ 关键图片


📊 实验亮点
ArtSeek在多个基准测试中取得了显著的性能提升。在风格分类方面,ArtSeek比GraphCLIP提高了+8.4%的F1。在ArtPedia上的字幕生成方面,ArtSeek提高了+7.1 BLEU@1。这些结果表明,ArtSeek在艺术品理解方面具有显著的优势。
🎯 应用场景
ArtSeek可应用于数字化博物馆、艺术品交易平台、艺术教育等领域。它可以帮助用户更好地理解艺术品,提供更丰富的艺术体验。此外,该方法还可以推广到其他需要外部知识的领域,如医学图像分析、遥感图像解译等,具有广泛的应用前景。
📄 摘要(原文)
Analyzing digitized artworks presents unique challenges, requiring not only visual interpretation but also a deep understanding of rich artistic, contextual, and historical knowledge. We introduce ArtSeek, a multimodal framework for art analysis that combines multimodal large language models with retrieval-augmented generation. Unlike prior work, our pipeline relies only on image input, enabling applicability to artworks without links to Wikidata or Wikipedia-common in most digitized collections. ArtSeek integrates three key components: an intelligent multimodal retrieval module based on late interaction retrieval, a contrastive multitask classification network for predicting artist, genre, style, media, and tags, and an agentic reasoning strategy enabled through in-context examples for complex visual question answering and artwork explanation via Qwen2.5-VL. Central to this approach is WikiFragments, a Wikipedia-scale dataset of image-text fragments curated to support knowledge-grounded multimodal reasoning. Our framework achieves state-of-the-art results on multiple benchmarks, including a +8.4% F1 improvement in style classification over GraphCLIP and a +7.1 BLEU@1 gain in captioning on ArtPedia. Qualitative analyses show that ArtSeek can interpret visual motifs, infer historical context, and retrieve relevant knowledge, even for obscure works. Though focused on visual arts, our approach generalizes to other domains requiring external knowledge, supporting scalable multimodal AI research. Both the dataset and the source code will be made publicly available at https://github.com/cilabuniba/artseek.