CAPE: A CLIP-Aware Pointing Ensemble of Complementary Heatmap Cues for Embodied Reference Understanding
作者: Fevziye Irem Eyiokur, Dogucan Yaman, Hazım Kemal Ekenel, Alexander Waibel
分类: cs.CV
发布日期: 2025-07-29 (更新: 2025-12-11)
备注: Accepted by WACV 2026
💡 一句话要点
CAPE:结合CLIP感知的互补热图线索集成,用于具身引用理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身引用理解 多模态融合 指向手势识别 CLIP模型 热图回归
📋 核心要点
- 现有具身引用理解方法未能充分利用视觉指向线索进行消歧,限制了性能。
- 提出双模型框架,分别学习头到指尖和腕到指尖的指向方向,互补利用信息。
- 引入CLIP感知的指向集成模块,并结合辅助对象中心预测头,提升定位精度。
📝 摘要(中文)
本文研究具身引用理解,即预测场景中人物通过指向手势和语言所指的对象。这需要对文本、视觉指向线索和场景上下文进行多模态推理,但现有方法通常未能充分利用视觉消歧信号。我们还观察到,虽然指示对象通常与头到指尖的方向对齐,但在许多情况下,它与手腕到指尖的方向更紧密地对齐,使得单一直线假设过于局限。为了解决这个问题,我们提出了一个双模型框架,其中一个模型从头到指尖的方向学习,另一个从手腕到指尖的方向学习。我们引入了这些线的Gaussian射线热图表示,并将其用作输入,以提供强大的监督信号,鼓励模型更好地关注指向线索。为了融合它们的互补优势,我们提出了CLIP感知的指向集成模块,该模块执行由CLIP特征引导的混合集成。我们进一步结合了一个辅助对象中心预测头,以增强指示对象定位。我们在YouRefIt上验证了我们的方法,在0.25 IoU下实现了75.0 mAP,以及最先进的CLIP和C_D分数,并在未见过的CAESAR和ISL Pointing上展示了其通用性,在各个基准测试中表现出强大的性能。
🔬 方法详解
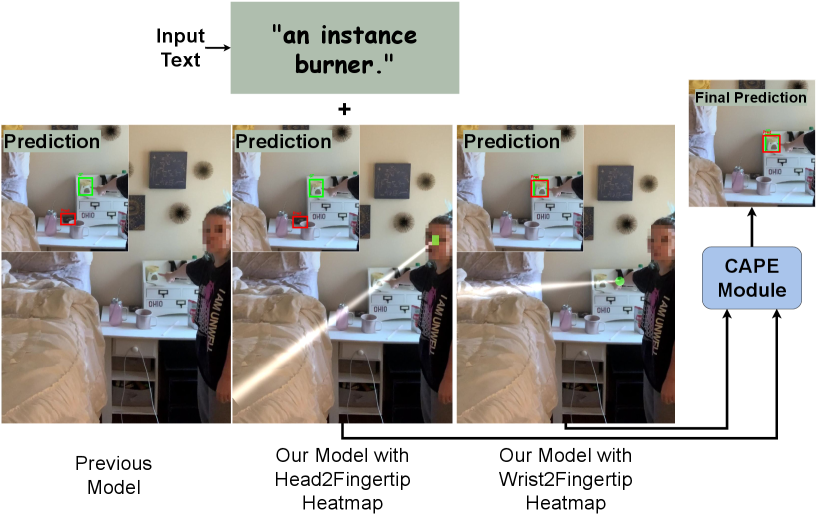
问题定义:具身引用理解任务旨在预测场景中人通过指向手势和语言所指的对象。现有方法通常依赖于单一直线假设(头到指尖),忽略了腕到指尖方向可能更准确的情况,并且未能充分利用视觉指向线索进行消歧,导致性能受限。
核心思路:论文的核心思路是利用双模型框架,分别学习头到指尖和腕到指尖两个方向的指向信息,并使用CLIP特征引导的集成模块融合两个模型的预测结果。这种方法能够更全面地捕捉指向手势的视觉信息,从而提高引用理解的准确性。
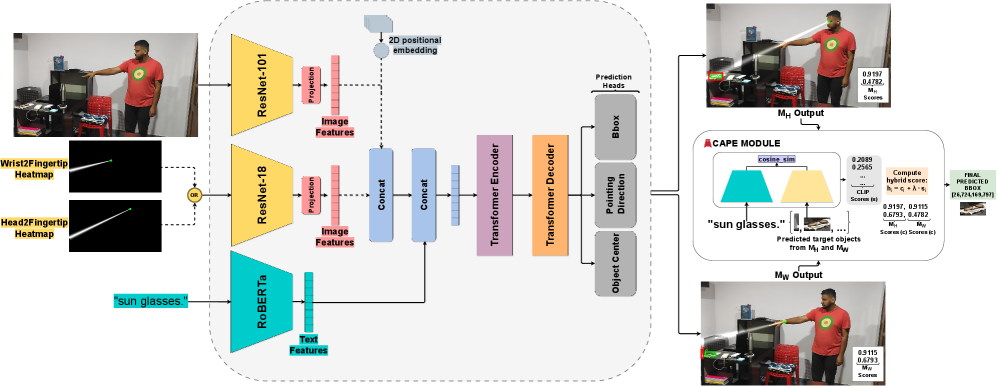
技术框架:整体框架包含两个并行的指向预测模型,分别以头到指尖和腕到指尖方向的Gaussian射线热图作为输入。每个模型预测一个指示对象的热图。然后,CLIP感知的指向集成模块利用CLIP特征对两个模型的预测结果进行加权融合。最后,结合一个辅助对象中心预测头,进一步提升定位精度。
关键创新:论文的关键创新在于:1) 提出了双模型框架,能够更全面地捕捉指向手势的视觉信息;2) 引入了CLIP感知的指向集成模块,利用CLIP特征动态地融合两个模型的预测结果,实现互补优势;3) 结合了辅助对象中心预测头,进一步提升定位精度。
关键设计:Gaussian射线热图的方差是一个重要的参数,需要根据数据集的特点进行调整。CLIP感知的指向集成模块使用一个小型神经网络来预测两个模型的权重,该网络的输入是CLIP特征。辅助对象中心预测头的损失函数与指示对象预测头的损失函数进行加权求和,权重需要根据实验结果进行调整。
🖼️ 关键图片

📊 实验亮点
在YouRefIt数据集上,该方法在0.25 IoU下实现了75.0 mAP,取得了state-of-the-art的CLIP和C_D分数。此外,该方法在未见过的CAESAR和ISL Pointing数据集上也表现出强大的泛化能力,证明了其鲁棒性。
🎯 应用场景
该研究成果可应用于人机交互、机器人导航、虚拟现实等领域。例如,在人机交互中,机器人可以根据人的指向手势和语言指令,准确理解人的意图,从而执行相应的任务。在虚拟现实中,用户可以通过指向手势与虚拟环境中的对象进行交互,提升沉浸感。
📄 摘要(原文)
We address Embodied Reference Understanding, the task of predicting the object a person in the scene refers to through pointing gesture and language. This requires multimodal reasoning over text, visual pointing cues, and scene context, yet existing methods often fail to fully exploit visual disambiguation signals. We also observe that while the referent often aligns with the head-to-fingertip direction, in many cases it aligns more closely with the wrist-to-fingertip direction, making a single-line assumption overly limiting. To address this, we propose a dual-model framework, where one model learns from the head-to-fingertip direction and the other from the wrist-to-fingertip direction. We introduce a Gaussian ray heatmap representation of these lines and use them as input to provide a strong supervisory signal that encourages the model to better attend to pointing cues. To fuse their complementary strengths, we present the CLIP-Aware Pointing Ensemble module, which performs a hybrid ensemble guided by CLIP features. We further incorporate an auxiliary object center prediction head to enhance referent localization. We validate our approach on YouRefIt, achieving 75.0 mAP at 0.25 IoU, alongside state-of-the-art CLIP and C_D scores, and demonstrate its generality on unseen CAESAR and ISL Pointing, showing robust performance across benchmarks.