AU-LLM: Micro-Expression Action Unit Detection via Enhanced LLM-Based Feature Fusion
作者: Zhishu Liu, Kaishen Yuan, Bo Zhao, Yong Xu, Zitong Yu
分类: cs.CV
发布日期: 2025-07-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出AU-LLM,首次利用LLM进行微表情动作单元检测,显著提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 微表情识别 动作单元检测 大型语言模型 视觉语言融合 情感计算
📋 核心要点
- 微表情AU检测面临数据稀缺和强度低的挑战,现有方法难以有效捕捉细微的面部肌肉运动。
- AU-LLM利用LLM的推理能力,通过增强融合投影器(EFP)弥合视觉-语言语义鸿沟,实现更精确的AU检测。
- 在CASME II和SAMM数据集上的实验表明,AU-LLM在LOSO和跨域协议下均取得了SOTA结果,验证了其有效性。
📝 摘要(中文)
微表情动作单元(AU)的检测是情感计算中的一项艰巨挑战,对于解码微妙、非自愿的人类情绪至关重要。大型语言模型(LLM)展现出深刻的推理能力,但其在微表情AU检测这一细粒度、低强度领域的应用仍未被探索。本文通过引入AU-LLM,首次使用LLM在具有微妙强度和数据稀缺性的微表情数据集上检测AU,开创了这一方向。我们特别解决了关键的视觉-语言语义鸿沟,提出了增强融合投影器(EFP)。EFP采用多层感知器(MLP)将来自专用3D-CNN骨干网络的中层(局部纹理)和高层(全局语义)视觉特征智能地融合到单个信息密集的token中。这种紧凑的表示有效地使LLM能够对微妙的面部肌肉运动进行细致的推理。通过在基准CASME II和SAMM数据集上进行广泛的评估,包括严格的留一受试者(LOSO)和跨域协议,AU-LLM建立了一个新的最先进水平,验证了基于LLM的推理在微表情分析中的巨大潜力和鲁棒性。
🔬 方法详解
问题定义:微表情动作单元(AU)检测旨在识别面部细微的肌肉运动,对于理解人类真实情感至关重要。然而,微表情通常具有持续时间短、强度低的特点,且现有数据集规模有限,导致传统方法难以有效提取和识别这些细微的特征。现有方法主要依赖于手工特征或浅层机器学习模型,难以充分利用上下文信息进行推理,泛化能力较弱。
核心思路:AU-LLM的核心思路是利用大型语言模型(LLM)强大的推理能力,将视觉特征转化为语言token,从而实现对微表情AU的精确检测。通过设计增强融合投影器(EFP),弥合视觉特征和语言模型之间的语义鸿沟,使得LLM能够更好地理解和推理面部肌肉运动。
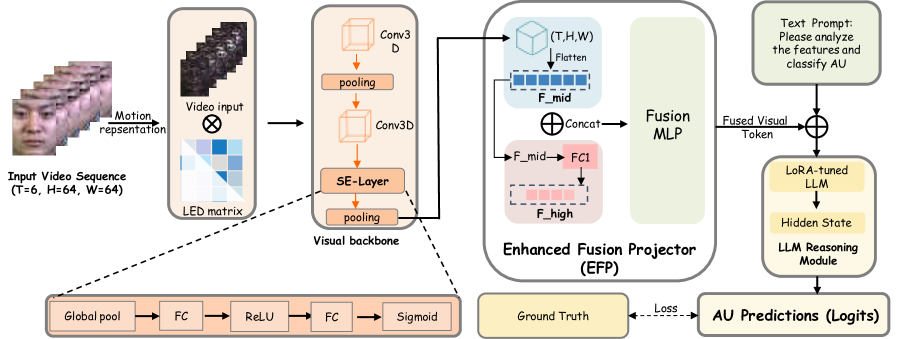
技术框架:AU-LLM的整体框架包括以下几个主要模块:1) 3D-CNN骨干网络:用于提取视频帧中的视觉特征,包括中层(局部纹理)和高层(全局语义)特征。2) 增强融合投影器(EFP):将3D-CNN提取的视觉特征融合为单个信息密集的token,作为LLM的输入。3) 大型语言模型(LLM):对EFP输出的token进行推理,预测每个AU的存在与否。整个流程是先通过3D-CNN提取视觉特征,然后通过EFP进行特征融合和降维,最后输入到LLM中进行分类。
关键创新:AU-LLM最重要的技术创新点在于首次将LLM应用于微表情AU检测,并提出了增强融合投影器(EFP)来解决视觉-语言语义鸿沟问题。与现有方法相比,AU-LLM能够更好地利用上下文信息进行推理,从而提高AU检测的准确性和鲁棒性。EFP的设计使得LLM能够专注于理解和推理面部肌肉运动,而不是处理原始的视觉像素信息。
关键设计:EFP采用多层感知器(MLP)来实现特征融合和降维。具体来说,EFP接收来自3D-CNN的中层和高层视觉特征,并将它们concatenate在一起。然后,MLP将concatenate后的特征映射到单个token,该token包含关于面部肌肉运动的丰富信息。损失函数采用标准的交叉熵损失函数,用于训练LLM预测每个AU的存在与否。3D-CNN骨干网络采用ResNet3D或类似的结构,具体参数设置根据数据集大小和计算资源进行调整。
🖼️ 关键图片
📊 实验亮点
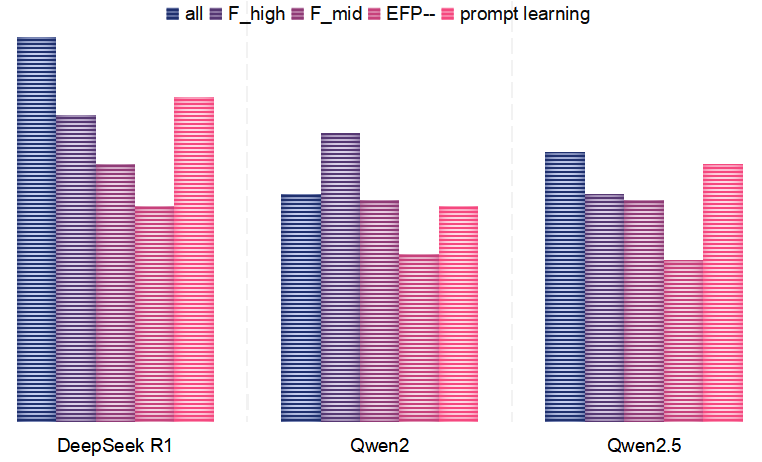
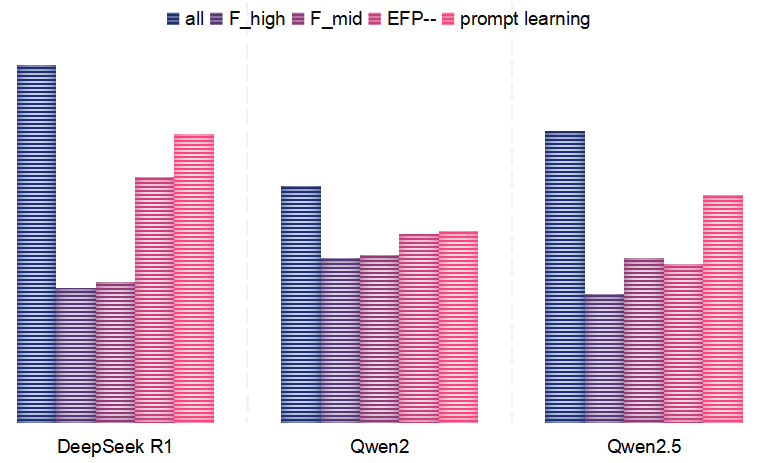
AU-LLM在CASME II和SAMM数据集上取得了显著的性能提升。在LOSO协议下,AU-LLM在CASME II数据集上实现了平均F1-score 65.2%,在SAMM数据集上实现了68.9%,均超过了现有SOTA方法。跨域实验也表明,AU-LLM具有较强的泛化能力,能够在不同的数据集上保持较高的性能。
🎯 应用场景
AU-LLM在情感计算、心理学研究、安全监控等领域具有广泛的应用前景。例如,可以用于识别犯罪嫌疑人的隐藏情绪,评估患者的心理状态,或在人机交互中提供更自然的情感反馈。未来,该研究可以扩展到其他细粒度的情感分析任务,如面部表情识别、语音情感识别等。
📄 摘要(原文)
The detection of micro-expression Action Units (AUs) is a formidable challenge in affective computing, pivotal for decoding subtle, involuntary human emotions. While Large Language Models (LLMs) demonstrate profound reasoning abilities, their application to the fine-grained, low-intensity domain of micro-expression AU detection remains unexplored. This paper pioneers this direction by introducing \textbf{AU-LLM}, a novel framework that for the first time uses LLM to detect AUs in micro-expression datasets with subtle intensities and the scarcity of data. We specifically address the critical vision-language semantic gap, the \textbf{Enhanced Fusion Projector (EFP)}. The EFP employs a Multi-Layer Perceptron (MLP) to intelligently fuse mid-level (local texture) and high-level (global semantics) visual features from a specialized 3D-CNN backbone into a single, information-dense token. This compact representation effectively empowers the LLM to perform nuanced reasoning over subtle facial muscle movements.Through extensive evaluations on the benchmark CASME II and SAMM datasets, including stringent Leave-One-Subject-Out (LOSO) and cross-domain protocols, AU-LLM establishes a new state-of-the-art, validating the significant potential and robustness of LLM-based reasoning for micro-expression analysis. The codes are available at https://github.com/ZS-liu-JLU/AU-LLMs.